图像处理与人工智能
粒子群算法也称粒子群优化算法PSO(Particle Swarm Optimization),属于进化算法EA(Evolutionary Algorithm)的一种,实现容易、精度高、收敛快,是一种并行算法。它是从随机解出发,通过迭代寻找最优解,也是通过适应度来评价解的品质,它通过追随当前搜索到的最优值来寻找全局最优。
1995年,美国电气工程师Eberhart和社会心理学家Kenndy基于鸟群觅食行为提出了粒子群优化算法PSO。在PSO中,每个优化问题的潜在解都可以想象成搜索空间中的一只鸟,称为粒子,粒子主要追随当前的最优粒子在解空间中搜索。PSO初始化为一群随机粒子,即随机解,然后通过迭代找到最优解。
对PSO算法的改进也非常多,有增强算法自适应性的改进、增强收敛性的改进、增加多种群多样性的改进、增强局部搜索的改进、与全局优化算法相结合、与确定性的局部优化算法相融合等。实际改进中应用的方法有基于参数的改进,即对PSO算法的迭代公式的形式上改进;还有从粒子行为模式进行改进,即粒子之间的信息交流方式,如拓扑结构的改进、全局模式与局部模式的改进等;还有基于算法融合的粒子群算法的改进,算法融合可以引入其他算法的优点来弥补PSO算法的缺点,设计出求解的优化算法。
1. 基本粒子群算法实现:
粒子群算法是一个非常简单的算法,且能有效地够优化各种函数。此算法非常依赖随机过程,主要研究寻找全局最优点和有较高的收敛速度。
粒子群算法本质上是一种随机搜索算法,是群体智能中的一个新的分支,也是对简单社会系统的模拟。该算法能以较大概率收敛于全局最优解,适合在动态、多目标优化环境中寻优。
PSO中,每个优化问题的潜在解都是搜索空间中的一只鸟,称为粒子。所有粒子都有一个由被优化的函数决定的适值(fitness value),每个粒子还有一个速度决定它们飞行的方向和距离,然后粒子就追随当前的最优粒子在解空间中搜索。
1)算法原理:
设x为粒子起始位置,v为粒子飞行速度,p为搜索到的粒子的最优位置。PSO初始化为一群随机粒子,然后通过迭代找到最优解。在每一次迭代中,粒子通过跟踪两个极值来更新自己:第一个就是粒子本身所找到的最优解,这个解称为个体极值pbest;另一个极值是整个种群目前找到的最优解,这个极值是全局极值gbest。此外,也可以不用整个种群,而只用其中一部分作为粒子的邻居,那么所有邻居的极值就是局部极值,粒子始终跟随这两个极值变更自己的位置和速度,直到找到最优解。
假设在一个D维的目标搜索空间中,有N个粒子组成一个群落,其中第i个粒子为一个D维向量:
![]()
第i个粒子的飞行速度也是一个D维向量:
![]()
第i个粒子迄今为止搜索到的最优位置,即个体极值Pbest:
![]()
整个粒子群迄今为止搜索到的最优位置,即全局极值Gbest:
![]()
在找到这两个最优值时,粒子根据如下公式来更新自己的速度和位置:
![]()
![]()
其中,c1、c2为学习因子,也称加速常数(acceleration constant);r1、r2为[0,1]范围内的均匀随机数。
公式右侧包括三部分,第1部分为惯性inertia或动量momentum,代表了粒子有维持自己先前速度的趋势;第2部分为认知cognition,反映了粒子对自己历史经验的记忆或回忆,代表粒子有向自身历史最佳位置逼近的趋势;第3部分为社会social,反映了粒子间协同合作与知识共享的群体历史经验,代表粒子有向群体或邻近历史最佳位置逼近的趋势。
2)算法构成要素:
基本粒子群算法主要包括三个方面。
⑴粒子群编码方法:
基本粒子群算法使用固定长度的二进制符号串来表示群体中的个体,其等位基因是由二值符号集{0,1}所组成的。初始群体中各个个体的基因值可用均匀分布的随机数来生成。
⑵个体适应度评价:
通过确定局部最优迭代达到全局最优迭代,得出结果。
⑶基本粒子群算法的运行参数:
基本粒子群算法有7个运行参数需要提前设定。
·r:粒子群算法的种子数,可以随机生成,也可以固定为一个初始值,要求能涵盖目标函数范围
·m:粒子群群体大小,即群体中所含个体的数量,一般取20~100,在变量比较多时可以取100以上
