单片机与嵌入式
51单片机的寻址方式
51单片机的汇编指令系统
51汇编语言的伪指令
51汇编语言程序结构与程序示例
Keil C51程序设计
Keil C51的库函数
PIC单片机的基本结构
PIC单片机的汇编语言指令
PIC单片机的C语言编程
ATmega16单片机基本结构
ATmega16单片机的汇编语言
ATmega128单片机的结构
STM32单片机基础
使用STM32CubeMX开发STM32单片机
uC/OS-II嵌入式操作系统
uC/OS-II在STM32F10xx上的移植
FreeRTOS系统介绍
Linux系统介绍
Linux系统编程
嵌入式Linux编程
1. Linux系统开发环境:
Linux发行版大体分为商业公司维护和社区维护两类,商业公司维护的以RedHat为代表,包括RHEL、CentOS、Fedora等,社区维护的以Debian为代表,还有Ubuntu等。其中Ubuntu是桌面版本,对硬件支持非常全面,可在www.ubuntu.com官网上下载,国内有网易镜像http://mirrors.163.com和阿里云镜像http://mirrors.aliyun.com,软件源可以使用mirrors.tuna. Tsinghua.edu.cn。
虚拟机是指通过软件模拟的具有完整硬件系统功能、能运行在一个完全隔离环境中的完整计算机系统。进入虚拟机后,所有操作都是在这个独立的虚拟空间中进行的,不会对虚拟机所在的主机系统产生任何影响,而且能够在主机系统与虚拟机之间灵活切换。
主流的虚拟机有Virtual Box、Microsoft Hyper-V、VMware Workstation等。VMware Workstation兼容性好、CPU占用率低,可以同时运行Linux、Dos、Windows、UNIX等操作系统,不过为收费软件,购买许可密钥才能长期使用。
Linux开发中,最广泛使用的是C语言,编辑工具有Vi、Vim、JOE、Emacs,编译工具一般用gcc,调试工具用GDB,构建工具使用make,开发软件包主要有GNU C Library、C Standard Library、GTK、Qt等,项目管理工具可使用CVS、SVN、Git。
1) Vi编辑器:
Linux系统支持的编辑器很多,图形模式的有gedit、Kate、OpenOffice,文本模式的有Vi、Emacs等。Vi是一种全屏幕文本编辑器,有插入式模式和命令模式及末行模式。
① 工作模式及切换:
· 插入模式:也称编辑模式,屏幕最后一行将出现insert字样,用户的按键操作在界面中显示为文档内容。
· 命令模式:用户按键操作在界面中没有任何字符显示,直接转换为对文档的控制操作。
· 末行模式:用户在命令行模式输入“:”,那么以后的按键操作会在当前屏幕最后一行出现,完成文档的一些辅助功能。
Vi刚启动时处于命令模式,可以通过a/A/i/I/o/O中的任意一个键进入插入模式。其中:
· a:即将插入的字符将处于光标所处当前位置后的一个字符
· A:即将插入的字符将处于光标所处当前行尾
· i:即将插入的字符将处于光标所处当前位置前的一个字符
· I:即将插入的字符将处于光标所处当前行首
· o:即将插入的字符将在光标所在行的下一行行首出现
· O:即将插入的字符将在光标所在行的上一行行首出现
在插入模式下进行文本输入,输入完毕后通过Esc建将工作模式切换到命令模式。
命令模式下,可通过输入“:”进入末行模式,在末行模式下,可按Esc建或输入其他命令重新返回命令模式,还可以输入q/wq/q!推出Vi。
· q:如果当前文件没有修改过,将直接退出Vi,否则会提示信息且并不退出
· wq:保存当前文件并退出Vi
· q!:直接退出Vi,即使当前文件被修改过,也不保存修改内容
② 命令行操作:
⑴ 行复制:
复制当前行:将光标移动到要复制行的任意位置,“yy”命令复制当前行。
复制多行:将光标移动到要复制多行的第一行,使用“nyy”命令,n为行数。
⑵ 行剪切:
剪切当前行:将光标移动到要剪切行的任意位置,“dd”命令剪切当前行。
剪切多行:将光标移动到要剪切多行的第一行,使用“ndd”命令,n为行数。
⑶ 行粘贴:
将复制或剪切的内容粘贴在光标所在行的下一行,使用“p”命令。
将复制或剪切的内容粘贴在光标所在行的上一行,使用“P”命令。
⑷ 行删除:
如果剪切后的内容不粘贴,剪切相当于删除。
⑸ 行定位:
如果行数很多,要定位的某一行,使用命令“nG”,n为行数。
⑹ 显示或取消Vi行号:
显示行号使用“:set nu”命令;取消行号使用“:set nonu”命令。
⑺ 撤销刚才的操作:
使用“u”命令撤销刚才的操作。
⑻ 重做刚才的操作:
使用“.”命令重做刚才的操作。
⑼ 文件部分内容另存为另一个文件:
如将文件第m行到n行之间的内容保存为文件f1,使用命令“:m,n w f1”。如果去掉其中的m和n 就将整个文件另存为另一个文件。
2) GCC编译器:
Linux系统下的主要编译器是GCC,这是一个用于编程开发的自由编译器。最初,GCC只是一个C编译器,是GNU C Compiler的缩写,后来发展成包含C、C++、Ada、Object C、Java等众多语言的编译器,改称GNU Compiler Collection。GCC具有交叉编译功能,可在一个平台下编译另一个平台的代码。
GCC通过文件后缀来区别输入文件的类别,所遵循的部分文件后缀约定规则:
| .c后缀文件 | C语言源代码文件 |
| .a后缀文件 | 由目标文件构成的档案库文件 |
| .C、.cc、.cxx后缀文件 | C++源代码文件 |
| .h后缀文件 | 程序包含的头文件 |
| .i后缀文件 | 已经预处理过的C源代码文件 |
| .ii后缀文件 | 已经预处理过的C++源代码文件 |
| .m后缀文件 | Object C源代码文件 |
| .o后缀文件 | 编译后的目标文件 |
| .s后缀文件 | 汇编语言源代码文件 |
| .S后缀文件 | 经过预处理的汇编语言源代码文件 |
gcc [option] infile⑴ 将源文件生成可执行文件:
gcc -o outfile infile
gcc infile -o outfile其中infile为源文件或目标文件,可为多个用空格分隔的文件名,outfile为可执行文件。如果不指定“-o outfile”,默认生成a.out文件。
⑵ 将源文件生成目标文件:
gcc -c infile生成的目标文件加后缀.o。此时生成的目标文件尚未与库函数链接,因此无法执行。在源文件较多情况下,可以先将源文件分别生成目标文件,最后链接成可执行文件,如果某个文件经过修改,可以只对此源文件再生成目标文件,然后与其他目标文件链接,未修改的目标文件不用再次生成目标文件。
⑶ 生成带有调试信息的可执行文件:
gcc -g -o outfile infile
gcc -g infile -o outfile编译后加上调试信息,以便GDB调试器进行调试。
⑷ 生成汇编文件:
gcc -S infile把源文件编译为汇编文件,可以使用vi查看生成的汇编文件。
⑸ 生成.i文件:
gcc -E infile -o infile.i只执行了源文件预处理。
⑹ 设置自定义头文件路径:
gcc -I dirname infile将dirname指定的目录加入程序头文件目录列表中。头文件引用有两种格式:
#include <myinc.h>
#include "myinc.h"前一种格式,在预处理时在预设包含文件目录中搜寻相应文件;后一种格式,首先在当前目录中搜寻头文件。使用-I选项,就在系统预设头文件目录之前先到指定的dirname目录中搜寻相应头文件。
⑺ 设置自定义库文件路径:
gcc -L dirname infile将dirname指定的目录加入库函数文件的目录列表中,这是链接过程使用的参数。预设情况下,链接程序ld在系统预设路径(如/usr/lib)中搜寻所需要的库文件,使用-L选项,则首先到指定的目录中去寻找,然后到系统预设路径中寻找。
⑻ 编译时加载库文件:
gcc -l name infile如果工程中将自定义函数做成库函数,在使用库函数内的函数时需要加载自定义函数库。一般C语言的库函数都以libname.so来命名共享库文件,用libname.a命名静态库文件。GCC链接时优先使用共享库,在共享库不存在时才考虑使用静态库,可以使用-static选项强制使用静态库。
⑼ 增加警告信息:
gcc -Wall infile
3) Make命令与Makefile文件:
一个工程中可能有很多源文件,并分别放置在不同目录中,直接使用gcc命令行生成可执行文件会比较繁琐,这时可以在一个Makefile文件中定义一系列规则来指定要编译的文件,这样用户只需要输入make命令即可根据Makefile文件中的规则编译工程文件,提高效率。
