编程语言
C#编程语言基础
C#面向对象与多线程
C#数据及文件操作
JavaScript基础
JavaScript的数据类型和变量
JavaScript的运算符和表达式
JavaScript的基本流程控制
JavaScript的函数
JavaScript对象编程
JavaScript内置对象和方法
JavaScript的浏览器对象和方法
JavaScript访问HTML DOM对象
JavaScript事件驱动编程
JavaScript与CSS样式表
Ajax与PHP
ECMAScript6的新特性
Vue.js前端开发
PHP的常量与变量
PHP的数据类型与转换
PHP的运算符和优先规则
PHP程序的流程控制语句
PHP的数组操作及函数
PHP的字符串处理与函数
PHP自定义函数
PHP的常用系统函数
PHP的图像处理函数
PHP类编程
PHP的DataTime类
PHP处理XML和JSON
PHP的正则表达式
PHP文件和目录处理
PHP表单处理
PHP处理Cookie和Session
PHP文件上传和下载
PHP加密技术
PHP的Socket编程
PHP国际化编码
MySQL数据库基础
MySQL数据库函数
MySQL数据库账户管理
MySQL数据库基本操作
MySQL数据查询
MySQL存储过程和存储函数
MySQL事务处理和触发器
PHP操作MySQL数据库
数据库抽象层PDO
Smarty模板
ThinkPHP框架
Python语言基础
Python语言结构与控制
Python的函数和模块
Python的复合数据类型
Python面向对象编程
Python的文件操作
Python的异常处理
Python的绘图模块
Python的NumPy模块
Python的SciPy模块
Python的SymPy模块
Python的数据处理
Python操作数据库
Python网络编程
Python图像处理
Python机器学习
TensorFlow深度学习
Tensorflow常用函数
TensorFlow用于卷积网络
生成对抗网络GAN
- TensorFow基础:
- TensorFlow的Hello:
- TensorFlow中的图:
- Session:
- 常量与变量:
- TensorFlow中的tf.placeholder:
- Tensor对象:
- Operation对象:
- TensorFlow流程控制:
- TensorFlow位运算:
- TensorFlow字符串:
- 高维Tensor对象的工具函数:
- 前馈卷积神经网络:
- 常见卷积神经网络:
- TensorFlow数据存取:
- TensorFlow数据预处理:
- TensorFlow模型训练:
- TensorBoard可视化工具:
- 移植TensorFlow模型到Android端:
一、TensorFlow基础:
TensorFlow是由Google Brain团队开发的一个开源的深度学习框架,为机器学习和深度学习提供了强大的支撑。TensorFlow结构灵活,用户可以轻松地将计算任务分配给CPU、GPU、TPU及服务器集群等。 TensorFlow采用符号式编程,一般先定义各种变量,然后建立一个数据流图,在数据流图中规定各个变量之间的计算关系,最后需要对数据流图进行编译。运行时需要将运算数据输入,才能在整个模型中形成数据流,从而形成输出值。
1. TensorFlow的Hello:
示例代码:
import tensorflow as tf # 将TensorFlow库引入
txt_tf=tf.constant('hello world!',ftype=tf.string,name='input') # 字符串以常量方式存入
with tf.Session() as sess: # 创建Session对象以管理TensorFlow中的图
txt=sess.run(txt_tf) # 启动图并将图中节点数据从图中引出成为Python对象
print(tx.decode()) # 将取出的Python对象打印出来
TensorFlow框架中也有int、float、string等数据类型,但是不能将Python中的数据类型与TensorFlow中的数据类型运算,只能先将Python中的数据转换为TensorFlow中的数据类型,由TensorFlow计算出结果,再从TensorFlow图中取出来。下面是矩阵运算示例:
import tensorflow as tf
A=[[1,2,3],[4,5,6]]
B=[[1,1],[1,1],[1,1]]
A_tf=tf.constant(A,dtype=tf.float32,name="A")
B_tf=tf.constant(B,dtype=tf.float32,name="B")
C_tf=tf.matmul(A_tf,B_tf)
with tf.Session() as sess:
C=sess.run(C_tf)
print(C)
2. TensorFlow中的图:
在TensorFlow中,会定义默认图,用户可以显式定义图,并将定义图作为默认图。
TensorFlow的图包含tf.Operation对象集合,一个tf.Operation对象表示一个计算单元,如加减乘除。TensorFlow中的图还包含tf.Tensor对象,表示参与运算的数据,这些数据在tf.Operation节点中参与运算,并在图的各个路经传递。
图中还可以包含任意多个集合,比如TensorFlow框架中创建了一个名为tf.GraphKeys.GLOBAL _VARIABLES的集合,所有变量对象(tf.Variable)在创建时都会放入到对应图的tf.GraphKeys. GLOBAL_VARIABLES的集合中。用户也可以创建自定义名城的集合,将需要共享的Tensor对象放入到自定义集合中,这样可以在代码的任意地方将共享的Tensor对象取出来。
TensorFlow框架区分不同的图是为了方便模块化管理,实际项目中往往一个图就够用了,可以通过函数tf.get
import tensorflow as tf
不同图中的数据和计算节点相互引用时会出现错误。在构建图时,各个数据对象和计算节点对象必须在当前图中,不同图之间的资源是不能交叉引用的。
A=[[1,2,3],[4,5,6]]
B=[[1,1],[1,1],[1,1]]
my_graph=tf.Graph()
with my_graph.as_default():
A_tf=tf.constant(A,dtype=tf.float32,name="A")
B_tf=tf.constant(B,dtype=tf.float32,name="B")
C_tf=tf.matmul(A_tf,B_tf)
print('C_tf.graph is my_graph:',C_tf.graph is my_graph)
with tf.Session(graph=my_graph) as sess:
C=sess.run(C_tf)
print(C)
TensorFlow主要使用静态图机制,顺序执行的TensorFlow框架的计算函数其实只是在构造图,计算并不会马上执行,只有调用了tf.Session对象的run函数时才启动图,图中的各个计算节点和数据按图执行。
使用静态图,当图构建完成时网络就已经确定,图结构不会再发生变化,这样底层库能将运算优化。但静态图也有缺点,定义网络模型要等图构建完成才能执行,给调试带来不便。目前,一些项目和模块也可以使用动态图。
3. Session:
TensorFlow的Session对象是一个上下文环境,Session对象管理着图中的资源对象、队列及文件读写等。在Session环境中可以取出关联的图中的数据对象,也可以执行关联图中指定的计算节点。
1)将Session对象关联Graph对象:
每个Session对象只能关联一个图,并且只能取这个图中的数据对象和执行这个图中的计算节点对象。如果程序中有多个图,则需要多个Session对象与之关联。将Session对象关联Graph对象后,可以在创建Session时,将Graph对象传入Session对象的构造函数,示例:
my_graph=tf.Graph()
sess=tf.Session(graph=my_graph)
如果创建Session对象时,没有在构造函数中传入Graph对象,则会使用默认的图关联到创建的Session对象中。Session对象只能对其关联图中的资源对象进行读写和运行。
不同的图由不同的Session对象关联管理,Session对象管理着很多资源对象。因此当不再使用Session对象时,需要调用Session对象的close()函数将其关闭。如果使用with tf.Session() as sess的方式创建和使用Session对象,则不需要显式调用close()函数。
2)Session参数配置:
Session对象掌管着图资源和硬件资源的使用和分配,用户可以通过向Session对象传递配置参数来管理硬件资源的分配。在Session的构造函数中,参数config用于将用户对网络训练时的一些参数进行配置,传入的是tf.ConfigProto对象、示例:
tf_config=tf.ConfigProto()
with if.Session(config==tf_config) as sess:
pass
接下来列举一些常用的参数设置,代码:
import tensorflow as tf
tf_config=tf.ComfigProto()
# GPU设置
tf_config.gpu_option.allow_growth=True # 根据实际代码运行情况动态占用GPU空间
tf_config.gpu_option.per_process_gpu_memory_fraction=0.9 # 设显存占用比例
tf_config.log_device_placement=True # 设定是否打印当前GPU、CPU的分配情况
tf_config.allow_soft_placement=True # 设定是否允许自动分配GPU和CPU
with if.Session(config==tf_config) as sess:
pass
默认情况下,为了得到更多的缓存空间,降低显存复制数据带来的耗时瓶颈,TensorFlow会一次性占满所有的显存空间。当有多块CPU卡时,即使其他GPU没参与训练,也会被占满。
因此,如果使用单机多卡训练多个网络模型时,很有必要将gpu_option.allow_growth设为True。需要注意,一旦TensorFlow得到显存的某块空间的使用权,就不会将已占用显存空间释放,这时为了避免出现更多显存空间碎片。
当gpu_option.allow_growth设为True时,刚开始只占用很少的显存空间,随着构建图过程中占用更多的实际空间,会逐步申请更多的显存空间,直到满足训练需要的大学为止。
可以为TensorFlow指定GPU占用比例,也可以在代码中指定每个代码块在哪块GPU卡中执行,也即一机多卡时所有卡对TensorFlow都“可见”。用户可以为TensorFlow训练进程指定可见的GPU,这样就可以让不同的训练进程只“看到”指定的GPU,其他GPU卡则“不可见”。设置方法:
os.environ['CUDA_VISIBLE_DEVICES']='0,1' # 将第0块GPU和第1块GPU设置为可见
os.environ['CUDA_VISIBLE_DEVICES']='0' # 只将第0块GPU设置为可见
也可以在训练命令时,加入指定的可见GPU的ID。比如代码:
CUDA_VISIBLE_DEVICES=0,1 python train.py
上述代码为train.py训练文件指定第0块GPU和第1块GPU可见。
4. 常量与变量:
1)TensorFlow中的常量:
常量一旦初始化后,就不能修改其值。TensorFlow中常量定义使用tf.constant,其函数原型:
tf.constant(
value,
dtype=None,
shape=None,
name='Const',
verify_shape=False
)
tf.constant中各个参数的类型及含义:
| 参数 | 类型 | 含义 |
|---|---|---|
| value | list或常数 | 常数的初始值,可以传入list对象或常数 |
| dtype | tf.Dtype | 常见有tf.string、tf.int16、tf.int32、tf.int64、tf.float16、tf.float32、tf.float64、tf.int8、tf.uint8、tf.bool等 |
| shape | list | 如果是一个数,则shape=[];如果是长度为n的数组,则shape=[n];如果是n行m列矩阵,则shape=[n,m];依次类推。 |
| name | string | 当前常量的名称 |
| verify_shape | bool | 是否对shape验证,验证实际维度与设置是否一致 |
import tensorflow as tf
input=[[1,2,3],[2,3,4]]
input_tf=tf.constanr(input)
#打印查看常量的shape
print(input_tf.get_shape().as_list())
print(input_tf.dtype)定义input_tf常量时,只传入了常量值,其他使用默认值,dtype根据数据类型自动判断为tf.int32,shape根据维度自动推导shape=[2,3]。默认不对shape验证。输出为:
[2, 3]
<dtype: 'int32'>如果常量类型为float32,shape设置为[2,3],代码为:
input_tf=tf.constanr(input, dtype=tf.float32, shape=[3,2])
with tf.Session() as sess:
print("input_tf value:\n",sess.run(input_tf))输出:
input_tf value:
[[1. 2.]
[3. 2.]
[3. 4.]]可见,自定义shape后,相当于对常量做了reshape操作。如果设置的shape的某个维度超过对应的实际shape维度,则会按照最后一个值做扩充。例如shape=[5,2],输出:
[[1. 2.]
[3. 2.]
[3. 4.]
[4. 4.]
[4, 4.]]2)TensorFlow中的变量:
变量是可以随时修改值的对象。
①通过tf.Variable对象创建变量:
TensorFlow中,变量可以通过创建tf.Variable对象或者调用tf.get_variable函数来创建。其中,tf.Variable对象的构造函数为:
_init_(
initial_value=None,
trainable=True,
collections=None,
validate_shape=True,
caching_device=None,
name=None,
variable_def=None,
dtype=None,
expected_shape=None,
import_scope=None,
constraint=None
)tf.Variable对象的构造函数中的参数比较多,但常用的参数并不多。需要关注的有:
· initial_value:变量初始化值,可以为TensorFlow对象,也可以是可转换为Tensor对象的Python对象
· trainable:bool类型,指定当前变量是否可训练,默认True。如为True,在训练模型反向传播时会自动更新,并且会将此变量加入集合tf.GraphKeys.TRAINABLE_VARIABLES中。
· collections:list类型,其中的对象为集合的key值。当此变量加入指定集合中,默认会加入tf
· name:字符串类型,为此变量指定名称。
· dtype:tf.Dtype类型,指定此变量的数据类型。
示例:
import tensorflow as tf
input=[[1,2,3],[2,3,4]]
input_tf=tf.Variable(input,dtype=tf.float32,name="input")
print("input_tf shape:",input_tf.get_shape().as_list())
print("input_tf dtype:",input_tf.dtype)
with tf.Session() as sess:
sess.run(tf.global_variables_inializer())
print("input_tf value:\n",sess.run(input_rf))输出:
input_tf shape: [2,3]
input_tf dtype:
input_tf value:
[[1. 2. 3.]