·max_d:一般为最大迭代次数,以最小误差的要求满足的
·r1、r2:两个在[0,1]之间变化的加速度权重系数随机产生
·c1、c2:加速常数,取随机2左右的值
·w:惯性权重产生的
·vk、xk:一个粒子的速度和位移数值,用粒子群算法迭代出每一组数值
3)粒子群算法参数设置:
PSO算法的一个最大优点是不需要调节太多的参数,但其中的少数参数却直接影响着算法的性能和收敛性。目前,PSO算法研究还处于初始阶段,算法的参数设置在很大程度上还依赖于经验。
PSO参数包括群体规模m、微粒子长度l、微粒范围[-xmax,xmax]、微粒最大速度vmax、惯性权重w、加速常数c1和c2。
群体规模一般取20~40。试验表明,对于大多数问题,30个微粒就可以取得很好的结果,对较难的问题可以取到100或200.微粒数目越多,算法搜索的空间范围越大,也就容易发现全局最优解,但算法运行的时间也越长。
微粒长度l,即每个微粒的维数,由具体优化问题而定。
微粒范围[-xmax,xmax]由具体优化问题决定,通常将问题的参数取值范围设置为微粒的范围,微粒的每一维也可以设置不同的范围。
微粒最大速度vmax决定了微粒在一次飞行中可以移动的最大距离。如果值太大,微粒可能会飞过好解;如果值太小,微粒不能在局部好区间之外进行足够的搜索,导致陷入局部最优值。通常设定vmax=k*xmax,0.1≤k≤1,每一维都采用相同的设置方法。
惯性权重w使微粒保持运动惯性,取值范围通常为[0.2,1.2]。早期的试验将w固定为1,动态的惯性权重因子能够获得比固定值更为优越的寻优结果。目前采用较多的动态权重因子是线性递减权值策略:
![]()
式中,max_d为最大进化代数;fmax为初始惯性值;fmin为迭代至最大代数时的惯性权值。经典取值fmax=0.8,fmin=0.2。
加速常数c1和c2代表将每个微粒的统计加速项的权重,低的值允许微粒在被拉回之前可以在目标区域外徘徊,而高的权重值则导致微粒突然冲向或越过目标区域。c1和c2是固定常数,早期试验中一般取2,一般都限定二值相等并取值范围[0,4]。
4)算法流程:
⑴初始化粒子群,包括群体规模N、每个粒子的位置xi和速度vi
⑵计算每个粒子的适应度值Fit[i]
⑶对每个粒子,用它的适应度值Fit[i]和个体极值pbest(i)比较,如果Fit[i]>pbest(i),则用Fit[i]替换掉pbest(i)
⑷对每个粒子,用其适应度Fit[i]和全局极值gbest(i)比较,如果Fit[i]>gbest(i),则用Fit[i]替换掉gbest(i)
⑸根据公式更新粒子的位置xi和速度vi
⑹如果满足结束条件,误差足够好或达到最大循环次数,退出,否则返回⑵
粒子群算法中,粒子群规模大和迭代步数多未必就获得更高精度的解,要想获得精度高的解,关键是各个参数之间的合理搭配。
5)粒子群算法的MATLAB实现:
可以自定义实现粒子群算法的基本函数PSO:
[xm,fv]=PSO(fitness,N,c1,c2,w,M,D)
其中,fitness为待优化的目标函数,也称适应度函数;N为粒子数目;从
为学习因子1;c2为学习因子2;w为惯性权重;M为最大迭代次数;D为自变量的个数;xm为目标函数取最小值时的自变量;fv为目标函数的最小值。
2. 权重改进的粒子群算法:
在粒子群算法中,惯性权重w是最重要的参数,增大w的值可以提高算法的全局搜索能力,减小w的值可以提高算法的局部搜索能力。设计合理的惯性权重,是避免陷入局部最优并高效搜索的关键。常见的有自适应权重法、随机权重法和线性递减权重法。
1)自适应权重法:
粒子适应度是反应粒子当前位置优劣的一个参数。对应某些具有较高适应度的粒子pi,在pi所在的局部区域可能存在能够更新全部最优的点px,即px表示的解要优于全局最优。
为了使全局最优能够迅速更新,从而迅速找到px,应该减小粒子pi的惯性权重以增强其局部寻优能力;而对于适应度较低的粒子,当前位置较差,所在区域存在优于全局最优解的概率较低,为了跳出当前区域,应当增大惯性权重,增强全局搜索能力。自适应权重有两种方法。