① make命令:
默认情况下,make命令会在工作目录下按照文件名顺序寻找Makefile文件读取并执行,查找顺序为GNUmakefile、makefile、Makefile,但GNUmakefile只有GNU make命令才可以识别,不推荐使用。还可以通过make命令的-f选项指定读取的Makefile文件:
#make -f NAME
此选项指定文件NAME作为执行make命令时读取的Makefile文件,也可以通过多个-f选项来指定多个需要读取的Makefile文件,多个文件将按照指定的顺序进行连接并被make命令解析执行。通过-f选项指定make命令读取的Makefile文件时,make命令就不再自动查找默认读取的Makefile文件。
make是一个命令工具,最基本的功能就是解释Makefile文件,大多数IDE都有这个命令,其工作方式如下:
· 读入Makefile文件,主Makefile文件可以引用其他Makefile文件
· 读入被包含include的其他Make file文件
· 初始化文件中的变量
· 推导隐含规则,并分析所有规则
· 为所有的目标文件创建依赖关系
· 根据依赖关系决定哪些目标要重新生成
· 执行生成命令
② Makefile文件的内容:
在一个完整的Makefile文件中,包含显式规则、隐含规则、变量定义、指示符和注释这五项内容。
⑴ 显式规则:
Makefile的显式规则描述了如何更新一个或多个目标文件。Makefile文件中需要明确给出目标文件、目标的依赖文件列表以及更新目标文件所需要的命令。语法格式:
objfile: dependent_file_list
<tab>command_to_update_objfile
以Tab字符开头的行,make命令会将其交给系统shell程序去解释执行。
示例:
hello:hello.c
gcc -o hello hello.c
这段规则含义是,Makefile文件的目标是hello,依赖hello.c文件,生成hello使用命令gcc -o hello hello.c。这个命令行会交给shell去执行。
⑵ 隐含规则:
隐含规则是make命令根据一类目标文件而自动推导出来的规则,不需要明确给出重建目标文件所需要的细节描述。比如,当Makefile中出现一个目标文件.o时,会自动将.c文件编译为.o文件。Makefile文件中的隐含规则很多,示例说明:
foo:foo.o bar.o
gcc -o foo foo.o bar.o
其中并没有写foo.o和bar.o的生成规则,但根据隐含规则,make命令将自动寻找foo.c和bar.c并调用cc命令将源文件生成foo.o和bar.o。
Makefile还支持一些预设的自动化变量,这些变量只能出现在规则的命令中:
· $^:所有的依赖文件,以空格分开,不包含重复的依赖文件
· $<:第一个依赖文件名称
· $@:目标的完整名称
⑶ 变量含义:
Makefile中的变量仅仅用一个字符或字符串作为变量来代表一段文本串。当定义了一个变量代表一段文本串后,Makefile文件后续在需要使用此文本串的地方,通过引用这个变量就可以表示这段文本串。
变量的引用方式是“$(varname)”或“${varname}”,例如,“$(foo)”或“${foo}”就是取变量foo的值。变量的引用可出现在Makefile文件的目标、依赖、命令、绝大多数指示符和新变量的赋值中。示例:
objects=program.o foo.o utils.o
program:$(objects)
gcc -o program $(objects)
$(objects):defs.h
⑷ 指示符:
用来指明make命令在读取Makefile文件过程中所要执行的一个动作。常用指示符有include、endif、else、ifeq、ifneq、define、endef、ifdef、ifndef等。
· include包含指示符:
用来指示读取一个给定的Makefile文件。语法格式:
include makefilename
如果指定的文件名不是以斜线开始,而且当前目录也不存在此文件,make命令将根据文件名试图按顺序查找命令行选项-I或--include-dir指定的目录、/usr/gnu/include、/usr/local/ include、/usr/include。
· 条件分支指示符:
条件判断语句的语法有不包含else和包含else分支的两种。
CONDITIONAL-DIRECTIVE
TEXT-IF-TRUE
endif
CONDITIONAL-DIRECTIVE
TEXT-IF-TRUE
else
TEXT-IF-FALSE
endif
而其中的CONDITIONAL-DIRECTIVE用以下关键字来测试不同的条件。
· 条件判断指示符:
ifeq(ARG1,ARG2) :判断参数是否相等
ifneq(ARG1,ARG2) :判断参数是否不相等
ifdef VARIABLE-NAME :判断变量是否已定义
ifndef VARIABLE-NAME :判断变量是否未定义
通过条件判断,可以决定处理或忽略Makefile文件中的某一特定部分。
· 定义多行命令:
define varname
Multi-line-cmd
endef
这种方式定义了包含多行字符串的变量。如:
define two-lines
echo foo
echo $(bar)
endef
相当于定义了:
two-lines=echo foo;echo $(bar)
Shell会将变量two-lines的值作为一个完整的shell命令来执行。
⑸ 注释:
Makefile文件中将#字符后的内容作为注释内容处理。如果注释行尾为反斜线,下一行也为注释行。如果Makefile文件中需要使用字符#,可以通过前面加反斜线来使用。
⑹ 特殊用法:
一个Makefile文件中可能存在不止一条规则,make命令默认执行Makefile中的第一条规则,并根据第一条规则去寻找并执行其他规则。示例:
hello:hello.o
gcc -o hello hello.o
hello.o:hello.c
gcc -c hello.c
clean:
rm hello hello.o -f
默认make命令执行第一条规则hello,再根据第一条规则中的依赖文件hello.o去执行第二条规则。由于已经生成了hello,因此不执行第三条规则。如果要执行第三条规则,需要在make命令后加上第三条规则的目标clean作为选项:
make clean
这样只执行第三条规则。通常Makefile文件中都会包含clean规则,目的是删除中间生成的临时文件或最终生成的可执行文件,并且一般rm命令都会带有-f选项。因此一定要将Makefile文件中的clean所在的规则设置好。
4) GDB调试器:
程序执行情况需要通过调试方法来判断,为了方便调试,应在源程序的适当位置加入printf()语句,输出有关变量或地址,在执行过程中可以根据输出语句情况来确定出现问题的位置。
Linux系统有GDB调试器,可以协助查找程序运行中的问题,为了便于调试,使用gcc编译程序时使用-g选项,生成带调试信息的可执行文件。在命令行输入:
#gdb hello
然后就进入调试环境。GDB是字符界面的调试工具,通过命令来进行调试。可以使用help查看GDB的使用方法,也可以指定查看某类命令,用help classname命令。如要查看设置的断点用help breakpoints。常用命令:
| backtrace | 显示程序中的当前位置和表示如何到达当前位置的栈跟踪 |
| break n | 在程序中某行设置一个断点 |
| cd | 改变当前工作目录 |
| clear | 删除刚才停止处的断点 |
| commands | 遇到断点时,列出将要执行的命令 |
| continue | 从断点开始继续运行 |
| delete | 删除一个断点或监测点,也可以与其他命令一起执行 |
| display | 程序停止时显示变量和表达式 |
| down | 下移栈帧,使得另一个函数成为当前函数 |
| frame | 选择下一条continue命令的帧 |
| info | 显示与该程序有关的各种信息 |
| jump | 在源程序中的另一点开始运行 |
| kill | 异常终止在GDB控制下运行的程序 |
| list | 列出对应于正在执行的程序的源文件内容 |
| next | 执行下一个源程序行,若断点所在行是函数调用,则不进入函数内部 |