[2. 3. 4.]]在包含变量的图创建完成后,需要在执行计算之前为变量执行赋值操作,即执行sess.run
②通过tf.get_variable函数创建变量:
变量创建的另一种方法是使用tf.get_variable函数,与tf.Variable对象创建变量的区别在于:如果当前命名空间没有指定名称的变量,tf
_init_(
name,
shape=None,
dtype=None,
initializer=None,
regularizer=None,
trainable=True,
collections=None,
caching_device=None,
partitioner=None,
validate_shape=True,
use_resource=None,
custom_getter=None,
constraint=None
)函数tf.get_variable同样有很多参数,实际用到的不多。
· name:创建新的变量或者已存在的变量的名称。
· shape:创建新的变量或者已存在的变量的shape。
· dtype:创建新的变量或者已存在的变量的数据类型。
· initializer:如果是创建新的变量,则使用的初始化方法。
· trainable:bool类型,默认True。如果是True,训练时会在反向传播时自动更新,并且会加入图的tf.GraphKeys.TRAINABLE_VARIABLES集合中。
· collections:list类型,其中的对象为集合的key值。当此变量加入指定集合中,默认会加入tf
示例代码:
import tensorflow as tf
input=[[1,2,3],[2,3,4]]
#创建变量初始化器
initializer=tf.constant_initializer(input)
#创建变量
input_tf=tf.get_variable(name='input',shape=[2,3],initializer=initializer)
print("input_tf shape:",input_tf.get_shape().as_list())
print("input_tf dtype:",input_tf.dtype)
with tf.Session() as sess:
sess.run(tf.global_variables_inializer())
print("input_tf value:\n",sess.run(input_rf))输出与前面使用tf.Variable创建的一样。
注意,使用tf.get_variable创建变量时,如果是创建新变量,需要指定shape参数,否则会抛出错误。
③使用tf.Variable与tf.get_variable创建变量的区别:
在相同的命名空间,使用tf.Variable定义多个相同名称的变量,会自动创建新的变量,并且新的变量名称以“_1”、“_2”递增的方式作为后缀。创建的新变量与原来的变量指向的并不是同一个地址空间的变量。
④变量初始化方法:
tf.Variable是通过直接传入初始值的方式来指定初始化的值;而tf.get_variable则需要指定初始化器来实现初始化值。常用的初始化方法:
· tf_constant_initializer:按指定的常数来初始化变量,需要传入指定的常数。
· tf.ones_initializer:将变量中所有元素的初始值设置为1。
· tf.orthogonal_initializer:如果变量维度N=2,则以正交矩阵的方式初始化变量;如果维度N>2,则先reshape到[shape[0]xshape[1]x...xshape[N-1]xshape[N]],按正交矩阵方式初始化,然后再reshape回到[shape[1],shape[1],...,shape[N]]。
· tf.random_normal_initializer:按照随机正态分布的方式初始化变量。
· tf.random_uniform_initializer:按照随机均值分布的方式初始化变量。
· tf.truncated_normal_initializer:以截断正态分布的方式初始化变量。
· tf.zeros_initializer:将变量中所有元素的初始值设置为0。
· tf.contrib.layers.xavier_initializer:按照xavier算法初始化设置,在卷积核的初始化中常用到这种初始化方法。
⑤变量修改值:
变量值可以随时修改。在TensorFlow中,可以使用变量的assign函数为变量赋值。示例:
import tensorflow as tf
input=[[1,2,3],[2,3,4]]
input_tf=tf.Variable(input,dtype=tf.float32,name="input")
#将变量中每个值加1
add_one_tf=input_tf+1
#将计算结果赋值给input_tf
assign_op=input_tf.assign(add_one_tf)
with tf.Session() as sess:
sess.run(tf.globe_variables_initializer())
#由于赋值计算也是图中一个节点,需要显式指定执行赋值操作才能生效
_,input_v=sess.run([assign_op,input_tf])
print(input_v)赋值也是一个计算节点,赋值计算不在执行的路经中,那么需要显式地在Session对象的eun函数中执行,否则赋值操作不会生效。
5. TensorFlow中的tf.placeholder:
TensorFlow中有一类特殊节点,既可以看成常量也可以看成变量,就是tf.placeholder。tf.placeholder其实是一个占位符,它提前在图中占位,但是不需要给它初始化值。将数据填入到占位符后,其值在图中就不能再修改,但是在图之外又可以不断传入不同的值。在图运行时,可以动态设置tf.placeholder的值。
比如,在训练时要不断向图中传入不同的数据,这时可以选择tf.placeholder提前占位,然后在训练时不断将tf
tf.placeholder(
ftype,
shape=None,
name=None
)
下面是一个矩阵乘法的示例:
import tensorflow as tf
B=[[1,1],[1,1]],[1,1]]
A_tf=tf.placeholder(dtype=tf.float32,shape=[2,3],name='A')
B_tf=tf.constanr(B,dtype=tf.float32,shape=[3,2],name='B')
C_tf=tf.matmul(A_tf,B_tf)
with tf.Session() as sess:
A1=[[1,2,3],[1,2,3]]
A2=[[4,5,6],[4,5,6]]
A_list=[A1,A2]
for A in A_list:
C=sess.run(C_tf,feed_dict={A_rf:A})
print('\n',C)
执行矩阵乘法时,将占位符A_rf的值通过feed_dict参数传入。feed_dict是一个字典对象,所有的占位符都可以通过这个参数传入。代码执行后输出:
[[6. 6.]
[6. 6.]]
[[15. 15.]
[15. 15.]]
注意,当执行的路经包含占位符时,那么所有被包含的占位符必须要传入具体值,即需要通过feed_dict把所有路经中包含的占位符的值传入。
6. Tensor对象:
TensorFlow中,tf.Tensor对象是数据对象的句柄。数据对象包括输入的常量和变量,以及计算节点的输出数据对象。所有Python语言中的常见的数据需要转为TensorFlow中的Tensor对象后,才能使用TensorFlow框架中的计算节点。
Tensor使用中文就是张量,零维度张量表示的是标量,一维张量表示的是向量,二维张量表示的是矩阵。在TensorFlow中,训练神经网络模型时,常见的Tensor维度为四维。常见四维Tensor的shape为[batch, height, width, channels],即一个Batch的输入图片数量,网络层输出特征图的高度、宽度及通道数。
TensorFlow中,Tensor对象可以存储任意维度的张量,图中参与运算的数据都是Tensor对象。Tensor对象往往是一个计算操作节点(Operation对象,简写op)的输出,输入其实也可以看成取数据op的输出。完成构图后,获取指定名称的Tensor对象,查找指定名称的Tensor对象的示例:
import tensorflow as tf
data=[[1,2],[3,4]]
#定义变量Tensor
A_tf=tf.Variable(data,name='A')
#定义常量Tensor
B_tf=tf.constant(data,name='B')
#根据Tensor的名称获取Tensor
A_tmp=tf.get_default_graph().get_tensor_by_name('A:0')
B_tmp=tf.get_default_graph().get_tensor_by_name('A:0')
#将查找得到的Tensor对象做矩阵乘法
C_tf=tf.matmul(A_tmp,B_tmp)
#打印Tensor对象
print('Tensor named "A:0": ',A_tmp)
print('Tensor named "B:0": ',B_tmp)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
A_v,B_v,C_v=sess.run([A_tmp,B_tmp,C_tf])
print('\n Tensor named "A:0" value: \n',A_v)
print('\n Tensor named "B:0" value: \n',B_v)
print('\n Matmul output: \n',C_v)
1)Python对象转Tensor对象:
Python中的内置数据类型是不能直接放入TensorFlow框架中参与计算的,因为TensorFlow计算之前需要先构图,而只有Tensor对象和Operation对象才能参与构图。因此,需要一个接口函数,将Python中的对象转为TensorFlow中的Tensor对象。
在TensorFlow中,函数tf.convert_to_tensor用于将Python基本数据类型对象转为Tensor对象。tf.convert_to_tensor并不能将所有的Python对象转换成Tensor对象,只能转换指定数据类型的对象。内置的基本数据类型int、float、string、list及Numpy库的数组等都可以使用tf.convert_to_tensor函数转换,函数原型为:
tf.convert_to_tensor(
value,
dtype=None,
name=None,
preferred_dtype=None
)
其中参数:
· value:需要转为Tensor对象的数据。
· dtype:指定Tensor对象的数据类型,如果未指定则根据value值来判断。
· name:转成Tensor后的名称。
· preferred_dtype:返回的Tensor对象指定备选的数据类型。如果dtype为None,该参数才生效。
示例:
import tensorflow as tf
#定义python的字符串对象
str_py='hello world'
#将字符串对象转为Tensor对象
str_tf=tf.convert_to_tensor(str_py,dtype=tf.string)
print('str_tf=',str_tf)
with tf.Session() as sess:
#Tensor对象取出来的是字符串对应的字节对象
str_bytes=sess.run(str_tf)
str_v=str_bytes.decode()
print(str_v)
输出结果:
str_tf=Tensor("Const:0", shape=(), dtype=string)
hello world
下面示例为Python的list对象转为Tensor对象:
import tensorflow as tf
#定义python的list对象
list_py=[[1,2,3],[4,5,6]]
#将list对象转为Tensor对象,指定数据类型float32
list_float32_tf=tf.convert_to_tensor(list_py,dtype=tf.float32)
#将list对象转为Tensor对象,并自动推断数据类型
list_infer_tf=tf.convert_to_tensor(list_py)
print('list_float32_tf=',list_float32_tf)
print('list_infer_tf=',list_infer_tf)
with tf.Session() as sess:
#Tensor对象取出来的是字符串对应的字节对象
float32_list,infet_list=sess.run([list_float32_tf,list_infer_tf])
print('\n float32_list:\n',float32_list)
print('\n infer_list:\n',infer_list)
输出显示:
list_float32_tf=Tensor("Const:0", shape=(2,3), dtype=float32)
list_infer_tf=Tensor("Const_1:0", shape=(2,3), dtype=int32)
float32_list:
[[1. 2. 3.]
[4. 5. 6.]]
infer_list: [[1. 2. 3.]
[4. 5. 6.]]
2)Tensor对象转Python对象:
在TensorFlow中各个计算节点(Operation对象)只能对Tensor对象做运算,对TensorFlow图中的Tensor做运算只能用框架自带的计算节点运算。但实际项目中,可能需要对图中某个Tensor对象做一些运算处理并返回。这时,需要将Tensor对象转为Python对象,计算后转为Tensor对象返回。
在TensorFlow框架中,提供了函数tf.py_func实现自动将Tensor对象转为Python对象,并作为Python函数的形参传入,同时Python函数返回的结果又自动转为Tensor对象返回。也就是说,tf.py_func函数能执行指定的Python函数,并自动将Tensor对象转为Python对象,再将返回的Python对象转为Tensor对象。tf.py_func函数原型:
tf.py_func(
func,
inp,
Tout,
stateful=True,
name=None
)
各个参数的含义及类型:
· func:Python函数类型,指定要执行的函数
· inp:list类型,list里面存放的是Tensor对象,用于传入func函数作为形参
· Tout:list类型或单个对象,存放的是TensorFlow数据类型,用于描述func函数返回数据转为Tensor对象后的数据类型。
· stateful:bool类型,默认True。如果设置为True,则该函数被认为是与状态有关的。如果函数与状态无关,则相同的输入会产生相同的输出。
· name:当然Operation的名称。
下面以自定义两个Tensor对象做加法运算示例:
import tensorflow as tf
def my_add_func(A,B):
#查看传入参数的数据类型
print('type(A)=',type(A))
print('type(B)=',type(B))
C=A+B
return C
#定义Tensor对象
A_tf=tf.constant([[1,1],[1,1]],dtype=tf.int64)
B_tf=tf.constant([[2,2],[2,2]],dtype=tf.int64)
C_tf=tf.py_funct(my_add_func,[A_tf,B_tf],tf.int64)
with tf.Session() as sess:
C=sess.run(C_tf)
print(C)
输出结果:
type(A) = <class 'numpy.ndarray'>
type(B) = <class 'numpy.ndarray'>
[[3 3]
[3 3]]
3)SparseTensor对象:
在TensorFlow中,SparseTensor对象表示稀疏矩阵。SparseTensor对象通过3个稠密矩阵indices、values、dense
· indices:数据类型为int64的二维Tensor对象,shape为{N,ndime]。indices保存的是非零值的索引,即稀疏矩阵中除了indices保存的位置外,其他位置均为0。
· values:一维Tensor对象,其shape为[N],对应的是稀疏矩阵中indices索引位置中的值。
· dense_shape:数据类型为int64的一维Tensor对象,其维度[ndims],用于指定当前稀疏矩阵对应的shape。
生成稀疏矩阵的示例:
import tensorflow as tf
#定义Tensor对象
indices_tf=tf.constant([[0,0],[1,1]],dtype=tf.int64)
values_tf=tf.constant([1,2],dtype=tf.float32)
dense_shaoe_tf=tf.constant([3,3],dtype=tf.int64)
sparse_tf=tf.SparseTensor(indices=indices_tf,values=values_tf,dense_shape=dense_shape_tf)
dense_tf=tf.sparese_tense_to_dense(sparse_tf,default_value=0)
with tf.Session() as sess:
sparse,dense=sess.run([sparse_tf,dense_tf)
print('sparse:\n',sparse)
print('dense:\n',dense)
代码中使用tf.sparese_tense_to_dense()将稀疏矩阵转为稠密矩阵。输出结果:
parse:
SparseTensorValue(indices=array([[0,0],[1,1]],dtype=int64),values=array([1.,2.],
dtype=float32),dense_shape=array([3,3],ftype=int64))
dense:
[[1. 0. 0.]
[0. 2. 0.]
[0. 0. 0.]]
4)强制转换Tensor对象数据类型:
在TensorFlow中,函数tf.to_int32、tf.to_int64、tf.to_float、tf.to_double、tf.to_bfloat16、tf.to_complex64、tf.complex128等用于强制转换数据类型,如果无法转换为对应数据类型,则会抛出异常。示例:
complex64_tf=tf.to_complex64(data_tf)
7. Operation对象:
Operation对象也是图的重要组成部分,表示图中的一个节点。Operation对象有0个或0个以上的Tensor对象作为输入,并且有0个或0个以上的Tensor为输出。
1)Operation对象的创建:
当调用TensorFlow框架中的函数时,会在图中创建对应类型的Operation对象。示例:
import tensorflow as tf
A_tf=tf.constant([[1,1],[1,1]],dtype=tf.float32)
B_tf=tf.constant([[2,2],[2,2]],dtype=tf.float32)
C_tf=tf.matmul(A_tf,B_tf)
D_tf=C_tf+A_tf
graph=tf.get_default_graph()
ops=graph.get_operations()
print(ops)
代码输出结果:
[<tf.Operation 'Const' type=Const>,
<tf.Operation 'Const_1' type=Const>,
<tf.Operation 'MatMul' type=MatMul>,
<tf.Operation 'add' type=Add>]
可以看出,将Python的list转为Tensor常量的操作是类型Const的Operation对象,矩阵乘法和矩阵加法分别对应MatMul类型和Add类型的Operation对象。
2)获取并执行Operation对象:
在TensorFlow中,可以通过tf.Graph.get_operation_by_name来根据名称返回Operation对象,并且可以通过tf.get_default_session().run(op)来执行指定的Operation对象。当图中有变量时,需要执行sess
import tensorflow as tf
A_tf=tf.Variable([[1,1],[1,1]],dtype=tf.float32)
#为A_tf赋值
A_tf.assign(A_tf+1)
#获取当前图
graph=tf.get_default_graph()
#获取当前图中所有的Operation并打印
ops=graph.get_operations()
print(ops)
#找到初始化Operation
init_op=graph.get_operation_by_name('Variable/Assign)
with tf.Session() as sess:
#初始化操作
sess.run(init_op)
#取出变量值
print(sess.run(A_tf))
输出结果:
[<tf.Operation 'Variable/initial_value' type=Const>,
<tf.Operation 'Variable' type=VariableV2>,
<tf.Operation 'Variable/Assign' type=Assign>,
<tf.Operation 'Variable/read' type=Identity>,
<tf.Operation 'add/y' type=Const>,
<tf.Operation 'add' type=Add>,
<tf.Operation 'Assign' type=Assign>]
[[1. 1.]
[1. 1.]]
可以发现,代码中虽然A_tf的值加1并重新赋值给A_tf了,但这个操作并不在执行的路经中,因此还是显示的初始化值。需要手动执行这个赋值Operation对象,示例:
import tensorflow as tf
A_tf=tf.Variable([[1,1],[1,1]],dtype=tf.float32)
#为A_tf赋值
A_tf.assign(A_tf+1)
#获取当前图
graph=tf.get_default_graph()
#获取当前图中所有的Operation并打印
ops=graph.get_operations()
print(ops)
#找到初始化Operation
init_op=graph.get_operation_by_name('Variable/Assign)
add_op=graph.get_operation_by_name('Assign')
with tf.Session() as sess:
#初始化操作
sess.run(init_op)
#取出变量值
print(sess.run(A_tf))
#执行赋值操作
sess.run(add_op)
#取出变量赋值后的值
print(sess.run(A_tf))
代码执行后,前面显示一样,最后添加了显示:
[[2. 2.]
