图像处理与人工智能
机器学习、模式识别、人工智能中经常需要用到分类器,分类器是对样本进行分类的方法的统称,包含最近邻分类器、朴素贝叶斯分类器、决策树、逻辑回归、神经网络等算法。
一、最近邻分类器:
用于分类的最简单方法就是最近邻规则,即根据一个样本的最近邻距离将其进行分类。当涉及大量样本时,这种规则可能产生误差,但误差不超过最优误差的两倍。
1.最近邻算法NN:
设有n个训练样本,(X1,θ1)、(X2,θ2)、...、(Xn,θn),其中Xi的维数为d,θi为第i个样本的分类标签。有测试样本P:
d(P,Xk)=min{d(P,Xi)}
其中,i=1,2,...,n。模式P被分类为与Xk相关的类,θk。
假设训练集为三维样本,X1=(0.8,0.8,1)、X2=(1.0,1.0,1)、X3=(2.8,2.8,2),、...、X16=(3.5,1.0,3)等样本,其中前两个数给出样本的两个特征,第三个数给出样本的分类标签。如果有一个测试样本P=(3.0,2.0),求出P与所有训练样本的距离。使用欧几里得距离:
![]()
对点P和集合中任何一点之间的距离用上式计算,如P到X1的距离为:
![]()
在计算P点和所有其他点的距离后,P的最近邻为X16,和P之间的距离为1.12,属于类别3,因此P也属于类别3。
2.k最近邻算法kNN:
k最近邻算法是寻找k个最近邻,这k个最近邻中占绝大多数的类别为新样板的类别。如果选择适当的k值,k最近邻算法分类准确度会高于最近邻算法。当训练样本有噪声时,这种分类方法可以减小分类误差。
k值的选择是执行该算法的关键一步,对于大数据集,k可以选得更大以减小误差。k值可以通过试验来决定,可以从训练集中取出大量样本,然后选取不同的k值并对剩下的训练样本进行分类,并选择分类误差最小的那个k值。
3.改进的k最近邻算法MkNN:
这种算法也考虑k个最近邻,但根据它们与测试点的距离对这k个最近邻进行加权,因此也称距离加权k最近邻算法。与每个近邻相对应的权值定义为:
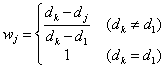
其中,j=1,2,...,k。wj取值在最近邻居的最大值1与最远邻居的最小值0之间。计算权值后,把测试样本P分配给k个邻居中代表各个类的点的权值之和最大的那个类。
加权算法用加权的服从多数准则代替了简单的服从多数准则。
4.模糊k最近邻算法:
在模糊最近邻算法中,使用了模糊集的概念。模糊集中,每个集合元素都附有一个隶属度函数,该函数的值在实数区间[0,1]内。
在模糊kNN算法中,模糊集是c个类。每个样本属于一个带有舒适度隶属度值的类i,这个隶属度值取决于该样本的k个邻居所在的类。
模糊kNN算法会找出测试点的k个最近邻,并给每个点对所有这些类分配一个类隶属度。分配隶属度的一种方法是在它们已知的类中分配隶属度1,其他类在分配隶属度0;分配隶属度的另一种方法是以样本与所有类的平均值之间的距离为基础进行分配。
对于出现在k个最近邻中的类,每个样本都有隶属度1,而对于其他类,隶属度0。测试样本对每个类都有隶属度,而它最终被分配给隶属度最高的那个类。
5.r最近邻算法:
也可以关注位于与兴趣点相距一定距离r内的所有邻居。给定点P,找出位于以P为球心r为半径的球内的数据子集;如果为空集,那么输出在整个数据集合在占多数的类;如果非空,就输出在此范围内的数据点中占多数的类。
如果感兴趣的点的最近邻也离得非常远,那么该点与这个邻居的关系不大。该算法可以用来识别离群者,如果一个样本与选定范围内的样本没有太多相似之处,就被当作离群者。半径r的选择非常重要。
6.高效最近邻算法:
最近邻算法十分耗时,尤其在训练样本数目很多时,为此研究了很多高效算法。
1)分支定界算法:
如果数据以有序方式进行存储,可以得到一个比当前更佳值更大的距离处的下界值,就不必再向下搜索,就能提高效率。
2)Cube算法:
在预处理阶段,样本被投影到各坐标轴上,待检查的初始立方体边长指定为l。提高迭代方式适当增加或减少l的值,很快就能找到精确baohk个点的立方体。
3)投影最近邻算法:
二、贝叶斯分类器:
贝叶斯是最佳分类器,所以非常常用,所得到的分类器能最大限度地减小平均误差概率。
1.贝叶斯理论:
X为未知类标签的样本,Hi为指定X属于哪个类的假设,如Hi是一个样本属于类Ci的假设。如果Hi的先验概率P(Hi)是已知的,为了给X分类,需要确定P(Hi|X),即得到样本X后,Hi发生的概率。
P(Hi)是Hi的先验概率,是在观测到X之前得到的;P(Hi|X)是以X为条件时Hi的后验概率,是基于其他信息的。P(X|Hi)是X以Hi为条件时的概率;而P(X)定义为P(X|Hi)的加权组合:
![]()
贝叶斯理论提供了由P(Hi)、P(X)、P(X|Hi)计算后验概率P(Hi|X)的方法:
![]()
其中一些概率是需要估计的,估计的方法常用贝叶斯方案和最大似然方案,贝叶斯方案中假设待估计的参数是随机变量并且先验概率已知,而最大似然方案认为参数是未知的确定性量。
2.朴素贝叶斯分类器:
朴素贝叶斯分类器是在每个特征都假设为相互独立的情况下基于贝叶斯理论的概率分类器。
分类器是一个条件概率模型p(C|F1,F2,...,Fn),类变量为C,Fn为几个特征变量。运用贝叶斯理论,改写为:
![]()
其中分母与C无关,并且特征量Fi的值已知,因此分母是一个有效常数;而分子就是联合概率模型p(C,F1,F2,...,Fn),重复使用条件概率的定义,联合概率模型表达式为:
![]()
在无关性前提下,类变量C的条件分布表达为:
![]()
其中,Z是只与F1,F2,...,Fn有关的比例系数,当特征值已知时Z是常数。
上式模型比较容易处理,式中有先验概率p(C)及独立概率分布p(Fi|C)。如果有k个类,并且p(Fi)的模型可以用r个参数表示,那么相关的朴素贝叶斯模型有(k-1)+nrk个参数。通常二元分类下k=2,以伯努利变量为特征量时r=1,这样朴素贝叶斯模型的参数个数为2n+1,其中n为用来预测的二元特征量的个数。
通常镛一个类中一个特征值的范围与所有类的特征值的范围之比来计算特征值的概率分布。
类的概率没有必要估计得非常准,整体分类器足够强壮来忽略朴素概率模型中的一些不足。