| print var | 显示变量或表达式的值 |
| pwd | 显示当前工作目录 |
| pype | 显示一个数据结构的内容 |
| quit | 退出GDB |
| reverse-search | 在源文件中反向搜索正规表达式 |
| run | 执行该程序 |
| search | 在源文件中搜索正规表达式 |
| set variable | 给变量赋值 |
| signal | 将一个信号发送到正在运行的进程 |
| step | 执行下一个源程序行,若断点所在行是函数调用,则进入函数内部 |
| undisplay display | 显示命令的反命令,不要显示表达式 |
| until | 结束当前循环 |
| up | 上移栈帧,使另一个函数成为当前函数 |
| watch | 在程序中设置一个监测点,即数据断点 |
| whatis var | 显示变量或函数类型 |
5) 库:
Linux系统下编译生成一个可执行文件时,需要将这个可执行文件需要的函数目标文件包含进去。对一个较大的工程,可能有很多函数目标文件,这种目标文件可能会被其他工程或程序调用,将这些函数目标文件组合在一个单独的文件中就是库文件。
库有静态库和共享库两种形式,静态库的代码在编译时就已经链接到应用程序中,而共享库只是在程序运行时才载入,编译时只指定需要使用的库函数。由于程序中只包含了对共享库函数的引用,并不包括内容,因此可执行文件的代码规模较小。Linux系统中大多数库都采用共享库方式。
Linux系统中可用的库都存放在/usr/lib和/lib目录中,静态库后缀为.a,共享库后缀由.so和版本号组成。C语言标准函数库为libc.so后接版本号,数学共享库libm.so.5,X-Windows库为libX11.so.6。GCC编译器会自动链接C标准函数库,但大部分系统函数库需要在命令行通过-l name显式指定所用的库名。
因为GCC编译器对所链接的共享库文件名要求以.so结尾,一般共享库文件名后有版本号,通常都会给真正的共享库文件建立符号链接文件,方式为:
#ln -s libhello.so.1 libhello.so
在/usr/lib和/lib目录中可用找到绝大多数共享库,GCC编译器链接时会自动先搜索这两个目录。但也有一些库可能放置在特定目录中,如/etc/ld.so.conf配置文件中给出了这些目录的列表,链接程序会对配置文件中列出的这些目录搜索。默认情况下,Linux会先搜索共享库,找不到才会搜索静态库。
如果开发者自己编写了库文件,如果要让GCC自动找到该库,应放置在/usr/lib或/lib目录中,或者将该库文件的绝对路径加入/etc/ld.so.conf配置文件中,然后运行ldconfig命令更新。
① 静态库的创建与使用:
要将fun1.c和fun2.c生成静态库,先要生成目标文件:
#gcc -c fun1.c fun2.c
然后生成静态库:
#ar -rcs libxxx.a fun1.o fun2.o
选项-r表示在库中插入模块,当模块名已存在时替换同名模块;-c表示无论库是否存在都将创建,不给警告;-s表示强制更新库的符号表,即使库的内容没有变化。
使用静态库:
#gcc -o test_s test.c -L .-lxxx -static
选项-static表示强制使用静态库libxxx.a。如果将静态库放入了/usr/lib或/lib目录,可以去掉“-L .”
2. Linux程序设计基础:
1) 程序及进程的存储结构:
Linux平台下的可执行文件格式有a.out、COFF(Common Object File Format)、ELF(Executable and Linking Format)这3种形式,可以使用“file filename”来查看可执行文件的格式。目前,大多数Linux系统已经采用ELF取代了a.out格式,虽然GCC编译工具输出为a.out,但只是沿用了名字,实际格式为ELF。
可执行文件都包含代码段text、数据段data、BSS(Block Started by Symbol)段。代码中保存程序代码,通常为只读的;数据段保存已经初始化的全局变量和静态变量;BSS保存未初始化的全局变量和静态变量,并在程序执行之前被内核初始化为0或空指针NULL。
运行可执行文件后产生一个新的进程,操作系统会将可执行文件的内容从磁盘复制到内存中,并为进程分配内存空间以保存其他相关内容。进程中内存的映像主要分为代码段text、数据段data、BSS段、堆heap、栈stack。其中堆是动态分配的内存区域,大小不固定,可动态增加和减小,C语言中使用malloc函数和free函数进行分配和释放。栈是用来保存函数临时创建的局部变量的,另外在函数被调用时,函数参数也会被压入发起调用函数的进程栈中,调用结束后函数的返回值会被存放到栈中。堆空间需要手动申请和释放,而栈空间是系统自动分配和释放。
2) 变量的类型修饰符:
常见的类型修饰符有auto、const、register、static、volatile、extern,其中static和extern也可以用来定义函数。auto可以不必显式写出,即没有指定类型修饰符的变量都是auto变量。类型修饰符用于指明该变量的存储位置,const修饰的变量是只读的,volatile修饰符定义的变量所在的代码不会被编译器优化,每次都直接从内存中取值。
修饰符含义见表:
| 变量 | 存储位置 | 生存期 | 作用范围 |
|---|---|---|---|
| auto变量 | 栈 | 所在函数 | 所在{}内 |
| static全局变量 | 已初始化在data,未初始化在BSS | 当前进程 | 当前文件 |
| static局部变量 | 已初始化在data,未初始化在BSS | 当前进程 | 所在{}内 |
| extern全局变量 | 声明引用定义在别处的全局变量 | 当前进程 | 当前进程 |
| register变量 | CPU寄存器 | 所在函数,只有局部变量才能使用 | 所在{}内 |
3) 命令行参数及获取:
C语言使用main函数作为程序执行的入口,main函数的原型有几种形式,一般返回值为int。
int main(void)
int main(int argc,char *argv[])
int main(int argc,char *argv[],char *env[])
通常main函数不带参数,如果程序需要获取用户运行程序时指定的命令行参数,就需要main函数带参数。参数argc和argv传递了命令行参数信息,env参数代表环境变量的指针数组,用于获取系统传递给进程的环境变量值。参数argc代表命令行参数的个数,包括程序名,因此argc至少为1;argv是一个指针数组,指向包括程序名在内的各个命令行参数项字符串地址,argv[0]代表程序名,其后依次指向各参数项字符串,argv[argc]的值为NULL。
当参数过多时,也可以使用getopt获取命令行参数:
int getopt(int argc,char *const argv[],const char *optstring);
其中argc和argv含义与main函数的相同,optstring是一个包含了合法的选项字符的字符串。通常getopt会在循环中使用,每次调用将返回选项参数中的选项字符,如果遇到未知的选项参数或选项参数缺失则返回?;如果所有命令行参数遍历结束则返回-1。
4) 环境变量:
Shell是一个特殊的进程,是用户与内核之间的接口。Shell启动后拥有多个自己的变量,以列表形式保存,这些变量称为环境变量。在Shell中启动进程后,进程使用特殊的全局变量char **environ继承Shell的环境变量,用户使用时只需要通过extern char **environ引用。
① 环境变量命令:
Shell中对环境变量的操作包括查看、定义、修改、删除。
⑴ 查看:
echo $envname
如,echo $HOME将输出登录用户的主目录。
⑵ 定义:
envname=value
这样定义的环境变量只能被Shell本身访问,不能被Shell启动的其他应用程序访问。可以使用export命令,如:
#export myvar=hello
或
#myvar=hello
#export myvar
这样,新运行的程序就能访问myvar变量。
⑶ 修改:
与环境变量定义格式相同,也可以使用export。
⑷ 删除:
#unset envname
使用命令方式对变量作出的改变都是临时的系统重启后将恢复之前的状态,因为Linux系统启动中通过读取系统配置文件来确定各环境变量的值。如果用户需要长久保持对环境变量的改动,就需要将改动写入文件/etc/profile和用户主目录中的.bash_profile。