[2. 2.]]
8. TensorFlow流程控制:
TensorFlow中所有的计算必须在图中构建完成后才能执行,而Python的逻辑判断语句无法加入到静态图中,因此需要使用TensorFlow自带的逻辑判断语句函数,将流程控制语句加入静态图。
1)条件判断tf.cond与tf.where:
在TensorFlow中。函数tf.cond与tf.where都可以用于条件判断。其中tf.cond函数的原型:
tf.cond(
pred,
true_fn=None,
false_fn=None,
strict=False,
name=None,
fn1=None,
fn2=None
)
参数的含义及类型:
· pred:标量,用于决定是返回true_fn()的结果还是false_fn()的结果。
· true_fn:函数,当pred为true时执行该函数,并返回该函数执行的结果。
· false_fn:函数,当pred为false时执行该函数,并返回该函数执行的结果。
· strict:bool类型,用于设置是否启用strict模式。
· name:string类,作为tf.cond函数返回的Tensor对象名称的前缀。
· fn1:该参数已废除。
· fn2:该参数已废除。
函数true_fn和false_fn返回的都是Tensor对象列表,并且它们必须返回相同数据和类型的输出。示例:
import tensorflow as tf
A_tf=tf.Variable([[1,1],[2,2]],dtype=tf.float32)
B_tf=tf.Variable([[3,3],[4,4]],dtype=tf.float32)
a=tf.placeholder(shape=(),dtype=tf.int32)
b=tf.placeholder(shape=(),dtype=tf.int32)
result_tf=tf.cond(a
result_1=sess.run(result_rf,feed_dict={a:1,b:2})
result_2=sess.run(result_rf,feed_dict={a:2,b:1})
print('result_1:\n',result_1)
print('result_2:\n',result_2)
代码的逻辑比较简单,对Tensor对象a和b比较,如果a<b则返回A_tf和B_tf的相加结果,否则返回矩阵乘法结果。
tf.cond函数的pred必须为标量,也就是维度为0。tf.where允许条件语句为张量对象,函数原型:
tf.where(
condition,
x=None,
y=None,
name=None
)
参数含义及类型:
· condition:Tensor对象,其中该Tensor对象的数据类型为tf.bool类型。
· x:Tensor对象,x的第一个维度大小必须与condition大小相同。
· y:Tensor对象,y的shape必须与x的shape一致。
· name:当前Operation对象(tf.where)的名称。
函数tf.where返回的Tensor对象的数据来自x或y,每个坐标位置的值取x还是y对应的位置的元素由condition决定。如果x和y都为None,那么tf.where返回condition中为true的元素的坐标,该坐标存放在二维Tensor中。如果x和y都不是None,那么x和y必须有相同的shape。如果x和y都是标量,则condition必须是标量。
如果x和y为向量或者更高维度的张量,则condition必须是大小跟x的第一个维度相同的向量或者是跟x相同的shape。如果condition是向量且x和y是高维张量,那么tf.where会选择x或y中第一个维度中的数据进行复制。示例:
import tensorflow as tf
A_tf=tf.constant([[1,3,3],[5,2,4]],dtype=tf.float32)
B_tf=tf.constant([[3,2,1],[2,4,5]],dtype=tf.float32)
#情况1:x和y均为None
result_1=tf.where(A_tf
result_2=tf.where(A_tf
con_tf=tf.constant([True,False],dtype=tf.bool)
result_3=tf.where(con_tf
rs_1,rs_2,rs_3=sess.run([result_1,result_2,result_3])
print('rs_1:\n',rs_1)
print('rs_2:\n',rs_2)
print('rs_3:\n',rs_3)
代码中,情况1的含义是找出A_tf比B_tf小的元素坐标;情况2的含义是比较A_tf和B_tf,将较小值返回;情况3的含义是返回A_tf的第1行和B_tf的第2行组成新Tensor。输出结果:
rs_1:
[[0 0]
[1 1]
[1 2]]
rs_2:
[[1. 2. 1.]
[2. 2. 4.]]
rs_3:
[[1. 3. 3.]
[2. 4. 5.]]
2)TensorFlow比较判断:
TensorFlow中,比较运算符有tf.less、tf.less_equal、tf.equal、tf.not_equal、tf.greater、tf.greater_equal等,其函数原型及参数含义为:
· tf.less(x,y,name=None):x和y均为Tensor对象且x和y有相同的数据类型和shape。按对应坐标对x和y中的每个元素做比较,如果x中的元素小于y中对应的元素,则返回True,否则返回False。返回的Tensor对象与x和y的shape相同,但数据类型为tf.bool。
· tf.less_equal(x,y,name=None):x和y均为Tensor对象且x和y有相同的数据类型和shape。按对应坐标对x和y中的每个元素做比较,如果x中的元素小于等于y中对应的元素,则返回True,否则返回False。返回的Tensor对象与x和y的shape相同,但数据类型为tf.bool。
· tf.equal(x,y,name=None):x和y均为Tensor对象且x和y有相同的数据类型和shape。按对应坐标对x和y中的每个元素做比较,如果x中的元素等于y中对应的元素,则返回True,否则返回False。返回的Tensor对象与x和y的shape相同,但数据类型为tf.bool。
· tf.not_equal(x,y,name=None):x和y均为Tensor对象且x和y有相同的数据类型和shape。按对应坐标对x和y中的每个元素做比较,如果x中的元素不等于y中对应的元素,则返回True,否则返回False。返回的Tensor对象与x和y的shape相同,但数据类型为tf.bool。
· tf.greater(x,y,name=None):x和y均为Tensor对象且x和y有相同的数据类型和shape。按对应坐标对x和y中的每个元素做比较,如果x中的元素大于y中对应的元素,则返回True,否则返回False。返回的Tensor对象与x和y的shape相同,但数据类型为tf.bool。
· tf.greater_equal(x,y,name=None):x和y均为Tensor对象且x和y有相同的数据类型和shape。按对应坐标对x和y中的每个元素做比较,如果x中的元素大于等于y中对应的元素,则返回True,否则返回False。返回的Tensor对象与x和y的shape相同,但数据类型为tf.bool。
这些比较判断函数的功能类似,用法也基本一致,以tf.less函数为例介绍,示例:
import tensorflow as tf
A_tf=tf.constant([[1,3,3],[5,2,4]],dtype=tf.float32)
B_tf=tf.constant([[3,2,1],[2,4,5]],dtype=tf.float32)
A_less_B_tf=tf.less(A_tf,B_tf)
with tf,Session() as sess:
A_less_B=sess.run(A_less_B_tf)
print(A_less_B)
输出结果:
[[True False False]
[False True True]]
3)TensorFlow的逻辑运算:
TensorFlow中,逻辑运算函数有tf.logical_and、tf.logical_or、tf.logical_not、tf.logical_xor等。函数原型及其参数含义:
· tf.logical_and(x,y,name=None):x和y均为类型为tf.bool的Tensor对象,且x和y有相同的shape。对x和y中每个维度对应位置的元素做与运算,并将结果返回。
· tf.logical_or(x,y,name=None):x和y均为类型为tf.bool的Tensor对象,且x和y有相同的shape。对x和y中每个维度对应位置的元素做或运算,并将结果返回。
· tf.logical_not(x,y,name=None):x和y均为类型为tf.bool的Tensor对象,且x和y有相同的shape。对x和y中每个维度对应位置的元素做非运算,并将结果返回。
· tf.logical_xor(x,y,name=None):x和y均为类型为tf.bool的Tensor对象,且x和y有相同的shape。对x和y中每个维度对应位置的元素做异或运算,并将结果返回。
示例:
import tensorflow as tf
A_tf=tf.constant([[True,False,True],[False,True,True]],dtype=tf.bool)
B_tf=tf.constant([[False,True,False],[False,False,True]],dtype=tf.bool)
logical_and_tf=tf.logical_and(A_tf.B_tf)
with tf.Session() as sess:
logical_and=sess.run(logical_and_tf)
print('logical_and:\n',logical_and)
输出结果:
logical_and:
[[False False False]
[False False True]]
4)循环tf.while_loop:
函数tf.while_loop用于执行循环语句,与Python中的for循环作用相同。函数原型:
tf.while_loop(
cond,
body,
loop_vars,
shape_invariants=None,
parallel_iterations=10,
back_prop=True,
swap_memory=False,
name=None,
maximum_iterations=None
)
函数tf.while_loop的各个参数含义及类型:
· cond:函数类型,用于作为循环结束判断条件,返回tf.bool类型。
· body:函数类型,用于作为循环体,返回与loop_vars相同长度和数据类型的Tensor对象。
· loop_vars:可以取元组、list、Tensor及TensorArray等类型,定义传入cond函数和body函数的形参。
· shape_invariants:list类型,表示loop_vars的参数对应的固定shape。
· parallel_iterations:正整数类型,表示允许并行执行的最大迭代次数。
· back_prop:bool类型,表示是否允许当前循环参与反向传播计算。
· swap_memory:bool类型,表示是否启用GPU和CPU之间的内存复制。
· name:字符串类型,可选,用于定义该循环返回的Tensor对象的名称前缀。
· maximum_iterations:整数类型,可选,定义当前循环最大的循环次数。如果该参数定义,会将cond函数的结果和当前迭代次数与最大值比较的结果做与运算,以确保迭代次数不会超过maximum_iterations。
函数tf.while_loop要求循环中传入函数的形参的shape在每个迭代中是固定不便的。示例:
import tensorflow as tf
init_i=tf.constant(0) # 定义形参
def cond(i):
return tf.less(i,10)
def body(i):
return tf.add(i,1)
result_tf=tf.while_loop(cond,body,[init_i])
with tf.Session() as sess:
print('result:',sess.run(result_tf)
程序执行过程:初始传入cond和body函数的形参i的值为0,后面每次迭代时,传入cond和body函数的形参i均为上一次迭代中body函数的输出值。执行结果:
result: 10
有多个形参参与运算的示例:
import tensorflow as tf
init_i=tf.constant(0) # 定义形参
init_A=tf.constant([[1,1],[1,1]],tf.float32) # 定义形参
init_B=tf.constant([[2,2],[2,2]],tf.float32) # 定义形参
def cond(i,A,B):
return tf.less(i,2)
def body(i,A,B):
return tf.add(i,1),A+A,A+B
i_tf,A_tf,B_tf=tf.while_loop(cond,body,[init_i,init_A.init_B])
with tf.Session() as sess:
i,A,B=sess.run([i_tf,A_tf,B_tf])
print('i:',i)
print('A:',A)
print('B:',B)
在cond函数中指定了循环迭代次数为2;在body函数中定义每次循环迭代时要执行的函数,并把返回的值作为下一次迭代的输入。输出结果:
i: 2
A: [[4. 4.]
[4. 4.]]
B: [[5. 5.]
[5. 5.]]
9. TensorFlow位运算:
1)位与运算:
即对Tensor中的数据按二进制位做与运算。TensorFlow中,函数tf.bitwise.bitwise_and用于对两个Tensor对象做位与运算,函数原型:
tf.bitwise.bitwise_and(
x,
y,
name=None
)
函数各参数的含义及类型:
· x:Tensor对象,其数据类型只能为int8、int16、int32、int64、uint8、uint16、uint32、uint64中的一种。
· y:Tensor对象,其数据类型与x一致。
· name:字符串类型,当前位与运算的名称。
示例:
import tensorflow as tf
A_tf=tf.constant([[1,3],[5,7]],tf.uint8)
B_tf=tf.constant([[2,4],[6,8]],tf.uint8)
C_tf=tf.bitwise.bitwise_and(A_tf,B_tf)
with Session() as sess:
C=sess.run(C_tf)
print('C=',C)
输出结果:
C=[[0 0]
[4 0]]
2)位或运算:
即对Tensor中的数据按二进制位做或运算。TensorFlow中,函数tf.bitwise.bitwise_or用于对两个Tensor对象做位或运算,函数原型:
tf.bitwise.bitwise_or(
x,
y,
name=None
)
函数各参数的含义及类型:
· x:Tensor对象,其数据类型只能为int8、int16、int32、int64、uint8、uint16、uint32、uint64中的一种。
· y:Tensor对象,其数据类型与x一致。
· name:字符串类型,当前位或运算的名称。
3)位异或运算:
即对Tensor中的数据按二进制位做异或运算。TensorFlow中,函数tf.bitwise.bitwise_xor用于对两个Tensor对象做位异或运算,函数原型:
tf.bitwise.bitwise_xor(
x,
y,
name=None
)
函数各参数的含义及类型:
· x:Tensor对象,其数据类型只能为int8、int16、int32、int64、uint8、uint16、uint32、uint64中的一种。
· y:Tensor对象,其数据类型与x一致。
· name:字符串类型,当前位异或运算的名称。
4)位取反运算:
即对Tensor中的数据按二进制位做非运算。TensorFlow中,函数tf.bitwise.invert用于对两个Tensor对象做位或运算,函数原型:
tf.bitwise.invert(
x,
name=None
)
函数各参数的含义及类型:
· x:Tensor对象,其数据类型只能为int8、int16、int32、int64、uint8、uint16、uint32、uint64中的一种。
· name:字符串类型,当前位取反运算的名称。
10. TensorFlow字符串:
在训练网络模型读取训练集数据时,如果数据的标记格式比较复杂,则需要对标记字符串进行解析,需要对自定义格式的解析能力。
1)字符串的定义:
字符串的定义是在定义变量或常量时,通过指定参数dtype=tf.string的方式来定义字符串类型的Tensor对象。示例:
import tensorflow as tf
A_str_tf=tf.constant('Hello TensorFlow!',dtype=tf.string)
B_str_tf=tf.Variable('Hello TensorFlow!',dtype=tf.string)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(A_str_tf).decode())
print(sess.run(B_str_tf).decode())
2)字符串的转换:
将Number类型(包括int、float等数据类型)的Tensor转换为字符串的Tensor,使用函数tf.as_string;而函数tf.string_to_number用于将字符串类型的Tensor对象转换为指定数据类型的Tensor对象。
tf.as_string的函数原型:
tf.as_string(
input,
precision=-1,
scientific=False,
shortest=False.
width=-1,
fill=''.