①依据早熟收敛程度和适应值进行调整:
设定粒子pi的适应值为f,最优粒子适应度为fm,则粒子群的平均适应值为:
![]()
将由于平均适应值的粒子适应值求平均,记为f'svg,定义:Δ=|fm-f'svg|。
依据fi、fm、fsvg将群体分为三个子群,分别进行不同的自适应操作。其惯性权重调整为:
⑴如果fi优于f'svg,那么:
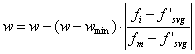
⑵如果fi由于f'svg,且次于fm,则惯性权重不变
⑶如果fi次于f'svg,则:
![]()
其中,k1、ke为控制参数,看
用来控制w的上限,k2主要用来控制调节能力。
当算法停止时,如果粒子的分布分散,则Δ比较大,w变小,此时算法局部搜索能力强,从而使得群体趋于收敛;若粒子的分布聚集,则Δ比较小,w变大,使得粒子具有较强的探查能力,从而有效地跳出局部最优。
②根据全局最优点的距离进行调整:
提出的算法中,粒子惯性权重不仅随迭代次数的增加而递减,还随距全局最优点距离的增加而递增。当粒子目标值分散时,减小惯性权重;当粒子目标值一致时,增加惯性权重。根据全局最优点的距离调整算法的基本步骤为:
⑴随机初始化种群中各个粒子的位置和速度
⑵评价每个粒子的适应度,将粒子的位置和适应度存储在粒子的个体极值pbest中,将所有pbest中最优适应值的个体位置和适应值保存在全局极值gbest中。
⑶更新粒子位移和速度:
![]()
![]()
⑷更新权重:
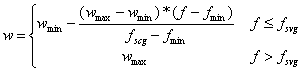
式中,f为粒子实时的目标函数值;fsvg和fmin分别为当前所有粒子的平均值和最小目标值。
⑸将每个粒子的适应值与粒子的最好位置比较,如果相近,则将当前值作为粒子最好的位置。比较当前所有的pbest和gbest,更新gbest。
⑹当算法达到其停止条件,则停止搜索并输出结果,否则返回到第⑶步继续搜索。
2)随机权重法:
随机权重法的原理是将标准PSO算法中的惯性权重w设定为随机数,这种方法的优势在于,当粒子在起始阶段就接近最好点,随机产生的w可能产生相对较小的值,由此加快算法的收敛速度,而且能克服w线性递减造成的算法不能收敛到最好点的局限。
惯性权重的计算步骤为:
⑴随机设置各个粒子的速度和位置
⑵评价每个粒子的适应度,将粒子的位置和适应值存储在粒子的个体极值pbest中,将所有pbest中最优适应值的个体位置和适应值保存在全局极值gbest中
⑶更新粒子位移和速度:
![]()
![]()
⑷更新权重:
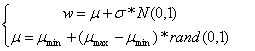
其中,N(0,1)为标准状态分布的随机数。
⑸将每个粒子的适应值与粒子的最好位置比较,如果相近,则将当前值作为粒子最好的位置。比较当前所有的pbest和gbest,更新gbest。
⑹当算法达到其停止条件,则停止搜索并输出结果,否则返回到第⑶步继续搜索。
3)线性递减权重法:
针对PSO算法容易早熟及后期容易在全局最优解附近产生振荡现象,提出了线性递减权重法,即使惯性权重依照线性从大到小的递减。计算步骤为:
⑴随机设置各个粒子的速度和位置
⑵评价每个粒子的适应度,将粒子的位置和适应度存储在粒子的个体极值pbest中,将所有pbest中最优适应值的个体位置和适应值保存在全局极值gbest中。
⑶更新粒子位移和速度:
![]()
![]()
⑷更新权重:
![]()
⑸将每个粒子的适应值与粒子的最好位置比较,如果相近,则将当前值作为粒子最好的位置。比较当前所有的pbest和gbest,更新gbest。
⑹当算法达到其停止条件,则停止搜索并输出结果,否则返回到第⑶步继续搜索。
3. 混合粒子群算法:
混合PSO就是将其他进化算法或传统优化算法等应用到PSO中,用于提高粒子多样式、增强粒子的全局探索能力,或者提高局部开发能力、增强收敛速度与精度。一般是利用其他优化技术自适应调整收缩因子/惯性权重、加速常数等,或将PSO与进化算法操作算子或其他技术结合。
1)基于杂交的算法:
基于杂交的算法是借鉴遗传算法中杂交的概念,在每次迭代中,根据杂交率选取指定数量的粒子放入杂交池内,池内的粒子随机地两两杂交,产生同样数目的子代粒子,并用子代粒子代替父代粒子。基于杂交的混合粒子群算法步骤为:
⑴随机设置各个粒子的速度和位置
⑵评价每个粒子的适应度,将粒子的位置和适应度存储在粒子的个体极值pbest中,将所有pbest中最优适应值的个体位置和适应值保存在全局极值gbest中。
⑶更新粒子位移和速度:
![]()
![]()
⑷将每个粒子的适应值与粒子的最好位置比较,如果相近,则将当前值作为粒子最好的位置。比较当前所有的pbest和gbest,更新gbest。
⑸根据杂交概率选取指定数量的粒子,并将其放入杂交池中,池中的粒子随机两两杂交产生同样数目的子代粒子。子代的位置和速度计算公式为:
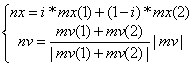
其中,mx为父代粒子位置;nx为子代粒子的位置;i为0~1之间的随机数;mv为父代粒子的速度;nv为子代粒子的速度。保持pbest和gbest不变。
⑹当算法达到其停止条件,则停止搜索并输出结果,否则返回到第⑶步继续搜索。
2)基于自然选择的算法:
基于自然选择的算法是借鉴自然选择的机理,在每次迭代中,根据粒子群适应值将粒子群排序,用群体中最好的一半粒子替换最差的一半粒子,同时保留原来每个个体所记忆的历史最优值。基于自然选择的混合粒子群算法步骤为:
⑴随机设置各个粒子的速度和位置
⑵评价每个粒子的适应度,将粒子的位置和适应度存储在粒子的个体极值pbest中,将所有pbest中最优适应值的个体位置和适应值保存在全局极值gbest中。
⑶更新粒子位移和速度:
![]()
![]()
⑷将每个粒子的适应值与粒子的最好位置比较,如果相近,则将当前值作为粒子最好的位置。比较当前所有的pbest和gbest,更新gbest。
⑸根据适应值对粒子群排序,用群体中最好的一半粒子替换最差的一半粒子,同时保留原来每个个体所记忆的历史最优值。
⑹当算法达到其停止条件,则停止搜索并输出结果,否则返回到第⑶步继续搜索。
3)基于免疫的粒子群算法:
基于免疫的粒子群算法是在免疫算法的基础上采用粒子群优化对抗体群体进行更新,可以解决免疫算法收敛速度慢的缺点。基于免疫的混合粒子群算法步骤为:
⑴缺点学习因子c1和c2、粒子(抗体)群体个数M
⑵由logistic回归分析映射产生M个粒子(抗体)xi及其速度vi,其中i=1,2,...,N,最后形成初始粒子(抗体)群体P0。
⑶生产免疫记忆粒子(抗体)。计算当前粒子(抗体)群体P中粒子(抗体)的适应值并判断算法是否满足结束条件,如果满足则结束并输出结果,否则继续运行。
⑷更新局部和全局最优解,并根据下式更新粒子位移和速度:
![]()
![]()
⑸由logistic映射产生N个新的粒子(抗体)。
⑹基于浓度的粒子(抗体)选择。用群体中相似抗体百分比计算生产M+M个新粒子(抗体)的概率,依照概率大小选择N个粒子(抗体)形成粒子(抗体)群P。然后转入⑶。
4)基于模拟退火的算法:
基于模拟退火的算法在搜索过程中具有突跳的能力,可以有效地避免搜索陷入局部极小解。
基于模拟退火的混合粒子群算法步骤为:
⑴随机设置各个粒子的速度和位置
⑵评价每个粒子的适应度,将粒子的位置和适应度存储在粒子的个体极值pbest中,将所有pbest中最优适应值的个体位置和适应值保存在全局极值gbest中。
⑶确定初始温度
⑷根据下式确定当前温度下各粒子pi的适应值:
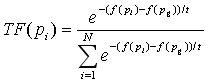
⑸从所有pi中确定全局最优的替代值p'i,并根据下面的公式更新各粒子的位置和速度:
![]()
![]()
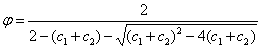
⑹计算粒子目标值,并更新pbest和gbest,然后进行退温操作
⑺当算法达到其停止条件,则停止搜索并输出结果,否则返回到第⑷步继续搜索。
⑻初始温度和退温方式对算法有一定的影响,一般采用如下所示的初始温度和退温方式:
![]()