② 环境变量函数:
编程过程中访问进程的环境变量需要使用函数,常用的有getenv、putenv、setenv、unsetenv。
| char *getenv(const char *name) | 获取指定环境变量 |
| int *putenv(char *string) | 改变或增加环境变量 |
| int setenv(const char *name,const char *value,int overwrite) | 改变或增加环境变量 |
| void unsetenv(const char *name) | 删除指定环境变量 |
5) 错误代码:
一般地,在Linux系统中,返回值为整型的函数执行出错时通常返回一个负值,返回值为指针类型的函数执行出错时通常返回NULL指针。函数执行出错的原因很多,可通过一个全局整型变量errno来区分错误类型,值为0表示没有错误。
使用命令man errno可以查看errno的相关帮助文档。在/usr/include/asm/errno.h文件中定义了errno取值以及对应的常量符号,同时还注释了取值对应的错误原因。
因为errno不具有可读性,C标准定义了两个函数协助输出errno对应的错误原因:
| char *strerrir(int errnum) | string.h | 将某个错误代码转换成对应的出错信息 |
| void perror(const char *s) | stdio.h | 根据当前errno打印errno对应的错误信息 |
6) 标准I/O与文件I/O:
Linux系统是以文件为基础设计的,通过文件控制块FCB(File Control Block)来管理文件,一切都是文件。文件通常可分为5种类型:
· 普通文件:系统和用户保存数据、程序等信息的文件
· 目录文件:Linux系统将文件索引节点号和文件同时保存在目录中,因此目录文件就是文件名及其索引节点号相结合的一张表
· 设备文件:Linux系统将所有的外设都当成文件来处理,每一种外设都对应着一个设备文件,设备文件保存在“/dev”中
· 管道文件:又称为先进先出FIFO文件,是进程之间传递数据的工具。Linux对管道的操作与对文件的操作是相同的
· 链接文件:又称符号链接文件,是一种共享文件的方法,通过链接文件中包含的指向原文件的指针来实现对文件的访问
通过ls -l可以查看Linux系统中文件的类型和属性,返回结果的第一个字符表示文件类型:
| - | d | l | c | b | p | f |
|---|---|---|---|---|---|---|
| 普通文件 | 目录文件 | 链接文件 | 字符设备 | 块设备 | 管道文件 | 堆栈文件 |
对于文件的输入/输出一般有两种形式,标准I/O与文件I/O,标准I/O有用户缓冲区,而文件I/O没有。采用用户缓冲区的目的是尽可能减少使用系统调用read和write的次数。在Linux系统中,其实会使用内核缓冲技术来提高读写效率的,读写调用是在内核缓冲区和进程缓冲区之间进行的数据复制。
| 操作 | 标准I/O | 文件I/O |
|---|---|---|
| 打开 | fopen freopen fdopen | open |
| 关闭 | fclose | close |
| 读 | getc fgetc getcharfgets gets fread | read |
| 写 | putc fputc putcharfputs puts fwrite | write |
· 全缓冲:填满I/O缓冲区才进行I/O操作
· 行缓冲:当在输入和输出中遇到换行符时执行I/O操作
· 无缓冲:不对字符进行缓冲存储
一般来说,对于磁盘的读写操作是全缓冲,对于显示器等终端设备的操作是行缓冲,标准错误输出是无缓冲。缓冲区类型可以通过setvbuf函数改变。
| int setvbuf(FILE *stream,char *buf,int mode, size_t size) | 设定某个文件流的缓冲区类型 |
| stream:文件流指针, buf:缓冲区首地址,由用户函数malloc得到 mode:可设置为无缓冲_IONBF、行缓冲_IOLBF、全缓冲_IOFBF size:缓冲区大小 |
成功返回0,错误返回非0 |
带缓存文件操作函数:fopen、fwrite、fread、fseek、fgetc、getc、getchar、fputc、putc、putchar、fgets、gets、fclose
可以使用setbuf和setvbuf更改缓存类型。
格式化输入函数:scanf、fscanf、sscanf
格式化输出函数:printf、fprintf、sprintf
3. Linux系统常用函数:
1) 文件操作函数:
对文件的操作,有低级函数和高级函数,低级函数有open()、close()、read()、write()、lseek()等,而对应的高级函数为fopen()、fclose()、fread()、fwrite()、fseek()。低级函数返回的是整数型的文件描述符,高级函数返回的是FILE函数体,低级函数是操作系统提供的系统调用,高级函数是由C库提供的库函数。
① 文件的创建与打开:
函数open()与creat()可以打开和创建一个文件或设备。
int open(const char *pathname,int flags)
int open(const char *pathname,int flags,mode_t mode)
int creat(const char *pathname,mode_t mode)
给定一个文件路径,open()函数返回一个文件文件描述符,给后续的函数使用,一个成功调用所返回的文件描述符将会是当前进程未打开的最小编号的文件描述符。默认情况下,这个新的文件描述符在执行程序的过程中被设置为保持打开,并且文件偏移被设置为文件的开始。
参数flags必须为以下的访问模式,O_RDONLY、O_WRONLY、O_RDWR,这些模式分别要求被打开的文件具有只读、只写、读写属性;文件还有创建标识O_CREAT、O_EXCL、O_NOCTTY、O_TRUNC,创建标识创建时就确定了;其他为文件状态标识。参数mode描述了文件的使用权限,只有在flags参数中设置O_CREAT标识时才能使用。
② 文件的读写:
ssize_t read(int fd,void *buf,size_t count)
函数read()试图从fd指定的文件描述符中读取count个字节的数据到buf缓冲区。函数调用成功,返回读取的字节数,并且文件的读取位置也会向前移动这么多字节数。函数调用失败返回-1,并设置相应errno值。返回0表示文件结束。
ssize_t write(int fd,void *buf,size_t count)
函数write()试图从buf缓冲区向fd指定的文件描述符写入count字节的数据。对于一个可随机读取的文件,在文件当前偏移处进行写入操作,并且文件偏移增加实际写入的字节数。如果打开文件使用O_APPEND,再开始写入前,文件偏移设置为文件尾。
函数调用成功,返回成功写入的字节数;函数调用失败返回-1,并且设置相应的errno值。返回0表示没写入数据。
③ 文件关闭:
int close(int fd)
函数close()用来关闭一个文件描述符。调用成功返回获得的文件描述符,失败返回-1。
④ 改变文件读写偏移位置:
对每个打开的文件,内核记录一个文件偏移,表示相对于文件开始的一个顺序的字节位置,文件第一个字节的偏移为0。当文件被打开时,文件偏移设置为文件的开始,在一定的字节数据被读取或写入后,文件偏移指向文件的下一个字节。
off_t lseek(int fd,off_t offset,int whence)
函数lseek()依照参数offset和whence的设置,调整文件描述符fd所指被打开文件的偏移。
whence的可设置选项:
· SEEK_SET:相对于文件的开始位置,把文件偏移设置为参数offset指定的偏移量
· SEEK_CUR:在文件当前偏移位置基础上,向后偏移参数offset指定的偏移量
· SEEK_END:在文件尾基础上,向后偏移参数offset指定的偏移量
函数lseek()允许设置的文件偏移超出文件尾部,如果在这个位置写入,后续读取该间隙的数据将返回空字节(\0),直到有实际的数据写入该间隙。
函数执行成功后返回偏移位置,该位置从文件开始位置计算,以字节为单位。调用失败返回-1,并设置相应的errno值。
⑤ 控制设备文件参数:
int ioctl(int d,int request,...)