name=None
)
函数tf.as_string各参数的含义及数据类型:
· input:Tensor对象,作为转换成tf.string数据类型的输入,其数据类型只能为int32、int64、complex64、float32、float64、bool、int8中的一种。
· precision:int类型,用于表示小数点后面的精度,只有大于-1时才有效。
· scientific:bool类型,用于设置是否使用科学计数法表示浮点数。
· shortest:bool类型,用于设置是否从科学计数法和标准浮点表示中取较短的表示方法。
· width:int类型,将小数点前面的数填充到指定宽度,当大于-1时才有效。
· fill:字符串类型,当参数大于-1时,在小数点前面填充的字符串,该字符串参数的长度不能超过1。
· name:字符串类型,设置当前Operation对象的名称。
以tf.float32数据类型转换为tf.string数据类型为例:
import tensorflow as tf
A_float_tf=tf.constant([1,2,3,4,5,6],dtype=tf.float32)
A_str_tf=tf.as_string(A_float_tf)
with tf.Session() as sess:
bytes_v=sess.run(A_str_tf)
A_str=[v.decode() for v in bytes_v]
print(A_str)
输出结果:
['1.000000','2.000000','3.000000','4.000000','5.000000','6.000000']
将tf.string类型转换为Number类型的函数tf.string_to_number的原型:
tf.string_to_number(
string_tensor,
out_type=tf.float32,
name=None
)
函数原型的各参数含义及数据类型:
· string_tensor:Tensor对象,数据类型为tf.string。
· out_type:tf.Dtype对象,用于设置转换后输出的Tensor数据类型,只能取tf.float32、tf.float64、tf.inr32、tf.int64中的一种,默认tf.float32。
· name:字符串类型,设置当前Operation对象的名称。
以tf.string数据类型转换为tf.float32数据类型为例:
import tensorflow as tf
A_str_tf=tf.constant(['1.0','2.5','3.1','4.0','5.9','6.2'],dtype=tf.string)
A_float_tf=tf.string_to_number(A_str_tf,out_type=tf.float32)
with tf.Session() as sess:
print(sess.run(A_float_tf))
输出结果:
[1. 2.5 3.1 4. 5.9 6.2]
将tf.string转为Number类型时,必须保证tf.dtring存储的数据能准确转为指定Number数据类型。
3)字符串拆分:
在TensorFlow中,函数tf.string_split用于根据指定的分隔符将字符串进行拆分。函数原型:
tf.string_split(
source,
delimiter=' ',
skip_empty=True
)
各个参数的含义及数据类型:
· source:一维Tensor对象,其数据类型为tf.string,作为分割的输入。
· delimiter:标量Tensor对象,表示分割字符,其字符串长度只能为0或1。
· skip_empty:bool类型,表示是否跳过空的字符串。
函数tf.string_split返回的是稀疏矩阵SparseTensor对象,示例:
import tensorflow as tf
A_str_tf=tf.constant(['1,2,3,4,5'],dtype=tf.string)
A_arr_tf=ttf.string_split(A_str_tf,delimiter=',')
with tf.Session() as sess:
A_arr=sess.run(A_arr_tf)
print('indices :\n',A_arr.indices)
print('ivalues :\n',[v.decode() for v in A_arr.values])
print('dense shape :\n',A_arr.dense_shape)
输出:
indices :
[[0 0]
[0 1]
[0 2]
[0 3]
[0 4]]
values : ['1','2','3','4','5']
dense shape : [1 5]
注意,函数tf.string_split的第1各参数必须是一维的且数据类型为tf.string的Tensor对象。
4)字符串拼接:
在TensorFlow中,函数tf.string_join用于将list中数据类型为tf.string的多个Tensor对象拼接成一个数据类型为tf.string的Tensor对象、函数原型:
tf.string_join(
inputs,
separator=' ',
name=None
)
各个参数的含义及数据类型:
· inputs:list类型,list中存放的是数据类型为tf.string的Tensor。
· separator:字符串类型,表示各个字符串中的连接符。
· name:字符串类型,设置当前Operation对象的名称。
示例:
import tensorflow as tf
A_str_tf=tf.constant('hello',dtype=tf.string)
B_str_tf=tf.constant('tensor',dtype=tf.string)
C_str_tf=tf.constant('flow',dtype=tf.string)
ABC_str_tf=ttf.string_join([A_str_tf,B_str_tf,C_str_tf],separator='_&_')
with tf.Session() as sess:
ABC_str=sess.run(ABC_str_tf)
print(ABC_str.decode())
输出结果:
hello_&_tensor_&_flow
如果Tensor对象的维度是多维的,则每个维度对应执行拼接,示例:
import tensorflow as tf
A_str_tf=tf.constant([['hello'],['1']],dtype=tf.string)
B_str_tf=tf.constant([['tensor'],['2']],dtype=tf.string)
C_str_tf=tf.constant([['flow'],['3']],dtype=tf.string)
ABC_str_tf=ttf.string_join([A_str_tf,B_str_tf,C_str_tf],separator='_&_')
with tf.Session() as sess:
ABC_str=sess.run(ABC_str_tf)
print(ABC_str.decode())
输出结果:
[[b'hello_&_tensor_&_flow']
[b'1_&_2_&_3']]
注意,TensorFlow中,输出类型为tf.string的Tensor对象通过tf.Session().run()函数取出后是字节数组类型。
二、高维Tensor对象的工具函数:
数据的维度上升到四维甚至更高维度时,往往比较抽象。高维Tensor对象的运算是在低维Tensor运算基础上的推广。
1. 重定义shape:
TensorFlow中,单张图片一般采用shape为[height,width,channels],即第1个维度表示图片的高度,第2个维度表示图片的宽度,第3个维度表示图片的通道数。如shape=[256,128,3],即表示图片宽度为256、宽为128、通道数为3。对于具体坐标[0,1,2]表示第2个通道中第1行第0列的像素值。有时需要对shape变形,如将图像中的数据按一维数组方式排列,这时可以通过重新定义Tensor对象的shape的方式实现。TensorFlow中,函数tf.reshape用于重新定义Tensor的shape。
一维数组在计算机内存中是用一块连续的空间存储,二维数组及更高维数组也是如此。对于高维矩阵,其本质可看成一维数组,只是高维数组存取数据时,需要换算指定的各个维度对应于一维数组的索引。在Reshape过程中,存储数据的顺序不会发生变化,数据依然是同样一批数据,以不同尺度读取数据则得到的是不同的shape数据。
TensorFlow中,函数tf.reshape用于实现Reshape操作,函数原型:
tf.reshape(
tensor,
shape,
name=None
)
其中,tensor为输入Tensor对象;参数shape表示经过Reshape后的shape,数据类型只能为int32或int64。
在库numpy中也有Reshape的实现函数np.reshape,还可以直接用Python代码实现,实现方法是先将高维数组拉伸成一维,再将一维数组重新reshape到指定的shape。
2. 维度交换函数:
对于二维矩阵,将x和y交换的操作称为矩阵转置。二维矩阵的转置是高维矩阵转置的特例,高维Tensor转置需要实现任意维度交换。TensorFlow中,tf.transpose用于实现任意维度的交换。
从Tensor下标的角度来理解,在Tensor[m][n][k]处的数据,经过Transpose操作后,存放位置为Tenso[n][k][m],数据存储的位置发生变化。函数tf.transpose的原型:
tf.transpose(
a,
perm=None,
name='transpose',
conjugate=False
)
各个参数的含义及类型:
· a:Tensor对象,为输入。
· perm:列表类型,表示交换后的维度位置。
· name:字符串类型,表示当前Operation的名称。
· conjugate:bool类型,如果为True,返回tf.conj(tf.transpose(a))。其中,tf.conj的功能为,如果输入是实数,则不做任何操作返回输入;如果输入是复数,则将复数的虚部取反数。
trans_tf=tf.transpose(data_tf,(2,1,0))
3. 维度扩充与消除:
许多场景下需要增加Tensor的维度,增加一个长度为1的维度;而有些场景则希望将Tensor长度为1的维度去掉。
1)维度扩充:
TensorFlow中,函数tf.expand_dims的功能是在Tensor对象shape中任意位置加入新的维度,新加入的维度数据长度为1。函数原型:
tf.expand_dims(
input,
axis=None,
name=None,
dim=None
)
各参数含义及数据类型:
· input:Tensor对象,为输入。
· axis:整数类型,假设input是N维Tensor,那么axis的取值范围为[-1-N,N]。
· name:字符串类型,指定输入Tensor对象名称。
· dim:整数类型,等价于axis,即将弃用。
output_tf=tf.expand_dims(input_tf,axis=1)
2)维度消除:
函数tf.squeeze用于将指定长度为1的维度消除。原型:
tf.squeeze(
input,
axis=None,
name=None,
squeeze_dims=None
)
各参数含义及数据类型:
· input:Tensor对象,为输入。
· axis:列表类型,默认[],列表里的数据类型为int。将列表中指定的索引维度消除,如果索引所指定的维度的长度不为1则抛出异常。假设input是N维Tensor对象,列表中索引取值范围[-N,N]。
· name:字符串类型,指定当前Operation的名称。
· squeeze_dims:等同于参数axis,即将弃用。
output_tf=tf.squeeze(input_tf,axis=[0,2])
4. Tensor对象裁剪:
对于三通道的图像,很容易理解图像裁剪的原理就是在宽和高两个维度截取一个区域,在通道维度保留所有区域。对于一般性的Tensor而言,裁剪就是将指定任意维度区域保留下来,而将不在指定区域的维度数据丢弃。
函数tf.slice用于截取Tensor对象每个维度的指定区域,函数原型:
tf.slice(
input_,
begin,
size,
name=None
)
各个参数的含义及数据类型:
· input_:Tensor对象,为输入。
· begin:数据类型为整数类型的列表,或者是数据类型为int32或int64的Tensor对象。列表中的每个整数用于指定对应维度截取的起始位置。
· size:数据类型为整数类型的列表,或者是数据类型为int32或int64的Tensor对象。列表中的每个整数用于指定对应维度截取的长度。
· name:字符串类型,作为当前Operation对象的名称。
参数begin是从0开始索引,begin[i]表示第i个维度的截取位置,参数size指定截取长度,size[i]表示第i个维度截取的长度。
output_tf=tf.slice(input_tf,[0,1,1],[1,2,1])
5. Tensor对象拼接:
图片可以看成三维Tensor,图片拼接可以在水平方向和垂直方向上做拼接。对于一般性Tensor而言,其拼接即在指定的任意维度方向上的连接。函数tf.concat用于将Tensor对象在任意维度方向上做拼接,原型:
tf.concat(
values,
axis,
name='concat'
)
各个参数的含义及数据类型:
· values:列表类型或者Tensor对象,如果是列表,则列表中存放的是Tensor对象。
· axis:整数或者数据类型为int32的标量Tensor对象,用于指定拼接的维度。
· name:字符串类型,表示当前Operation对象的名称。
output_tf=tf.concat([A_tf,B_tf],axis=0)
Tensor对象在哪个维度做连接,对应长度就等于两个Tensor对应维度的长度之和。
6. tf.stack和tf.unstack:
TensorFlow中,tf.stack的功能是将多个Tensor对象按栈的方式组合成新的Tensor对象,tf.unstack操作则相反。
1)tf.stack的使用:
栈操作是按照将先进入的元素放入栈底后进入的元素放入栈顶的顺序存放数据。tf.stack将传入的Tensor列表按栈顺序入栈,但是没有出栈操作。tf.stack根据指定的维度位置扩充维度,是tf.expand_dims和tf.concat的组合实现。原型:
tf.stack(
values,
axis=0,
name='stack'
)
各个参数的含义及数据类型:
· values:列表类型,列表中存放的是Tensor对象,并且每个Tensor对象的shape和数据类型必须一致。
· axis:整数类型,指定stack操作的维度索引,默认0。假设参数values中的Tensor对象为N维Tensor,那么axis的取值范围为[-(N+1),N+1]。
· name:字符串类型,指定当前Operation对象的名称。
output_tf=tf.stack([A_tf,B_tf,C_tf],axis=0)
2)tf.unstack的使用:
tf.unstack是tf.stack的逆运算,用于将一个Tensor对象在指定维度上拆分成多个Tensor对象,函数原型:
tf.unstack(
value,
num=None,
axis=0,
name='unstack'
)
各个参数含义及类型:
· value:维度大于0的Tensor对象,为输入。
· num:整数类型,指定输出Tensor对象的个数,即参数axis指定维度的长度。如果没有指定,将会自动根据axis指定的维度的长度来获取。
· axis:整数类型,指定执行的维度,默认为0。假设value是N维Tensor对象,那么axis的取值范围为[-N,N]。
· name:字符串类型,指定当前Operation的名称。
output_tf=tf.unstack(input_tf,axis=0)
函数tf.unstack功能可以利用函数tf.slice来实现。对于shape=[A,B,C]的Tensor对象input,执行tf
7. tf.argmax与tf.argmin:
函数tf.argmax的功能是找出指定维度上值最大的索引,而函数tf.argmin用于找出指定维度上值最小的索引。函数原型分别为:
tf.argmax(
input,
axis=None,
name=None,
dimension=None,
output_type=tf.int64
)
tf.argmmin(
input,
axis=None,
name=None,
dimension=None,
output_type=tf.int64
)
各个参数含义及数据类型:
· input:Tensor对象,数据类型只能取float32、float64、int32、uint8、int16、int8、complex64、int64、qint8、quint8、qint32、bfloat16、uint16、complex128、half、uint32、uint64中的一种。
· axis:整数类型或者是数据类型为int32或int64的0维Tensor对象。假设input是N维Tensor对象,那么axis的取值范围维[-N,N],用于指定比较的维度。
· name:字符串类型,用于指定当前Operation对象的名称。
· dimension:该参数已废弃。
· output_type:tf.Dtype类型,只能取tf.int32或tf.int64,表示输出数据类型。
max_tf=tf.argmax(input_tf,axis=0)
三、前馈卷积神经网络:
前馈网络不需要关心梯度和参数更新问题,只需关心输入、输出和当前节点的参数。相比反向传播网络,前馈网络更容易理解。
1. 卷积:
1)卷积原理:
在深度学习中,卷积的定义与数学上的定义有细微区别。卷积核可以看成一个二维矩阵,多个卷积核可以组成N维矩阵。常见的卷积核有7x7、5x5、3x3和1x1。计算卷积的第一步是设置padding方式,即边缘填充方式,常见的有SAME和VALID两种。SAME方式是当卷积核在边缘运算时会在边缘补充0,VALID方式则是不做任何填补,大部分时候padding方式都为SAME。卷积另外一个重要参数是stride,即每一步移动的长度。计算方式为卷积核上每个位置的值与输入Feature Map选中区域的每个位置值相乘,然后求和。
实际应用时,大部分情况都是多通道输入和输出。输入通道数为in_c,输出通道数为out_c,卷积核的数量filter_n
2)卷积输出:
计算卷积之前,输入宽高、卷积核宽高及stride都是已知的,输出宽高及SAME填充规则都是基于输入宽高和stride计算得出。
Stride_x表示水平方向的stride,stride_y表示垂直方向的stride值。输入Feature Map的宽高分别用in_width和in_height表示,输出Feature Map的宽高分别用out_width和out_height表示,卷积核的宽高分别用filter_width和filter_height表示。
TensorFlow中,当Padding=SAME时,输出Feature Map的宽高和输入宽高及stride的关系:
out_width=[in_width/stride_x]
out_height=[in_height/stride_y]
其中数值为向上取整。
TensorFlow中,当Padding=VALID时,输出Feature Map的宽高和输入宽高及stride的关系:
out_width=[(in_width-filter_width+1)/stride_x]
out_height=[(in_height-filter_height+1)/stride_y]
其中数值为向上取整。
输出Feature Map宽高确定后,根据输入Feature Map和输出Feature Map的宽高可以确定Padding=SAME时边界上需要补0的行数pad_height和列数pad_width。计算公式:
pad_width=max{(out_width-1)×stride_x+filter_width-in_width,0}
pad_height=max{(out_height-1)×stride_y+filter_height-in_height,0}
在计算得到需要补0的行数和列数后,行数要平均地分配到上下两个边界,列数要平均地分配到左右两个边界。在存在奇数时,下侧边界会比上侧边界多多分配一行,右侧边界会比左侧边界多分配一行。用pad_top表示上侧需要补0的行数,pad_bottom表示下侧需要补0的行数,pad_left表示左侧需要补0的列数,pad_right表示右侧需要补0的列数。公式:
pad_top=[pad_height/2] # 向下取整
pad_bollom=pad_height-pad_top
pad_left=[pad_width/2] # 向下取整
pad_bollom=pad_width-pad_left
3)空洞卷积:
空洞卷积选择的区域不一定是连续的一块区域,允许间隔一定的长度来选取不同位置的值组成一个卷积区域,间隔长度可以由用户设置。空洞卷积选取卷积区域的元素之间的位置间隔分为水平方向间隔和垂直方向间隔,在Batch维度和通道维度上也可以设置。
相同条件下,使用空洞卷积感受视野更广,如果需要较大的感受视野但同时不想把卷积核宽高设计得太大,可以考虑使用空洞卷积。但空洞卷积选择的卷积区域元素之间不连续,意味着丢失了原始输入数据的连续性特征,在目标物体较小时明显不利。
4)TensorFlow中的卷积计算:
TensorFlow中,卷积函数为tf.nn.conv2d。函数原型:
tf.nn.conv2d(
input,
filter,
strides,
padding,
use_cudnn_on_gpu=True,
data_format='NHWC',
dilations=[1,1,1,1],
name=None
)
各个参数的含义及数据类型:
· input:四维Tensor对象,表示输入数据。数据维度格式可以是[N,H,W,C],即[Batch数量,高度,宽度,通道数],也可以是[N,C,H,W],具体由data_format决定。
· filter:四维Tensor对象,表示卷积核。数据维度格式为[filter_height, filter_width, in_channels, out
· strides:长度为4的一维列表,分别表示input里面每个维度的stride,具体顺序跟data_format有关。
· padding:字符串对象,只能取SAME或者VALID。
· use_cudnn_on_gpu:bool类型,表示GPU是否使用cudnn库,默认True。
· data_format:字符串对象,只能取NHWC或NCHW,指定输入和输出的维度格式,默认NHWC。
· dilations:长度为4的一维列表,表示空洞卷积在每个维度的步长,默认[1,1,1,1]。
· name:字符串对象,指定当前Operation对象的名称。
实现Padding=SAME和stride=1的卷积计算示例:
import tensorflow as tf
import numpy as np
#输入数据,格式CHW
input_data=[[[1,2,3],[2,1,3],[3,2,1]]]
#卷积核,格式[in_c,height,width]
weights_data=[[[1,1,1],[1,1,1],[1,1,1]]]
#对卷积函数封装
def tf_conv2d(input,weights,stride,dilation=1):
conv=tf.nn.conv2d(input,weights,strides=[1,stride,strode,1],dilations=[1,dilation
return conv
#主函数
def main():
const_input=tf.constant(input_data,tf.float32)
const_weights=tf.constant(weights_data,tf.float32)
input=ft.Variable(constant_input,name="input")
#[2,5,5]---->[5,5,2]
input=tf.transpose(input,perm=[1,2,0])
#[5,5,2]---->[1,5,5,2]
input=tf.expand_dims(input,0)
weights=tf.Variable(const_weights,name="weights")
#将卷积核由[in_c,height,width]转为[height,width,in_c],即[1,3,3]--->[3,3,1]
weights=tf.transpose(weights,perm=[1,2,0])
#将卷积核由[height,width,in_c]扩充为[height,width,in_c,out_c],即[3,3,1]--》[3,3,1,1]
weights=tf.expand_dims(weights,3)
#[b,h,w,c]
conv=tf_conv2d(input,weights,stride=1)
#[h,w,c]---->[c,h,w]
rs=tf.transpose(conv[0],peim=[2,0,1])
init=tf.global_variables_initializer()
sess-tf.Session()
sess.run(init)
conv_val=sess.run(rs)
#打印结果,跳过第一个维度Batch
print(conv_val[0])
#主程序入口
if __name__=='__main__':
main()
代码中,定义输入和卷积核均采用CHW格式,比较容易看懂,后面的代码则使用transpose将CHW转换为WHC,卷积结果再转换回来。结果:
[[6. 12. 9.]