此函数用来操控特定文件的底层设备参数,许多字符设备的操作特性可使用ioctl()函数的请求来控制,比如终端。参数d为一个打开的文件描述符。
第二个参数是一个依赖设备请求的编码,第三个参数是一个无类型指向内存的指针,传统上为char* argp(),一个请求被编码进该参数中,大小单位为字节。
⑥ 其他文件操作函数:
主要是一些文件权限修改函数,获取文件状态,文件重命名,文件链接函数等。
2) 目录操作函数:
包括创建、删除、打开、读取、关闭、改变工作目录、取得当前工作目录等函数。
3) 系统与进程控制函数:
① 获取节点信息:
Linux下使用以下命令或函数获取主机节点信息:
hostname
uname
hostid
int gethostname(char *name,size_t len)
int sethostname(char *name,size_t len)
int uname(struct utsname *buf)
long gethostid(void)
int gethostid(long hostid)
② 获取进程号:
pid_t getpid(void) //取得当前进程的进程号
pid_t getppid(void) //取得父进程的进程号
4) Linux的时间管理与处理函数:
计算机有硬件时钟RTC,使用电池供电,Linux启动时从RTC读取日期和时间作为基准值,但运行时则抛开RTC,以软件维护当前日期和时间,并在需要时将时间写回RTC。
Linux内核提供的时间是从国家标准时间UTC公元1970年1月1日0时0分0秒开始以来经过的秒数,称为日历时间,数据类型time_t。日历时间可以通过time系统调用获取。日历时间可读性很差,因此一般会转换为结构体类型或字符串使用。
① Linux的常用时间类型:
Linux常用的时间类型有time_t、struct tm、struct timeval、struct timespec四种。
⑴ time_t:
实际上是一个长整型,其值表示为从UTC时间1970年1越1日0时0分0秒到当前时刻的秒数,这个起始时间点也称为Linux系统的Epoch时间。因为time_t类型长度的限制,表示的时间不能晚于UTC时间2038年1月19日3时14分07秒,为了能够表示更加久远的时间,可用64位或更长的整数来保存。
使用time()函数可获取当前时间的time_t值,使用ctime()函数将time_t转为当时时间字符串。
⑵ struct tm:
结构体tm定义为:
struct tm{
int tm_sec; //秒,0~61,预留2秒闰秒
int tm_min; //分,0~59
int tm_hour; //小时,0~23
int tm_mday; //月内日期,1~31
int tm_mon; //月份,0~11
int tm_year; //年,自1900年开始计算
int tm_wday; //星期,0~6
int tm_yday; //年中日期,0~365
int tm_isdst; //夏令时标记,0无效
}
使用函数gmtime()和localtime()可将time_t时间类型转换为tm结构体,使用mktime()将tm结构体转换为time_t时间类型,使用asctime()将tm结构体转换为字符串形式。
⑶ struct timeval:
struct timeval{
time_t tv_sec; //秒
suseconds_t tv_usec; //微秒
}
使用设置时间函数settimeofday()和获取时间函数gettimeofday()时,均以该结构体类型作为参数。
⑷ struct timespec:
struct timespec{
time_t tv_sec; //秒
long tv_nsec; //纳秒,取值[0,999999999]
}
此结构体用来描述纳秒精度的时间值,在高精度睡眠函数nanosleep()中使用该结构体为参数。
⑸ struct timezone:
struct timezone{
int tz_minuteswest; //格林威治时间往西的时差
int tz_dsttime; //夏令时修正值
}
Linux已经废除此结构体。
② 常用时间格式之间的转换:
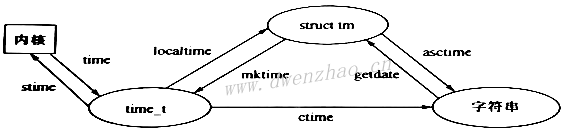
进行日期及时间转换的函数或系统调用:
| time_t time(time_t *t) | 得到当前日期和时间 |
| struct tm *localtime(const time_t *t) | 把time_t转换为本地分散时间 |
| time_t mktime(struct tm *tmbuf) | 把本地分散时间转换为time_t |
| char *ctime(const time_t *t) | 把time_t转换为本地时间字符串 |
| int stime(time_t *t) | 设置系统时间 |
③ 获得与修改系统时间:
int gettimeofday(struct timeval *tv,struct timezone *tz)
int gettimeofday(const struct timeval *tv,const struct timezone *tz)④ 线程睡眠时间函数:
unsigned int sleep(unsigned int seconds)
int usleep(useconds_t usec)
int nanosleep(const struct timespec *req,struct timespec *rem)⑤ 其他时间相关函数:
unsigned int alarm(unsigned int seconds)
double diffrime(time_t time1,time_t time0)
4. Linux系统线程:
程序的执行实例称为进程Process。线程Thread是进程中某个单一顺序的控制流,通常在一个进程中可以包含若干个线程,多线程可认为是并发运行的。
每个进程都有各自独立的内存空间,如果进程间需要通信需要增加额外开销,并增加了程序的复杂性。而同一个进程的所有线程共享相同的内存空间,不同线程共享内存中的大部分数据。使用线程带来的开销很小,从而节省大量的CPU时间和系统资源,其创建比创建进程要快十到百倍,切换线程时间也远小于进程切换的时间。多线程程序作为多任务、并发的工作方式,可以把不同的线程运行在不同的CPU上从而使多CPU系统更加有效,不复杂的进程分为多个线程利于程序的理解和修改,把耗时长的操作置于一个新的线程,可以提高系统对其他线程的响应速度。
因为嵌入式系统资源受限,因此软件开发中多数情况下会使用单进程/多线程模式,而少用多进程/单线程模式。
1) 线程的创建与关闭:
int pthread_create(pthread_t *thread,const pthread_attr_t *attr, void *(*start_routine)(void*),void *arg)
参数thread返回创建的线程id;参数attr是创建线程时设置的线程属性。参数arg是void *类型的变量,可以作为任意类型的参数传给start_toutine()函数,同时start_toutine()可以返回一个void *类型的返回值,并由pthread_join()函数获取。
线程通过调用pthread_exit()函数,或从线程函数中return都将使线程正常退出。
void pthread_exit(void *retval)
线程也可能非正常终止,如有其他线程干预,或自身运行出错。
2) 线程资源的释放与回收:
一般情况下,进程中的线程的运行是相互独立的,线程的终止并不会通知,也不会影响其他线程,终止的线程所占用的资源也不会随着线程的终止而释放。使用pthread_join()函数用来同步线程并释放资源:
int pthread_join(pthread_t thread,void **retval)
pthread_join()的调用者将挂起并等待thread线程终止,retval是pthread_exit()调用者线程的返回值,如果pthread
一个线程仅允许一个线程使用pthread_join()等待它的终止,并且被等待的线程要处于可join状态,而不能为DETACHED状态。如果进程中的某个线程执行了pthread_detach(th),则th线程将处于DETACHED状态,使得th线程在结束运行后自行释放所占用的资源,也无法由pthread_join()同步。
int pthread_detah(pthread_t thread)
一个可join的线程所占用的内存,仅当有线程对其执行了pthread_join()后才会释放。为了避免内存泄漏,对于所有线程的终止,要么设为DETACHED,要么就需要使用pthread_join()来回收。