[11. 18. 12.]
[8. 12. 7.]]
2. 反卷积:
反卷积Deconvolution就是卷积的逆操作,还称为分数步长卷积、转置卷积等。
1)反卷积原理:
当卷积的stride>1时,得到的输出Feature Map的宽高比输入Feature Map的宽高要小,这可以看成下采样的过程。而反卷积操作可以看成上采样,即输出Feature Map的宽高比输入Feature Map宽高大。
计算反卷积时,首先需要对输入Feature Map执行补0。反卷积也有Padding参数设置,并且也分为SAME和VALID两种,但在反卷积中Padding参数主要用于计算输出Feature Map的宽高。不管反卷积的Padding设置为SAME或VALID,都会对边界补0,并且上下侧边界补0的行数均为反卷积核的高度减1,左右侧边界补0的列数均为反卷积核的宽度减1。反卷积还会在输入Feature Map的每个元素之间插入0,对于每一行,每两个元素之间插入0的数量为行方向的stride-1;对于每一列,每两个元素之间插入0的数量为列方向的stride-1。
计算反卷积过程中,首先是对输入Feature Map每个元素之间和边界插入0,然后对插入的输入做普通卷积运算。
在TensorFlow的反卷积中,Padding方式设置为VALID与SAME的区别主要有两点:
· 用户在设置输出Feature Map的维度时,Padding方式设置为VALID与SAME的计算公式不同。
· 在获取最终输出Feature Map时,如果得到的输出Feature Map的维度与用户设置的维度不同时,SAME方式的Padding需要丢弃一些多余项,而VALID方式需要补0。
2)输出宽高:
反卷积的输出Feature Map的宽高可以根据卷积的输出宽高的计算公式逆向计算出来。
①Padding=SAME时:
在TensorFlow中,反卷积输出Feature Map需要用户指定,为了便于与卷积的输入/输出宽高区分,用de_outW和de_outH分别表示反卷积的输出宽度和输出高度,用de_inW和de_inH分别表示反卷积的输入宽度和输入高度,用de_Sx和de_Sy分别表示反卷积在宽的维度上的stride和在高的维度上的stride。计算公式:
de_outW={x|(de_inW-1)×de_Sx<x≤de_inW×de_Sx}
de_outH={y|(de_inH-1)×de_Sy<y≤de_inH×de_Sy}
在TensorFlow中,如果指定的输出Feature Map的宽高比实际计算得到的宽高小,那么会在实际计算得到的Feature Map中裁剪一块与用户指定的宽高大小相同的区域作为反卷积的输出。
用my_outW和my_outH表示用户设置的宽高,用cpt_outW和cpt_outH分别表示实际计算得到的输出Feature Map的宽高,用left和top表示从计算得到的输出Feature Map中裁剪的有效区域与左边界间隔的列数及与上边界间隔的行数。如果my_outW<cpt_outW且my_outH<cpt_outH,那么裁剪的起始位置的left和top的计算公式:
left=[(cpt_outW-my_outW)/2] # 向下取整
top=[(cpt_outH-my_outH)/2] # 向下取整
有了left和top后,相当于有了裁剪起始位置,根据my_outW和my_outH可以计算得到裁剪区域。
理解裁剪区域的方式,如果实际计算得到的宽高减去用户指定的宽高结果为偶数,那么裁剪区域就是正中间的区域;如果是奇数,那么右边比左边多丢弃一列,下边比上边多丢弃一行。
②Padding=VALID时:
用de_fW和de_fH分别表示反卷积核的宽和高,计算公式:
de_outW={x|(de_inW-1)×de_S+de_fW-1<x≤de_inW×de_Sx+de_fW-1}
de_outH={y|(de_inH-1)×de_Sy+de_fH-1<y≤de_inH×de_Sy+de_fH-1}
当Padding=VALID时,用户指定的输出宽高可能会比实际计算得到的Feature Map的宽高大,那么会在右侧补my_outW-cpt_outW列0,在下侧补my_outH-cpy_outH行0。如果用户指定输出宽高比实际宽高小,那么会报错。
3)TensorFlow中的反卷积计算:
在TensorFlow中,反卷积函数tf.nn.conv2d_transpose用于反卷积计算。函数原型为:
tf.nn.conv2d_transpose(
value,
filter,
out_shape,
strides,
padding='SAME',
use_cudnn_on_gpu=True,
data_format='NHWC',
name=None
)
各个参数的含义及数据类型:
· value:四维Tensor对象,表示输入数据。数据维度可以是[N,H,W,C],即[Batch数量,高度,宽度,通道数],也可以是[N,C,H,W],具体方式由data_format决定。
· filter:四维Tensor对象,表示卷积核,数据维度格式[filter_height, filter_width, out_channels, in_channels]。
· out_shape:长度为4的一维列表,分别代表input里面每个维度对应的输出维度大小。
· stride:长度为4的一维列表,分别代表input里面每个维度的stride。
· padding:字符串对象,只能取字符串SAME或VALID。
· data_format:字符串对象,只能取NHWC或NCHW,指定输入和输出的维度格式,默认NHWC。
· name:字符串对象,指定当前反卷积操作的名称。
反卷积示例:
import tensorflow as tf
import numpy as np
#输入数据,shape为[channels,height,width]CHW
input_data=[[[1,0,1],[0,2,1],[1,1,0]]]
#卷积核,格式[out_c,in_c,height,width]
weights_data=[[[[1,0,1],[-1,1,0],[0,-1,0]]],[[[1,0,2],[-2,1,1],[1,-1,0]]]]
#对卷积函数封装
def tf_conv2d_transpose(input,weights,stride=3,padding='SAME',output_hw=None):
#input_shape=[n,height,width,channel]
in_b,in_h,in_w,in_c=input.get_shape().as_list()
#weights shape=[height,width,out_c,in_c]
w_h,w_w,w_out_c,w_in_c=weight.get_shape().as_list()
if output_hw is None:
#根据padding计算输出shape
if padding=='SAME':
output_shape=[in_b,in_h*stride,in_w*stride,w_out_c[2]]
else:
output_shape=[in_b,in_h*stride+w_h-1,w_out_c*stride+w_w-1,w_out_c[2]]
else:
output_shape=[in_b,output_hw[0],output_hw[1],w_out_c]
deconv=tf.nn.conv2d_transpose(input,weights,output_shape_shape,strides=[1,stride,1],padding=padding)
return deconv
#主函数
def main():
weights_np=np.asarray(weights_data,np.float32)
#将输入的每个卷积核旋转180度
weights_np=np.rot90(weights_np,2,(2,3))
const_input=tf.constant(input_data,tf.float32)
const_weights=tf.constant(weights_np,tf.float32)
input=ft.Variable(constant_input,name="input")
#[c,h,w]---->[h,w,c]
input=tf.transpose(input,perm=[1,2,0])
#[h,w,c]---->[n,h,w,c]
input=tf.expand_dims(input,0)
#weights shape=[out_c,in_c,h,w]
weights=tf.Variable(const_weights,name="weights")
#将卷积核由[out_c,in_c,h,w]转为[h,w,out_c,in_c]
weights=tf.transpose(weights,perm=(2,3,0,1))
#执行反卷积
deconv=tf_conv2d_transpose(input,weights,stride=2,padding='VALID',output_hw=[7,7])
init=tf.global_variables_initializer()
sess=tf.Session()
sess.run(init)
deconv_val=sess.run(deconv)
hwc=deconv_val[0]
h,w,c=hwc.shape
for i in range(c):
print(hwc[:,:,i])
#主程序入口
if __name__=='__main__':
main()
代码中,将自定义的反卷积核旋转180°,这是计算反卷积时传入反卷积函数之前必须要做的一步,要不然得到的结果会与预期有差别。实际项目中,反卷积核的参数都是通过学习得到的,不需要传入,所以不需要关心传入卷积核是否需要旋转的问题。
3. Batch Normalization:
为了充分利用GPU的并行处理能力,TensorFlow会同时将多张图片一起传入网络进行训练,多张图片称为一个batch。采用这种batch的方式不仅为了利用GPU的并行能力,更是为了能让训练相对稳定一些。
1)Batch Normalization原理:
对于一批具有相同特征的数据集,其包含的数据共性服从某个分布,而每个个体之间可能存在很大差异。但是在训练过程中,如果将两张图片先后单独传入网络训练,由于数据分布可能相差比较大,训练过程中模型学习到的分布不断发生偏移,可能会带来梯度消失或梯度发散的问题,这会给网络训练带来困难。
在传入网络之前,如果能将数据统一规范化,每次传入网络的数据都服从某个分布,那将会使得网络收敛得更快。Batch Normalization就是做规范化的一层网络层,每次传入网络层时,将输入x中的每个通道(多张图中对应的每个通道)求平均值μ和方差σ2,然后根据均值和方差对数据做转化,使得输入服从标准正态分布,公式:x=(x-μ)/σ。
但是,对于每一层网络来说,如果强制将输入转为服从正态分布的数据,就会将网络的能力消弱,因为每层网络的输入的最佳分布不一定呈标准正态分布。为了解决这个问题,可以在标准化公式中添加缩放系数γ和偏移系数β,公式:
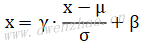
2)TensorFlow中使用Batch Normalization:
TensorFlow中,Batch Normalization的接口函数为tf.nn.batch_normalization。函数原型:
tf.nn.batch_normalization(
x,
mean,
variance,
offset,
scale,
variance_epsilon,
name=None
)各个参数的含义及数据类型:
· x:Tensor对象,输入Feature Map,公式一般为[Batch,Height,Width,Channel]。
· mean:Tensor对象,表示均值,格式一般为长度为通道数的一维数组。
· variance:Tensor对象,表示方差,格式一般为长度为通道数的一维数组。
· offset:Tensor对象,表示偏移量参数,格式一般为长度为通道数的一维数组。
· scale:Tensor对象,表示缩放参数,格式一般为长度为通道数的一维数组。
· variance_epsilon:float类型,为避免分母为0,需要对分母加一个很小的数,如0.001。
· name:字符串类型,用于指定当前Operation对象的名称。
函数tf.nn.batch_normalization相对比较底层,需要用户传入均值、方差、缩放系数scale和偏移系数offset。如果想通过移动平均线的方式来计算均值和方差,需要用户自己实现。为了简化这一过程,TensorFlow提供了另一个函数tf.layers.batch_normalization,使用这个函数可以不关心均值、方差、缩放系数及偏移量的计算和设置方式。函数原型:
tf.layers.batch_normalization(
inputs,
axis=-1,
momentum=0.99,
epsilon=0.001,
center=True,
scale=True,
beta_initializer=tf.zeros_initializer(),
gamma_initializer=tf.ones_initializer(),
moving_mean__initializer=tf.zeros_initializer(),
moving_variance__initializer=tf.ones_initializer(),
beta_regularizer=None,
gamma_regularizer=None,
beta_constraint=None,
gamma_constraint=None,
training=False,
trainable=True,
name=None,
reuse=None,
renorm=False,
renorm_clipping=Nobe,
renorm_momentum=0.99,
fused=None,
virtual_batch_size=None,
adjustment=None
)函数的参数比较多,常用参数含义及数据类型:
· inputs:Tensor对象,表示输入Feature Map,格式一般为[Batch,Height,Width,Channel]。
· momentum:float类型,平滑算法中,当前待平缓的值(如均值、方差)相比相比于上一个值的权重。
· epsilon:float类型,为了避免分母为0,需要对分母加一个很小的数,默认0.001。
· center:bool类型,如果为True,表示要加偏移量参数offset,默认为True。
· scale:bool类型,如果为True,表示要加缩放系数scale,默认为True。
下面分别使用tf.nn.batch_normalization和tf.layers.batch_normalization函数来实现Batch Normalization。暂时将缩放参数scale设为1,偏移量offset设为0,使用TensorFlow框架计算Batch Normalization代码:
import tensorflow as tf
import numpy as np
#shape=[batch,c,h,w]
input=[
#第1张图,2通道,宽高2*2
[
#第1个通道
[[1,2],[2,1]],
#第2个通道
[[3,4],[4,3]]],
#第2张图,2通道,宽高2*2
[
#第1个通道
[[5,6],[6,5]],
#第2个通道
[[7.8],[8,7]]]]
input_np=np.array(input,np.float32)
input_tf=constant(input_np,tf.float32)
#[b,c,h,w]---->[b,h,w,c]
input_tf=tf.transpose(input_tf,perm=(0,2,3,1))
_,_,_,c=input_tf.get_shape().as_list()
scale=tf.ones((c,),tf.float32)
offet=tf.zeros((c,),tf.float32)
mean,var=tf.nnmoments(input_tf,[0,1,2])
output=tf.nn.batch_normalization(input_tf,mean,var,0ffset,scale,variance_epsilon=0.001,name='bn')
with tf.Session() as sess:
m,v,out=sess.run([mean,var,output])
print('mean=',m)
print('var=',v)
#[b,h,w,c]--->[b,c,h,w]
out=np.transpose(out,axes=(0,3,1,2))
print('output=\n',out)代码中,为了便于阅读,输入使用[batch,channel,height,width]格式存储,而在使用TensorFlow时需要转为[batch,height,width,channel]格式,才能使计算结果与预期结果对应上。但输出结果为了便于阅读,又把格式转为[batch,channel,height,width]。
注意,在求Batch Normalization时分母不是直接将方差代入,而是用标准差,即方差的算术平方根。
①使用tf.nn.batch_normalization:
前面示例是使用tf.nn.batch_normalization来实现Batch Normalization。但在实际项目中,缩放参数scale和偏移参数offset不是固定的,而是需要通过学习得到,即scale和offset必须是tf.Variable对象,而且是trainable的。
将缩放参数和偏移参数变量、求均值方差及Batch Normalization封装成一个函数,便于Batch Normalization简单调用:
def batch_norm(x,momentum=0.99,epsilon=0.001,is_training=True):
_,_,_,c=x.get_shape().as_list()
#定义缩放变量gamma和偏移变量beta
gamma=tf.get_variable('gamma',(c,),dtype=tf.float32,initializer=tf.ones_initializer,trainable=is_training)