3) 获取本线程标识符:
pthread_t pthread_self(void)
返回值pthread_t为无符号长整数。
4) 线程的同步与互斥:
线程之间可以通过全局变量共享信息,但也会造成读写时的冲突。当一个线程试图更新一个共享变量时,必须使用一个互斥操作,确保在同一时刻只有一个线程能够访问该变量。
① 互斥锁:
互斥锁提供了一种相互排斥的方法,使得两个线程不能同时对同一个互斥对象加锁,从而使一个共享资源不能被两个线程同时操作。
如果线程B试图锁定一个互斥锁M,而此时线程A已锁定了同一个互斥锁M,线程B将进入阻塞状态。一旦线程A释放了互斥锁M,线程B就将从阻塞状态中苏醒,也就能够锁定这个互斥锁M。对已锁定的互斥锁,执行锁定的所有线程都将进入阻塞状态,这些阻塞的线程将排队访问这个互斥锁所保护的互斥对象。
⑴ 互斥锁的创建与销毁:
静态创建互斥锁:
pthread_mutex_t mutex=PTHREAD_MUTEX_INITIALIZER
使用该方法初始化的互斥锁,在程序结束时不需要人为执行销毁。
动态创建互斥锁:
int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr)
参数attr用于指定互斥锁属性,,默认为null。动态创建的互斥锁,在不使用后必须调用pthread_mutex_destroy()销毁。
int pthread_mutex_destroy(pthread_mutex_t *mutex)
销毁互斥锁意味着释放其所占的资源,并要求互斥锁当前处于解锁状态。
⑵ 操作互斥锁:
int pthread_mutex_lock(pthread_mutex_t *mutex)
int pthread_mutex_unlock(pthread_mutex_t *mutex)
int pthread_mutex_trylock(pthread_mutex_t *mutex)
三个函数分别为加锁、解锁和测试加锁。pthread_mutex_trylock()操作被占据的互斥锁时立即返回EBUSY,而不是阻塞等待。
在程序中遇到break、continue、return等跳转语句时,一定要在语句前先解锁。
② 读写锁:
读写锁适合于对数据结构的读次数比写次数多很多的情况。因为读模式锁定时可以共享,而写模式锁住时意味着独占,所以又称为共享-独占锁。如果读写锁当前没有读者,也没有写者,那么写者可以立刻获得读写锁,否则必须等待,直到没有任何写者或读者;如果读写锁没有写者,那么读者可以立刻获得该读写锁,否则读者必须等待,直到写者释放该读写锁。通常,当读写锁处于读模式锁住状态时,如果有另外的线程试图以写模式加锁,读写锁通常会阻塞随后的读模式请求,这样可以避免读模式长期占用,而等待的写模式请求长期阻塞。
一次只有一个线程可以占有写模式的读写锁,可以有多个线程同时占有读模式的读写锁。因为这个特性,当读写锁是写加锁状态时,在这个锁被解锁之前,所有试图对这个锁加锁的线程都会阻塞;当读写锁在读加锁状态时,所有试图以读模式对它进行加锁的线程都可以得到访问权,但是如果线程希望以写模式对此锁进行加锁,它必须直到所有的线程释放锁。
⑴ 读写锁的创建,也有静态和动态两种方式:
pthread_rwlock_t rwlock=PTHREAD_RWLOCK_INITIALIZER;
上面是静态初始化读写锁。静态方式通过一个定义的宏来初始化读写锁,这种方法在程序结束时不需要人为销毁。
int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock, const pthread_rwlockattr_t *restrict attr)
上面是动态初始化读写锁,参数attr用于指定读写锁属性,默认属性为null。
⑵ 获取读写锁中的读锁:
int pthread_rwlock_rdlock(pthread_rwlock_t *restrict rwlock)
int pthread_rwlock_tryrdlock(pthread_rwlock_t *restrict rwlock)
如果线程调用pthread_rwlock_rdlock()未获取读写锁,则它将阻塞,必须在获取该线程之后才能在调用中返回;如果需要不阻塞的操作,可调用pthread_rwlock_tryrdlock(),该操作在读写锁被写者占据或适当优先级的写者正阻塞时,立即返回EBUSY而不是阻塞等待。
一个线程可以在rdlock中持有多个并发的读锁,该线程可以成功调用pthread_rwlock_rdlock()多次,但该线程也必须调用pthread_rwlock_unlock()对应的次数才能执行匹配的解除锁定操作。
⑶ 获取读写锁中的写锁:
int pthread_rwlock_wrlock(pthread_rwlock_t *restrict rwlock)
int pthread_rwlock_trywrlock(pthread_rwlock_t *restrict rwlock)
调用pthread_rwlock_wrlock()的线程如果遇到其他读者线程或写者线程持有读写锁将阻塞,必须在获取该锁之后才能从调用返回。如果需不阻塞的操作,可调用pthread_rwlock _trywrlock(),该操作在读写锁被写者或读者占据时,立即返回RBUSY,而不是阻塞。
⑷ 解除锁定的读写锁:
int pthread_rwlock_unlock(pthread_rwlock_t *restrict rwlock)
⑸ 销毁读写锁:
int pthread_rwlock_destroy(pthread_rwlock_t *restrict rwlock)
③ 条件变量:
条件变量是利用线程间共享的全局变量进行同步的一种机制,主要包括一个线程等待条件变量的条件成立而挂起,另一个线程时条件成立。为了防止竞争,条件变量的使用总是和一个互斥锁结合在一起。
⑴ 条件变量的创建:
pthread_cond_t cond=PTHREAD_COND_INITIALIZER
上面为静态创建,使用一个定义的宏,这种方法创建的条件变量在程序结束时不需要人为销毁。
int pthread_cond_init(pthread_cond_t *restrict cond, const pthread_condattr_t *restrict attr)
上面为动态创建,参数attr用于指定条件变量属性,默认属性为null。
⑵ 条件变量的销毁:
int pthread_cond_destroy(pthread_cond_t *restrict cond)
销毁一个条件变量意味着释放其所占用的资源,只有没有线程在条件变量上等待时,才能销毁这个条件变量,否则返回EBUSY错误。
⑶ 条件变量的等待:
int pthread_cond_wait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex)
上面为无条件等待。
int pthread_cond_timedwait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex,const struct timespec *restrict abstime)
上面为超时等待。超时等待在超时时间到后,即使等待的条件不满足也会返回,但返回的值为ETIMEDOUT。
无论哪种等待,都必须与一个互斥锁配合,以防多个线程同时请求wait而出现竞争条件。在调用前,必须由本线程加锁,在条件满足离开wait后,mutex将被解锁。
⑷ 激发条件:
int pthread_cond_broadcast(pthread_cond_t *restrict cond)
上面函数激活一个等待该条件的线程,存在多个等待线程时激活其中一个。
int pthread_cond_signal(pthread_cond_t *restrict cond)
上面函数激活所有等待的线程。
④ 线程死锁的解决方法:
有时候,一个线程需要同时访问两个或多个不同的共享资源,每个共享资源使用一个独立的互斥锁进行保护。当多个线程正在锁定同样的互斥锁集合时,死锁状态可能产生。
解决死锁问题,一种方法是几个线程以同样的顺序获得互斥量,这样就不会出现死锁。另一种方法是以pthread
5) 线程参数传递:
int pthread_create(pthread_t *thread,const pthread_attr_t *attr, void*(*start_routine)(void *),void *arg)
用上述方法创建线程时,参数arg是void *类型的变量,该参数可作为任意类型的参数传给start_routine()函数,也就是可使用参数arg向新线程传递任意类型的数据。