beta=tf.get_variable('beta',(c,),dtype=tf.float32,initializer=tf.zeros_initializer,trainable=is_training)
#计算均值与方差
mean,variance=tf.nn.moments(x,[0,1,2])
#如果是训练阶段,用移动平均线moving_average来对均值和方差做平滑
if is_training:
moving_mean=tf.get_variable('moving_mean',
moving_variance=tf.get_variable('moving_variance',
update_moving_mean=moving_averages.assign_moving_average(moving_mean,mean,momentum)
update_moving_variance=moving_averages.assign_moving_average(moving_variance,variance,momentum)
tf.add_to_collection(tf.GraphKeys.UPDATE_OPS,update_moving_mean)
tf.add_to_collection(tf.GraphKeys.UPDATE_OPS,update_moving_variance)
mean,variance=moving_mean,moving_variance
x=tf.nn.batch_normalization(x,mean,variance,beta,gamma,variance_epsilon=epsilon)
return x上面代码根据当前是否是训练来决定是直接计算均值方差,还是用平滑算法来替代均值方差,代码中分别用1和0初始化缩放变量gamma和偏移变量beta。计算Batch Normalization时,方差是分母,为了防止方差为0,会对方差加一个非常小的值epsilon,默认0.001。下面示例使用上述的函数封装:
import tensorflow as tf
import numpy as np
#shape=[batch,c,h,w]
input=[
#第1张图,2通道,宽高2*2
[
#第1个通道
[[1,2],[2,1]],
#第2个通道
[[3,4],[4,3]]],
#第2张图,2通道,宽高2*2
[
#第1个通道
[[5,6],[6,5]],
#第2个通道
[[7.8],[8,7]]]]
input_np=np.array(input,np.float32)
input_tf=tf.constant(input_np,tf.float32)
#[b,c,h,w]---->[b,h,w,c]
input_tf=tf.transpose(input_tf,perm=(0,2,3,1))
output_tf=batch_norm(input_tf,is_trainning=False)
with tf.Session() as sess:
sess.run([tf.global_variables_initializer())
output=sess.run(output_tf)
output=np.transpose(output,axes=(0,3,1,2))
print(output)②使用tf.layers.batch_normalization:
函数tf.layers.batch_normalization是对tf.nn.batch_normalization的封装,其中做的运算与上面自定义的封装函数差不多。使用时大部分参数不用考虑,只关心几个参数的设置。示例:
import tensorflow as tf
import numpy as np
#shape=[batch,c,h,w]
input=[
#第1张图,2通道,宽高2*2
[
#第1个通道
[[1,2],[2,1]],
#第2个通道
[[3,4],[4,3]]],
#第2张图,2通道,宽高2*2
[
#第1个通道
[[5,6],[6,5]],
#第2个通道
[[7.8],[8,7]]]]
input_np=np.array(input,np.float32)
input_tf=constant(input_np,tf.float32)
#[b,c,h,w]---->[b,h,w,c]
input_tf=tf.transpose(input_tf,perm=(0,2,3,1))
output_tf=tf.layers.batch_normalization(input_tf,momentum=0.99,epsilon=0.001,trainning=True)
with tf.Session() as sess:
sess.run([tf.global_variables_initializer())
output=sess.run(output_tf)
output=np.transpose(output,axes=(0,3,1,2))
print(output)使用tf.layers.batch_normalization时需要注意,训练阶段一定要将training设置为True,在Inference阶段一定要将training设置为False,否则得到的结果可能不正确。
TensorFlow中还有一个对Batch Normalization的封装函数tf.contrib.layers.batch_norm,用法与tf
③使用注意事项:
在TensorFlow中,实现Batch Normalization时用到了平滑算法来对均值和方差进行优化。平滑算法主要是根据当前均值和方差及在此前计算的均值和方差的值,重新计算新的均值和方差,并且更新均值和方差变量。
值得主要的是,在训练阶段,更新平滑后的均值和方差op放到了集合tf.GraphKeys.UPDATE _OPS中,这会使更新均值和方差的op与当前训练op没有依赖关系,从图的角度来理解就是从根节点到叶子节点之间的路经没有包含更新均值和方差的计算节点。
在最优化output时,更新均值和方差这一步并没有被执行,这就是导致虽然训练时很好,但在Inference阶段发现得到的结果是错误的,因为均值和方差都还是初始化的值,在学习过程中并没有得到更新。为了避免这个问题,需要在训练时强制执行更新均值和方差的操作,有两个方案可以选择:
⑴方案1:在执行最小化loss之前,先强制执行tf.GraphKeys.UPDATE_OPS集合里面的op,即为最小化loss操作添加依赖关系,参考代码:
update_ope=tf.get_collection(GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op=optimizer.minimize(loss)
sess.run([train_op])⑵方案2:将更新均值和方差的操作与最小化loss操作一起放入tf.Session的run还是中执行,参考代码:
extra_update_ops=tf.get_collection(tf.GraphKeys.UPDATE_OPS)
sess.run([train_op,extra_update_ops])
4. Instance Normalization:
Instance Normalization也是为数据做标准化。
1)Instance Normalization原理:
Instance Normalization的计算公式与Batch Normalization的计算公式一样,区别在于均值和方差的计算方法。Batch Normalization是对输入的一批Batch中对应的通道求均值和方差,而Instance Normalization是对每个Batch中的每个通道单独求均值和方差,得到均值μ和方差σ后,依然需要一个缩放参数scale(γ)和偏移参数offset(β)。计算公式:
当然,二者的缩放参数scale和偏移参数offset都是一样的,都是通过训练学习得到的,一旦模型训练完成,scale和offset也就确定了。
2)TensorFlow中使用Instance Normalization:
TensorFlow中,Instance Normalization函数接口tf.contrib.layers.instance_norm,函数原型:
tf.contrib.layers.instance_norm(
inputs,
center=True,
scale=True,
epsilon=1e-06,
activation_fn=None,
param_initializers=None,
reuse=None,
variables_collections=None,
outputs_collections=None,
trainable=True,
data_format=DATA_FORMAT_NHWC,
scope=None
)各个参数含义及数据类型:
· inputs:Tensor对象,维度大于2的任意Tensor,在卷积神经网络中一般为4维,[N,H,W,C]。
· center:bool类型,如果为True,表示要添加偏移参数offset,默认为True。
· scale:bool类型,如果为True,表示要添加缩放参数scale,默认True。如果后面一层接入的是线性变化(如relu),那么缩放参数scale不会加入,因为线性变化本身也是做缩放。
· epsilon:float类型,为避免分母为0,需要对分母加一个很小的数,默认0.000001。
· activation_fn:函数对象,用于在当前层后面添加一个激活函数,默认None,即不添加。
· param_initializers:字典对象,参数初始化参数,通过字典来指定缩放参数gamma(scale)和偏移参数beta(offset)设置默认初始值。字典对应的key分布为gamma字符串和beta字符串。
· reuse:bool类型,指定当前层变量是否是reuse,如果为True,需要指定scope。
· variables_collections:Tensor对象,当前层的变量存放到指定的集合中。
· outputs_collections:Tensor对象,当前层的输出存放到指定的集合中。
· trainable:bool类型,指定当前层参数是否参与训练。
· data_format:字符串类型,数据维度格式,默认NHWC。
· scope:variable_scope对象,当前层的variable_scope。
先使用TensorFlow的基本函数来自定义Instance Normalization,代码为:
import tensorflow as tf
import numpy as np
#shape=[batch,c,h,w]
input=[
#第1张图,2通道,宽高2*2
[
#第1个通道
[[1,2],[2,1]],
#第2个通道
[[3,4],[4,3]]],
#第2张图,2通道,宽高2*2
[
#第1个通道
[[5,6],[6,5]],
#第2个通道
[[7.8],[8,7]]]]
def instance_norm(x,epsilon=1e-6):
mean,var=tf.nn.moments(x,[1,2],keep_dims=True)
#定义缩放变量scale和偏移变量offset
scale=tf.get_variable('scale',[x.get_shape()[-1]],initializer=constant_initializer(1.0))
offset=tf.get_variable('offset',[x.get_shape()[-1]],initializer=constant_initializer(0.0))
out=scale*tf.div(x-mean,tf.squrt(var+epsilon))+offset
return out,mean,var
input_np=np.array(input,np.float32)
input_tf=tf.constant(input_np,tf.float32)
#[b,c,h,w]---->[b,h,w,c]
input_tf=tf.transpose(input_tf,perm=(0,2,3,1))
output_tf,mean_tf,var_tf=instance_norm(input_tf)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
output,mean,var=sess.run([output_tf,mean_tf,var_tf])
output=np.transpose(output,axes=(0,3,1,2))
print('mean=',mean)
print('var=',var)
print('output=\n',output)然后使用tf.contrib.layers.instance_norm函数来计算Instance Normalization,示例代码:
import tensorflow as tf
import numpy as np
#shape=[batch,c,h,w]
input=[
#第1张图,2通道,宽高2*2
[
#第1个通道
[[1,2],[2,1]],
#第2个通道
[[3,4],[4,3]]],
#第2张图,2通道,宽高2*2
[
#第1个通道
[[5,6],[6,5]],
#第2个通道
[[7.8],[8,7]]]]
input_np=np.array(input,np.float32)
input_tf=tf.constant(input_np,tf.float32)
#[b,c,h,w]---->[b,h,w,c]
input_tf=tf.transpose(input_tf,perm=(0,2,3,1))
initializers={'gamma':tf.ones_initializer,'beta':tf.zeros_initializer}
output_tf=tf.contrib.layers.instance_norm(input_tf,center=True,scale=True,epsilon=1e-06,param_initializers=initializers,trainable=True)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
output=sess.run(output_tf)
output=np.transpose(output,axes=(0,3,1,2))
print(output)如果需要对Instance Normalization里面的参数做其他运算控制,推荐使用自定义函数方式;如果不关心Instance Normalization里面的参数细节,推荐用tf.contrib.layers.instance_norm函数直接调用,相对比较简单,不容易出错。
5. 全连接层:
全连接层本质就是线性方程组问题。
1)全连接层原理:
对全连接层的简单描述,就是将长度为M的向量通过M×N个权重变成长度为n的向量。全连接层可以看成维度空间映射,也可以看成“分类器”,将M个输入分为N类。
假设有长度为4的输入向量(3,4,5,6),要经过全连接层计算得到输出为2的向量,对应权重为(1,1,1,1)和(2,2,2,2),则全连接层计算过程为:


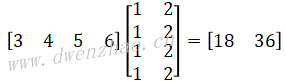
在TensorFlow中,可以使用函数tf.layers.dense来计算全连接层,函数原型:
tf.layers.dense(
inputs,
units,
activation=None,
use_bias=True,
kernel_initializer=None,
bias_initializer=tf.zeros_initializer(),
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
trainable=True,
name=None,
reuse=None
)各个参数的含义及数据类型:
· inputs:Tensor对象,维度大于2的任意Tensor,其中第1个维度一般是Batch,第2个维度是对应的一维向量。
· units:整型或长整型,表示输出向量的长度。
· activation:函数类型,表示全连接层后面连接的激活函数。
· use_bias:bool类型,表示是否添加偏移量。
· kernel_initializer:函数类型,权重初始化函数。
· bias_initializer:函数类型,偏移量参数初始化函数。
· kernel_regularizer:函数类型,权重矩阵的正则化函数。
· bias_regularizer:函数类型,偏移量的正则化函数。
· activity_regularizer:函数类型,输出的正则化函数。
· kernel_constraint:函数类型,权重矩阵的约束项。
· bias_constraint:函数类型,偏移量的约束项。
· trainable:bool类型,指定当前层参数是否参与训练。
· name:字符串类型,当前层的名称。
· reuse:bool类型,是否重用当前层参数变量。
函数的参数虽然很多,但实际常用到的参数只有少数几个。示例:
import tensorflow as tf
import numpy as np
#input shape=[batch,length]=[1,4]
input=[[3,4,5,6]]
#weights shape=[]
weights=[[1,1,1,1],[2,2,2,2]]
input_tf=tf.constant(input,dtype=tf.float32)
#转置,为了计算input*weights
weights=np.transpose(weights,(1,0))
weight_init=tf.constant_initializer(weights)
#[1,4]---->[1,2]
output_tf=tf.layers.dense(input_tf,2,kernel_initializer=weights_init,name='fc')
print(output_tf)
with tf.Session() as sess:
#初始化变量
sess.run(tf.global_variables_initializer())
#执行全连接层计算,得到结果
output=sess.run(output_tf)
print(output)使用函数tf.layers.dense计算全连接层时,按output=input×WT方式进行矩阵相乘,因此代码中对权重矩阵做了转置,后面将定义的权重数据作为初始值赋值给全连接层权重,并执行全连接层计算。输出结果:
[[18. 36.]]