当要传递多个参数时,一般可以定义一个结构体,把所有要传递的数据放在这个结构体中,把结构体作为单个参数传递给子线程。
6) 线程私有数据:
在一个进程中会有很多线程,这些线程共享进程里的所有资源,包括数据空间,所以全局变量是为所有线程所共享的。但线程也可以有私有数据TSD(Thread-specific Data),一个线程的TSD只有这个线程可以访问,这种TSD使用一个键对应多个数据值的方式,类似一个数据结构,结构名就是键值,结构中有许多数据,线程可以通过键值来访问其所属的数据结构。
创建TSD有3个步骤,先创建一个键值,然后为这个键值设置线程的私有数据,最后删除键值。对应的函数为:
int pthread_key_create(pthread_key_t *key,void (*destructor)(void *))
int pthread_setspecific(pthread_key_t *key,const void *value)
int pthread_key_delete(pthread_key_t *key)
创建的key,同一进程的所有线程都可见,但是pthread_setspecific()函数对key关联的值是基于每个线程的,并且其生命周期与调用的线程是一致的。可选项destructor函数是一个清理函数,可被每个key关联,在线程退出时,如果一个key有一个非空的destructor指针,并且线程有一个非空的值与该key关联,那么把key设置为null,接着调用destructor函数,并把前面与key关联的值作为函数的唯一参数。
pthread_setspecific()函数用于把TSD与key相关联。
pthread_key_delete()删除key时,并不检查是否有线程正使用该TSD,也不会调用清理函数,只是将TSD释放。
创建了TSD后,就可以用下面的函数来读取数据:
void* pthread_getspecific(pthread_key_t *key)
pthread_getspecific()函数通过key获得与其关联的TSD。
7) 修改线程属性:
线程的属性由pthread_attr_t结构类型表示,使用之前需要调用pthread_attr_init()对其初始化,初始化时对结构中的各个属性设置默认值,而程序可以修改这些值。pthread_attr_t使用完之后,需要调用pthread_attr_destroy()完成清理。
int pthread_attr_init(pthread_attr_t *attr)
int pthread_attr_destroy(pthread_attr_t *attr)
可以修改的线程属性:
⑴ 分离状态Detached State:
若线程终止时,线程处于分离状态,系统不保留线程的终止状态。当不需要线程的终止状态时,可以分离线程(调用pthread_detach()函数)。若在线程创建时,就已经知道以后不需要使用线程的终止状态,可以在线程创建属性里指定该状态,那么线程一开始就处于分离状态。
int pthread_attr_getdetachstate(const pthread_attr_t *attr,int *state)
int pthread_attr_setdetachstate(pthread_attr_t *attr,int *state)
上面两个函数分别为获取和设置线程的分离属性,可选值有PTHREAD
⑵ 栈地址Stack Address:
POSIX.1定义了_POSIX
int pthread_attr_getstackaddr(const pthread_attr_t *attr,void **addr)
int pthread_attr_setstackaddr(pthread_attr_t *attr,void **addr)
上面两个函数分别获取和设置线程的栈地址,传给pthread_attr_setstackaddr()函数的地址是缓冲区的低地址,但栈也有可能从高往低地址增长。
⑶ 栈大小Stack Size:
当系统有很多线程时,可能需要减小每个线程的默认大小,防止进程的地址空间不够用。当线程调用的函数会分配很大的局部变量或者函数调用层次很深时,可能需要增大线程栈的默认大小。
int pthread_attr_getstacksize(const pthread_attr_t *attr,size_t *size)
int pthread_attr_setstacksize(pthread_attr_t *attr,size_t size)
下面的函数可以同时操作栈地址和栈大小这两个参数:
int pthread_attr_getstack(const pthread_attr_t *attr,void **stackaddr,size_t *size)
int pthread_attr_setstack(pthread_attr_t *attr,void *stackaddr,size_t size)
⑷ 栈保护区大小Stack Guard Size:
在线程栈顶留出一段空间,防止栈溢出。当栈指针进入这段保护区,系统会发出错误,通常是发信号给线程。该属性默认值是PAGESIZE大小,该属性被设置时,系统会自动将该属性大小补齐为页大小的整数倍。当改变栈地址属性时,栈保护区大小通常清零。
int pthread_attr_getguardsize(const pthread_attr_t *attr,size_t *guardsize)
int pthread_attr_setguardsize(pthread_attr_t *attr,size_t guardsize)
⑸ 线程优先级Priority:
新线程的优先级为0,相关函数为:
int pthread_attr_getschedparam(const pthread_attr_t *restrict attr, struct sched_param *restrict param)
int pthread_attr_setschedparam(pthread_attr_t *restrict attr, const struct sched_param *restrict param)
⑹ 继承父进程优先级Inheritsched:
新线程不继承父线程调度优先级PTHREAD_EXPLICIT_SCHED。
⑺ 调度策略Schedpolicy:
新线程使用SCHED_OTHER调度策略。线程一开始运行,直到被抢占或者直到线程阻塞或停止为止。相关函数原型:
int pthread_attr_setschedpolicy(const pthread_attr_t *attr,int policy)
int pthread_attr_setschedparam(pthread_attr_t *attr,struct sched_param *param)
⑻ 争用范围Scope:
建立线程的争用范围PTHREAD
int pthread_attr_getscope(const pthread_attr_t *restrict attr, int *restrict contentionscope)
int pthread_attr_setguardsize(pthread_attr_t *attr,int contentionscope)
⑼ 线程并行级别Concurrency:
int pthread_attr_getconcurrency(void)
int pthread_attr_setconcurrency(int new_level)
POSIX标准指定了3种调度策略,先入先出策略SCHED
8) 线程池:
如果一个应用需要频繁创建和销毁线程,而任务执行的时间又非常短,这样的线程创建和销毁带来的开销就不容忽视,这时就需要线程池。
线程池采用预创建的技术,在应用程序启动之后,立即创建一定数量的线程,放入空闲队列中。这些线程都处于阻塞Suspended状态,不消耗CPU,但占用较小的内存空间。当任务到来后,缓冲池选择一个空闲线程,把任务放入此线程中运行。当预创建的线程都在处理任务后,缓冲池自动创建一定数量的新线程,用于处理更多任务。在任务处理完毕后,线程也不退出,而是继续保持在池中等待下一次的任务。当系统比较空闲时,大部分线程一直处于暂停状态,线程池自动销毁一部分线程,回收系统资源。
5. Linux网络编程:
网络传输一般都要使用TCP/IP协议,而socket是支持TCP/IP网络通信的基本操作单元,可以看作是不同主机之间进程进行双向通信的端点。TCP/IP协议常用三种socket:
· 数据包套接字SOCK_DGRAM:提供了一种无连接的服务,使用UDP协议进行数据传输