6. 激活函数:
在生物学理论中,大脑中有大量神经元,每个神经元功能不同。当有信号传入时,有些神经元会变得很活跃,但有些神经元却不做任何表现,激活函数与这个过程类似。激活函数也将需要处理的信号往后传输,将不关心的信号丢弃。激活函数是非线性函数,有很多种。
1)激活函数的作用:
在神经网络中,每一层的计算都是线性函数,因此不管网络有多少层,其本质都相当于是一层线性函数计算,这严重消弱了神经网络的能力。因此需要在每一层加入非线性函数,增强神经网络的表达能力和模型学习能力。
在神经网络中,传入的信号可能有很多特征,希望保留关心的特征并且淡化不关心的特征。激活函数能在训练过程中根据loss和梯度数据,将不关心的特征变小并把关心的特征往后传递,这能够起到自动特征提取的作用。激活函数具有的性质:
· 非线性:激活层需要非线性才有意义
· 可微性:在训练模型时,反向传播需要根据每一层的梯度更新权值,因此需要保证激活函数可微
· 单调性:单调性能简化网络结构,并且保证单程网络是凸函数。
· 值域在固定常数区间:激活函数的输出在固定常数区间会使得梯度更新算法更加稳定。
目前主流的激活函数是分段的线性函数(如relu)和指数形式的非线性函数(如Sigmoid)。
2)Sigmoid函数:
Sigmoid函数的值域为(0,1),也就是无论输入多大或多小,经过Sigmoid后将处于(0,1)区间。函数表达式:
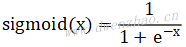
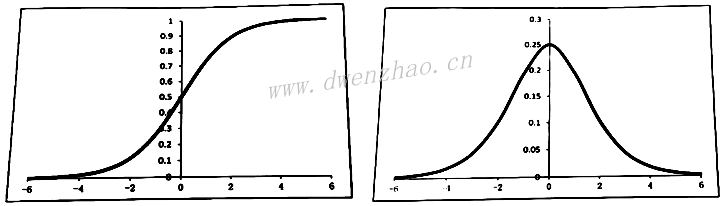
Sigmoid函数存在一些不足,其导数值域在0到0.25之间,导致反向传播过程中,每经过一次Sigmoid函数,传播的梯度更新取值会变成上一层的1/4。随着层数的增多,往前传播的梯度趋于0,即Sigmoid函数会产生梯度消失的问题。
另一个问题是,由于Sigmoid函数的值域是(0,1),意味着经过Sigmoid函数后输出值永远是大于0而没有小于0的输出,并且被束缚在(0,1)区间,这会导致训练过程中梯度变得不稳定。
虽然Sigmoid存在一些缺点,但如果只是在网络最后一层使用Sigmoid函数并不会受到这些缺点影响,比如在分类模型中,最后一层需要将数据规范化到(0,1),往往都是采用Sigmoid函数。
TensorFlow中,可以通过tf.nn.sigmoid函数或tf.sigmoid函数来使用Sigmoid计算。这两个函数的参数一致,tf.sigmoid函数的原型:
tf.sigmoid(
x,
name=None
)各个参数含义及数据类型:
· x:Tensor对象,任意维度的Tensor对象,存储的数据类型只能是float16、float32、float64、complex64、complex128中的一种。
· name:字符串类型,用于指定当前Sigmoid计算的名称。
3)Tanh函数:
Tanh函数的值域为(-1,1),无论输入多大或多小,经过Tanh后将处于(-1,1)区间。函数表达式:
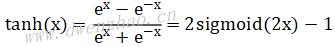

在TensorFlow中,可以通过函数tf.nn.tanh和tf.tanh计算Tanh,这两个函数的参数和用法是一样的。Tf.tanh的函数原型:
tf.tanh(
x,
name=None
)各个参数的含义及数据类型:
· x:Tensor对象,任意维度的Tensor对象,存储的数据类型只能是float16、float32、double、complex64、complex128中的一种。
· name:字符串类型,用于指定当前Tanh计算的名称。
4)ReLU函数:
ReLU函数的全称是线性整流函数(Rectified Linear Unit),或者称为修正线性单元,是分段线性函数,将小于0的数置为0,大于0的数不做修改。ReLU是在卷积神经网络中最常使用、最受欢迎的激活函数。ReLU函数的函数表达式f(x)=max(0,x),而导数表达式为:
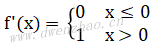
ReLU函数还有其他变种,如ReLU6,函数表达式:
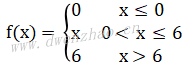
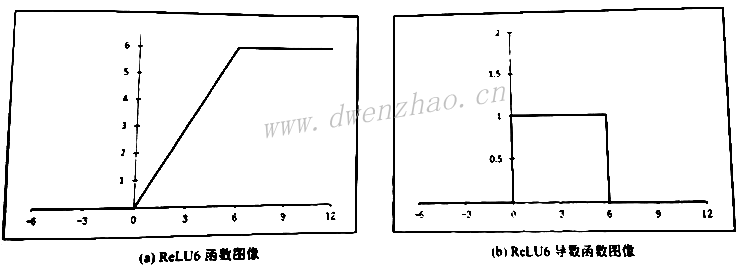
ReLU虽然有其优势,但也有一些不足,主要是虽然前期可以加快收敛速度,但是在训练后期非常脆弱,很容易出现梯度为0的情况。这主要是因为ReLU函数中小于0的梯度为0,即使反向传播的梯度很大,经过ReLU后也变为0。为了解决这个问题,出现了ReLU的改进版--Leaky-ReLU,其函数表达式为:
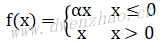
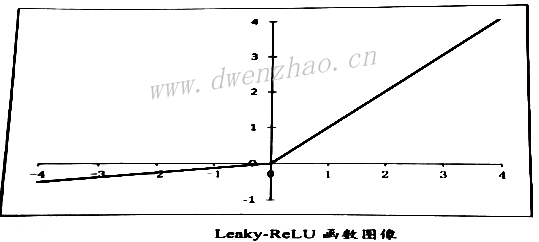
实际项目中,有时候并不需要逐个进行ReLU实验,因为在某些应用领域,前辈已经通过大量实验得出了最合适得选择。
7. 池化层:
当卷积的stride参数大于1,得到的输出Feature Map的宽高比输入的Feature Map要小,可以看成下采样的过程。在卷积神经网络中,池化层(Pooling层)主要用来做下采样的操作。
1)池化层原理:
池化层操作与卷积操作过程类似,不同的是池化层不需要参数与输入进行计算。池化层有个窗口概念,窗口是用于设置每个被选取做pooling操作的区域的参数,与卷积计算中卷积核的宽高很像。池化层也有stride和padding参数,含义与卷积计算中的基本一致。
当Padding方式为SAME时,池化层会在边界填充,但边界填充的数不会参与计算,只是用于占位。边界填充的行与列的数量计算公式与卷积补0的行与列的数量计算公式一致。
Padding方式为VALID时,不会做填充操作,当有剩余行和列时会被丢弃。关于输出宽高与输入、stride、卷积核及Padding的关系也与卷积一致。
池化层有最大值池化Max Pooling和均值池化Avg Pooling。在计算最大值池化和均值池化时,边界补的数只是为了方便计算输出的宽高。实际上可以将边界填充的区域看成不参与计算的区域,最大值池化边界是镜像填充,均值池化是边界补0。最大值池化中,边界填充的数相当于填充负无穷;均值池化中,只会将当前窗口中非填充区域的所有元素的均值作为输出。
最大值池化,就是选取输入数据在窗口中的最大值作为输出,并存放到输出的对应位置;而均值池化,则是计算输入数据在窗口中数据的均值作为输出,并存放到输出的对应位置。
2)TensorFlow中使用池化:
常见的池化层有最大值池化和均值池化。TensorFlow中提供了池化层函数接口,tf.nn.max _pool函数对应最大值池化,tf.nn.avg_pool对应均值池化。函数原型:
tf.nn.max_pool(
value,
ksize,
stride,
padding,
data_format='NHWC',
name=None
)
tf.nn.avg_pool(
value,
ksize,
strides,
padding,
data_format='NHWC',
name=None
)
两个函数的参数一致,不同之处在于一个是取窗口中的最大值,一个是取窗口内所有元素的均值。参数含义与数据类型:
· value:四维Tensor对象,为输入,每个维度的含义由data_format指定。
· ksize:一维list,长度为4的列表,表示在data_format指定的每个维度上取的窗口的大小。
· strides:一维list,长度为4的列表,表示在data_format指定的每个维度上的stride的大小。
· padding:字符串类型,只能取SAME或VALID。
· data_format:字符串类型,支持NHWC、NCHW、NCHW_VECT_C格式。
· name:字符串类型,表示当前Pooling操作节点的名称。
最大值池化边界是镜像填充,均值池化是边界补0。示例代码:
import tensorflow as tf
import numpy as np
input=[[[[-1,-2,3,1],[-2,-1,2,1],[3,2,-1,-2],[4,1,-4,-9]]]]
def pooling(input,pool_type,ksize,stride,padding)
stride=[1,stride,stride,1]
ksize=[1,ksize,ksize,1]
output=None
if pool_tyep=='MAX_POOL':
output=tf.nn.max_pool(input,ksize,stride,padding)
elif pool_type=='AVG_POOL':
output=tf.nn.avg_pool(input,ksize,stride,padding)
else:
raise "Unknow "+str(pool_type)
return output
input_tf=tf.constant(np.array(input),tf.float32)
input_tf=tf.transpose(input_tf,perm=(0,2,3,1))
output_tf=pooling(input_tf,'MAX_POOL',ksize=3,stride=2,padding='SAME')
#output_tf=pooling(input_tf,'MAX_POOL',ksize=3,stride=2,padding='VALID')
#output_tf=pooling(input_tf,'AVG_POOL',ksize=3,stride=2,padding='SAME')
#output_tf=pooling(input_tf,'AVG_POOL',ksize=3,stride=2,padding='VALID')
with tf.Session() as sess:
output=sess.run(output_tf)
output=np.transpose(output,axis=(0,3,1,2))
print(output)
8. Dropout:
在深度神经网络中,如果参数过多而且训练样本较少时,很容易过拟合。也就是说,训练集上的数据学得很好,但是测试集却很差,即泛化能力差。Dropout就是为了防止过拟合的一种操作。
1)Dropout的作用:
深度神经网络中,训练的目的是让网络的最终输出与真实的Label无限接近。每一层的参数与其上一层的参数紧密相关,对于一个训练好的模型,如果将某一层参数做修改,那么模型最终的输出与未修改之前的输出千差万别。也就是说,每个神经元相互之间共适应性很强。各个神经元之间相互协调,共同促进整个网络模型收敛。但有时候,正是因为各个神经元之间协调得太好,这种协调没有对未知数据兼容,导致模型过拟合。
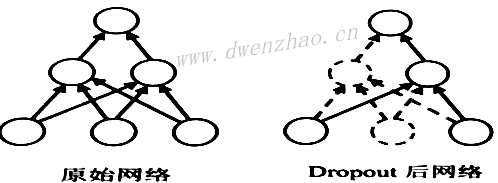
为了防止各个神经元之间过于依赖,Dropout在训练过程中,会随机隐藏一些神经元。在卷积神经网络中,Dropout一般用在全连接层,其他层一般不用Dropout。Dropout在训练过程中得操作如图所示,其中虚线部分表示被隐藏的节点:
在训练阶段才用到Dropout,当模型训练完成后,Dropout层不能再继续作用在模型中。也就是说,在训练阶段Dropout概率参数取值为(0,1),即被隐藏概率在0和1之间,但是在测试和验证阶段要将概率参数设为1,即所有神经元都不被隐藏。在训练阶段,并不是固定选择被隐藏的神经元,而是通过随机选择神经元使其被隐藏。
2)TensorFlow中使用Dropout:
在TensorFlow中,函数tf.nn.dropout用于执行Dropout操作。函数原型:
tf.nn.dropout(
x,
keep_prob,
noise_shape=None,
seed=None,
name=None
)各个参数含义及数据类型:
· x:Tensor对象,数据类型为浮点型的Tensor。
· keep_prob:Tensor对象,取值为[0,1]的数,表示当前节点不被隐藏的概率。
· noise_shape:Tensor对象,一维整型向量,表示随机生成的隐藏和不隐藏的标识的shape。
· seed:整数类型,用于裁剪随机种子。
· name:字符串类型,当前Dropout操作的名称。
下面以全连接为例,假设全连接层输入的有6个节点,分别为[1,2,3,4,5,6],输出有3个节点,那么一共有6×3=18个参数。为了简化理解不失一般性,假设所有的参数均为1,那么全连接层计算,经过Dropout的计算过程如图:
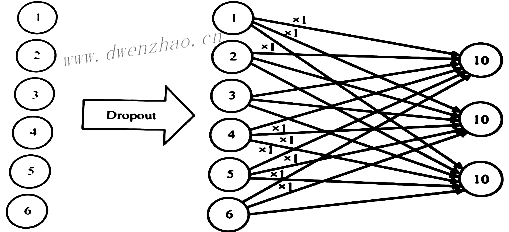
import tensorflow as tf
input=[[1,2,3,4,5,6]]
input_tf=tf.constant(input,tf.float32)
#将系数全部设置为1
weights_tf=tf.ones(shape=[6,3],name="Weights")
#将输入的每个元素以0.5概率隐藏后,作为新的输入
input_tf=tf.nn.dropout(input_tf,keep_prob=0.5)
#对新的输入做矩阵乘法
output_tf=tf.matmul(input_tf,weights_tf)
with tf.Session() as sess:
output=sess.run(output_tf)
#由于随机性,每次打印的结果不一样
print(output)需要注意,在测试或者验证阶段,需要将keep_prob参数设置为1。由于随机性,每次输出的结果都不一样。
四、常见卷积神经网络:
近些年,卷积神经网络经历了高速发展,研究人员总结出了一些高效、快速及易收敛等特性的卷积神经网络结构,如MobileNet、ResNet、DenseNet等。
1. 移动端定制卷积神经网络MobileNet:
MobileNet是Google在2017年提出的一种适合移动端运行的网络结构,在图像分类、目标检测及图像分割等领域有着巨大优势,2018年进一步提出MobileNet V2。
1)MobileNet的原理及优势:
MobileNet把卷积核为k×k的卷积拆分成两步,第1步是按通道维度执行卷积核为k×k的卷积计算,第2步则是将第1步的输出结果用大小为1×1的卷积核进行普通的卷积运算。简单来说,就是大的卷积核按通道方向执行卷积,用小的1×1的卷积核对输出维度做变换。
MobileNet卷积的两个步骤分别称为Depthwise和Pointwise卷积。

· Depthwise卷积:使用大卷积核,3×3的卷积核,每个通道对应一个卷积核执行卷积计算,得到的输出通道数量与输入通道数量一致。
· Pointwise卷积:由于普通卷积得到的通道为2,而Depthwise输出通道为3,二者不一致,通过Pointwise卷积计算,使用1×1的卷积核,按照普通卷积计算算法,将输出通道设置为期望的通道数。
MobileNet使用Depthwise+Pointwise的优势在于,对于大卷积核计算卷积部分,通道维度没有发生变化,使得计算量和参数数量大大压缩;而对于通道变换部分,使用小卷积核计算,将计算量和参数数量压缩。
设输入shape=(Hin,Win,Cin),卷积核高宽(Hf,Wf),输出shape=(Hout,Wout,Cout)。普通卷积,参数量Cin
实际项目中,通道数量往往是好几百,中间层的Feature Map宽高也远大于3,使用MobileNet卷积方式可以大大提升运算速度,减少计算量和参数数量。虽然计算量大幅减少,采用Depthwise+Pointwise卷积可以近似等于普通卷积,在实际训练中精度几乎不会有明显降低。
2)TensorFlow中实现MobileNet:
TensorFlow中,函数tf.nn.depthwise_conv2d用于实现Depthwise卷积计算,函数原型:
tf.nn.depthwise_conv2d(
input,
filter,
strides,
padding,
rate=None,
name=None,
data_format=None
)各个参数的含义及数据类型:
· input:4维Tensor对象,数据格式可以是NHWC或NCHW,由参数data_format决定。
· filter:4维Tensor对象,shape=[filter_height,filter_width,in_channels,channel_multiplier],其中,filter
· strides:是一个长度为4的一维列表,分别表示data_format指定的数据格式中每个维度的stride值。
· padding:字符串对象,可以取SAME或VALID。
· rate:长度为2的一维列表,分别表示空洞卷积在高维度和宽维度数据采样间隔比例。如果该值大于1,那么strides参数的所有值必须等于1。
· name:字符串类型,表示当前Operation的名称。
· data_format:字符串类型,只能取NHWC或NCHW,默认NHWC。
函数tf.nn.depthwise_conv2d输出维度为4的Tensor对象,将Depthwise卷积和Pointwise卷积合在一起的示例:
import tensorflow as tf
import numpy as np
#输入shape=[N,C,H,W]
input=[[
[[2,3,-1,3],[1,4,1,-1],[2,0,4,-3],[4,2,1,2]],
[[3,2,0,1],[1,-4,1,0],[-1,2,3,1],[2,3,5,-2]],