· 流套接字SOCK_STREAM:用于提供面向连接的可靠的数据传输服务,使用了TCP协议
· 原始套接字SOCK_RAW:可以读写内核没有处理的IP数据包,如果要访问其他协议发送的数据,必须使用原始套接字。
1) UDP套接字编程:
服务器端,首先调用socket函数创建一个Socket,接着调用bind函数将其与本机地址以及一个本地端口号绑定,然后执行接收信息循环体,调用recvfrom函数接收来自客户端的数据包。当接收到一个数据包时,判断是否是一个停止接收的信息,如果是则退出循环体;如果不是,就打印客户端发来的信息,再次进入循环。停止接收后,程序关闭Socket,退出程序。
客户端,首先调用socket创建一个Socket,然后执行发送信息的循环体,调用sendo函数给服务器端发送数据包,循环发送结束后,再发送一个停止信息,最后关闭socket,退出程序。
调试程序时可使用Wireshark软件捕获数据包。
编程中涉及的系统调用:
⑴ 建立socket:
int socket(int domain,int type,int protocol)
其中参数domain指明所使用的协议族,通常为AF_INET;type指定socket类型,一般使用SOCK_STREAM或SOCK_DGRAM;protocol通常赋值0;返回一个整型Socket描述符。
⑵ 配置绑定bind:
int bind(int socket,const struct sockaddr *address,socklen_t address_len)
函数bind()将Socket与本机上的一个端口关联,然后就可以在该端口监听服务请求。参数socket为socket函数返回的Socket描述符;address指向包含本机IP地址及端口号等信息的sockaddr类型的指针;addrlen常用sizeof(struct sockaddr)。结构体sockaddr:
struct sockaddr{
unsighed short sa_family; //协议族 AF_xxx
char sa_data[14]; //14字节协议地址
}
还有一种sockaddr_in结构体:
struct sockaddr_in{
short int sin_family; //地址族
unsighed short int sin_port; //端口号
struct in_addr sin_addr; //IP地址
unsigned char sin_zero[8]; //填充0以保持与struct sockaddr大小一致
}
可以使用下面的赋值实现自动获得本机IP地址和随机获取一个没有被占用的端口号:
my_addr.sin_port=0; //系统随机选择一个未被使用的端口号
my_addr.sin_addr.s_addr=INADDR_ANY; //填入本机IP地址
调用bind函数时,一般不要将端口号设为小于1024的值,因为是系统保留的端口号。
⑶ 字节顺序转换函数:
Internet上数据以高位字节优先顺序在网络上传输,对于内部以低位字节优先方式存储数据的机器,在Internet上传输数据时就需要进行转换,否则会出现数据不一致。
uint32_ htonl(uint32_t hostlong)
uint16_ htons(uint32_t hostshort)
uint32_ ntonl(uint32_t netlong)
uint16_ ntons(uint32_t netshort)
比如在服务器端程序中,可以使用:
sin.sin_addr.s_addr=htonl(INADDR_ANY)
sin.sin_port=htons(SERVER_PORT)
⑷ 数据传输:
ssize_t sendto(int socket,const void *message,size_t length, int flags, const struct sockaddr *dest_addr, socklen_t dest_len)
参数message是一个指向要发送数据的指针;参数length是以字节为单位的要发送数据的长度;flags一般情况下置0;dest_addr表示目的机的IP地址和端口号信息;dest_len一般赋值为sizeof(struct sockaddr)。
ssize_t recvfrom(int socket,void *restrict buffer,size_t length, int flags, struct sockaddr *restrict address, socklen_t *restrict address_len)
参数buffer是存放接收数据的缓冲区;参数length为缓冲区长度;flags也被置0;参数addres是一个struct sockaddr类型的变量,保存源主机的IP地址及端口号;参数address_len为sizeof(struct sockaddr),当函数返回时为实际存入Socket的数据字节数。
⑸ 关闭Socket:
int close(int fildes)
2) TCP套接字编程:
服务器端,首先调用socket创建一个Socket,接着调用bind函数将其与本机地址以及一个本地端口号绑定,然后调用listen函数在该socket上监听,进入等待客户端连接的循环体。
当accept函数接收到一个连接服务请求时,将生成一个新的socket,从新的socket上接收客户端发来的信息,并进行相关处理,关闭新的socket。执行完一次循环,接着开始下一次循环。
客户端,首先获得服务器的IP地址和端口号,调用socket函数创建一个Socket,接着调用connect函数与服务器建立连接,连接成功后向服务器发送信息,并从服务器接收发来的信息进行处理,最后关闭该Socket。
编程中涉及的系统调用:
⑴ 建立套接字队列:
在建立Socket与配置Socket步骤后,服务器端可使用listen函数使Socket处于被动监听模式,并为该Socket建立一个输入数据队列,将到达的服务请求保存在此队列中,直到程序处理。
int listen(int sockfd,int backlog)
参数backlog指定Socket队列的连接数,即队列的最大连接数目。
⑵ 等待连接:
在建立好输入队列后,服务器就调用accept函数,然后睡眠并等待客户的连接请求。服务器一般在循环体中处理连接,对于每一个连接,建立一个新的进程或者线程处理连接。
int accept(int sockfd,struct sockaddr *addr,socklen_t *addrlen)
参数addr是一个指向sockaddr_in变量的指针,该变量用来存放提出请求服务的主机信息,如果服务器对它不感兴趣,也可以指定为null;addrlen通常为指向值为sizeof(struct sockaddr _in)的整型数的指针变量,如果服务器不感兴趣,也可以指定为bull。函数调用成功则返回一个非负整数,为一个所接收的套接字描述符。
当accept函数监视的Socket收到连接请求时,Socket执行体将建立一个新的Socket,执行体将这个新的Socket和请求连接进程的地址联系起来,可以在新的Socket描述符上进行数据传输,而收到服务请求的初始Socket仍然继续在以前的Socket上监听。
⑶ 连接服务器:
面向连接的客户使用connect函数来配置Socket并与远端服务器建立一个TCP连接。
int connect(int sockfd,const struct sockaddr *addr,socklen_t addrlen)
参数addr是包含远端主机IP地址和端口号的指针;参数addrlen是远端地址结构的长度。
⑷ 数据传输:
面向连接的Socket使用send()和recv()函数进行数据传输。
ssize_t send(int sockfd,void *buf,size_t length, int flags)
参数msg是一个指向要发送数据的指针;参数len是以字节为单位的数据长度;flags一般情况下置0。函数返回实际上发送的字节数。
ssize_t recv(int sockfd,void *buffer,size_t length, int flags)
参数buf是存放接收数据的缓冲区;参数len是缓冲区的长度;flags一般也置0。函数返回实际上接收的字节数,当出现错误返回-1并置相应的errno。
3) 修改Socket缓冲区大小:
int setsockopt(int sockfd,int level,int optname,const void *optval,socklen_t optlen)
int getsockopt(int sockfd,int level,int optname,void *optval,socklen_t optlen)