[[-1,2,3,5],[3,-2,-1,2],[4,-5,2,0],[5,1,0,1]]
]]
#shape=[in_channels,filter_height,filter_width]
depthwise_filters=[
[[1,-1,2],[1,0,1],[2,1,0]],
[[1,2,1],[0,2,0],[3,1,1]],
[[1,1,0],[2,0,1],[1,3,2]]
]
#shape=[out_channels,in_channels,filter_height,filter_width]
pointwise_filter=[
[[[-1]],[[1]],[[2]]],
[[[2]],[[1]],[[3]]]
]
def DepthSepConv(input_tf,stride,kernel_size,out_channels,layer_name,relu=tf.nn.relu6
with tf.variable_scope(layer_name+'_depthwise'):
in_size=input_tf.get_shape().as_list()
strides=[1,stride,stride,1]
#dw_kernel_shape=[filter_height,filter_width,in_channels,channels_multiplier]
dw_kernel_shape=[kernel_size,kernel_size,in_size[3],1]
dw_kernel=tf.get_variable('depthwise_weights',dw_kernel_shape,tf.float32
x=tf.nn.depthwise_conv2d(input_tf,dw_kernel,strides,padding='SAME',name=layer_name+'_depthwise')
if batchNorm:
x=tf.contrib.layers.batch_norm(x,center=True,decay=0.9997
if not relu is None:
x=relu(x)
with tf.variable_scope(layer_name+'_pointwise'):
#pointwise conv
pw_kernel_shape=[1,1,in_size[3],out_channels]
pw_kernel=tf.get_variable('weights',pw_kernel_shape,tf.float32,pointwise
x=tf.nn.conv2d(x,pw_kernel,[1,1,1,1],padding='SAME')
if batchNorm:
x=tf.contrib.layers.batch_norm(x,center=True,decay=0.9997,scale=True
if not relu is None:
x=relu(x)
return x
def main():
input_tf=tf.Variable(input,dtype=tf.float32)
#[N,C,H,W]--->[N,H,W,C]
input_tf=tf.transpose(input_tf,(0,2,3,1))
#[in_channels,filter_height,filter_width]
#转为[filter_height,filter_width,in_channels]
depthwise_weights=np.transpose(np.array(depthwise_filters),(1,2,0))
#[filter_height,filter_width,in_channels]
#转为[filter_height,filter_width,in_channels,channel_multiplier]
depthwise_weights=np.expand_dims(depthwise_weights,axis=3)
depthwise_initializer=tf.constant_initialzer(depthwise_weights)
pointwise_weights=np.array(pointwise_filters)
#[out_channels,in_channels,filter_height,filter_width]
#转为[filter_height,filter_width,in_channels,out_channels]
pointwise_weights=np.transpose(pointwise_weights,(2,3,1,0))
pointwise_initializer=tf.constant_initialzer(pointwise_weights)
output_tf=DepthSepConv(input_tf,stride=1,kernel_size=3
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
output=sess.run(output_tf)
#NHWC--->NCHW
output=np.transpose(output,(0,3,1,2))
print(output)
if __name__=='__main__':
main()3)使用Python实现的Depthwise卷积:
import tensorflow as tf
import numpy as np
#输入shape=[C,H,W]
input=[
[[2,3,-1,3],[1,4,1,-1],[2,0,4,-3],[4,2,1,2]],
[[3,2,0,1],[1,-4,1,0],[-1,2,3,1],[2,3,5,-2]],
[[-1,2,3,5],[3,-2,-1,2],[4,-5,2,0],[5,1,0,1]]
]
#shape=[in_channels,filter_height,filter_width]
depthwise_filters=[
[[1,-1,2],[1,0,1],[2,1,0]],
[[1,2,1],[0,2,0],[3,1,1]],
[[1,1,0],[2,0,1],[1,3,2]]
]
#shape=[out_channels,in_channels,filter_height,filter_width]
pointwise_filter=[
[[[-1]],[[1]],[[2]]],
[[[2]],[[1]],[[3]]]
]
def compute_conv(fm,kernel):
'''
#对单个通道计算卷积核大小为3×3的卷积
#这里Padding=SAME,stride=1,卷积核大小3×3
fm: Shape=[in_h,int_w],某个通道
kernel: Shape=[3,3], fm对应的卷积核
return rs: Shape=[out_h,out_w]
'''
fm=np.array(fm)
kernel=np.array(kernel)
[h,w]=fm.shapw
[k,_]=kernel.shape
assert k==3,"Just Support kernel with Shape=[3,3]!"
#定义边界填充0后的map
padding_fm=np.zeros([h+2,w+2],np.float32)
#保存计算结果
rs=np.zeros([h,w],np.float32)
# 将输入在指定该区域赋值,即除了4个边界后,剩下的区域
padding_fm[1:h_1,w+1]=fm
# 对每个点为中心的区域遍历
for i in range(1,h+1):
for j in range(1,w+1):
#取出当前点为中心的k*k区域
roi=padding_fm[i-1:i+2,j-1:j+2]
#计算当前点的卷积,对k*k个点相乘后求和
rs[i-1][j-1]=np.sum(roi*kernel)
return rs
def MyDepthSepConv(CHW_input,depthwise_kernel,pointwise_kernel):
#Depthwise
depthwise_output=[]
for hw,depth_weights in zip(CHW_input,depthwise_kernel):
rs=compute_conv(hw,depth_weights)
depthwise_output.append(rs)
depthwise_output=np.array(depthwise_output)
c,h,w=depthwise_output.shape
output=[]
#Pointwise
for points_kernels in pointwise_kernel:
rs=np.zeros((h,w),dtype=np.float32)
#points_kernels shape=[in_channels,f_height,f_width]
for filter,fm in zip(points_kernels,depthwise_output);
rs=rs+filter[0][0]*fm
output.append(rs)
return np.array(output)
def main():
output=MyDepthSepConv(input,depthwise_filters,pointwise_filters)
print(output)
if __name__=='__main__':
main()上述代码只适用于卷积核3×3、Padding=SAME、stride=1的单通道输入和单通道输出卷积计算,可以扩充到任意自定义参数。
4)MobileNet完整的网络结构:
MobileNet对每一层卷积(包括Depthwise和Pointwise)添加了Batch Normalization和ReLU6计算,且卷积后面没有加bias项。基础网络结构见下表:
| 网络层 | Stride | 卷积核shape [height,width,in_c,out_c] |
输入shape [height,width,channel] |
输出shape [height,width,channel] |
|
|---|---|---|---|---|---|
| Conv | 2 | [3,3,3,32] | [224,224,3] | [112,112,32] | |
| Depthwise | 1 | [3,3,32,32] | [112,112,32] | [112,112,32] | |
| Pointwise | 1 | [1,1,32,64] | [112,112,32] | [112,112,64] | |
| Depthwise | 2 | [3,3,64,64] | [112,112,64] | [56,56,64] | |
| Pointwise | 1 | [1,1,64,128] | [56,56,64] | [56,56,128] | |
| Depthwise | 1 | [3,3,128,128] | [56,56,128] | [56,56,128] | |
| Pointwise | 1 | [1,1,128,128] | [56,56,128] | [56,56,128] | |
| Depthwise | 2 | [3,3,128,128] | [56,56,128] | [28,28,128] | |
| Pointwise | 1 | [1,1,128,256] | [28,28,128] | [28,28,256] | |
| Depthwise | 1 | [3,3,256,256] | [28,28,256] | [28,28,256] | |
| Pointwise | 1 | [1,1,256,256] | [28,28,256] | [28,28,256] | |
| Depthwise | 2 | [3,3,256,256] | [28,28,256] | [14,14,256] | |
| Pointwise | 1 | [1,1,256,512] | [14,14,256] | [14,14,512] | |
| 5x | Depthwise | 1 | [3,3,512,512] | [14,14,512] | [14,14,512] |
| Pointwise | 1 | [1,1,512,512] | [14,14,512] | [14,14,512] | |
| Depthwise | 2 | [3,3,512,512] | [14,14,512] | [7,7,512] | |
| Pointwise | 1 | [1,1,512,1024] | [7,7,512] | [7,7,1024] | |
| Depthwise | 1 | [3,3,1024,1024] | [7,7,1024] | [7,7,1024] | |
| Pointwise | 1 | [1,1,1024,1024] | [7,7,1024] | [7,7,1024] | |

为了进一步提升模型执行速度及裁剪网络参数,Google在2018年发布MobileNet V2,使用了更少的参数和更少的计算量,却有更高的精度。
MobileNet V2引入shortcut,并采用Pointwise+Depthwise+Pointwise结构取代标准卷积计算。

MobileNet V2多了一层Pointwise,看上去会有更多参数和计算量,但第1层Pointwise会将通道数放大N倍(官方采用6倍),但MobileNet V2的Block输入和输出通道数远比MobileNet V1小,大部分V1的Cin远大于V2的Cin。MobileNet V2的完整网络结构见下表:
| Input | Operator | t | Channels | n | s |
|---|---|---|---|---|---|
| 224×224×3 | Conv2d | - | 32 | 1 | 2 |
| 112×112×32 | Bottleneck | 1 | 16 | 1 | 1 |
| 112×112×16 | Bottleneck | 6 | 24 | 2 | 2 |
| 56×56×24 | Bottleneck | 6 | 32 | 3 | 2 |
| 28×28×32 | Bottleneck | 6 | 64 | 4 | 2 |
| 28×28×64 | Bottleneck | 6 | 96 | 5 | 1 |
| 14×14×96 | Bottleneck | 6 | 160 | 5 | 2 |
| 7×7×160 | Bottleneck | 6 | 320 | 1 | 1 |
| 7×7×320 | Conv2d 1×1 | - | 1280 | 1 | 1 |
| 7×7×1280 | Avgpool 7×7 | - | - | 1 | - |
| 1×1×k | Bottleneck | - | k | - | - |
2. 深度残差网络ResNet:
深度残差网络Deep Residual Network于2015年被提出,在当年的ImageNet分类比赛中获得第一名。ResNet简单、实用。
1)ResNet的结构与优势:
理论上,随着网络深度加深,参数量变多,网络模型的精度会变高。实际上,随着网络的加深,当深度达到一定程度时,在训练集中准确率反而会变差,这主要是因为梯度消失的问题。随着网络的加深,梯度反向传播到前面层,连续的梯度乘法很容易使得梯度无穷小。
梯度消失带来的后果就是,网络的性能随着深度的加深趋于饱和,甚至退化,使得深层次网络很难训练。ResNet由多个卷积Block组成,其卷积Block如左图:
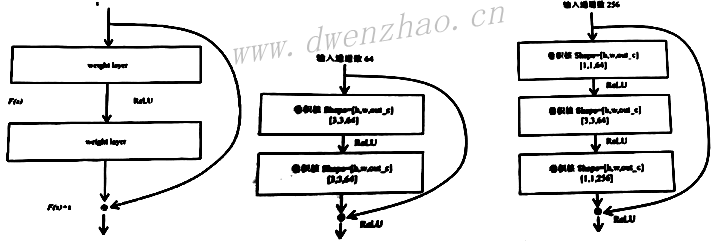
注意,在使用shortcut对Block的输入和输出做加法时,如果通道维度不一样,shortcut会增加一个1×1卷积对Block输入做卷积运算,使得加法计算的两个输入通道维度一致。
2)TensorFlow中实现ResNet:
TensorFlow官方实现了ResNet,中图Block的源码为:
#创建Block
def _building_block_v1(inputs,filters,training,projection_shortcut,strides,data_format):
#保留输入的引用
shortcut=inputs
#如果输入通道数与输出通道数不一致,则通过传入projection_shortcut变换,即1×1卷积
if projection_shortcut is not None:
#projection_shortcut函数是1×1卷积计算
shortcut=projection_shortcut(inputs)
shortcut=batch_norm(inputs=shortcut,training=training
#执行3×3卷积运算,输出指定通道数为filters
inputs=conv2d_fixed_padding(inputs=inputs,filters=filters
#执行BatchNorm
inputs=batch_norm(inputs,training,data_format)
#ReLU激活函数
inputs=tf.nn.relu(inputs)
#执行3×3卷积运算,输出指定通道数filters
inputs=conv2d_fixed_padding(inputs=inputs,filters=filters
#执行BatchNorm
inputs=batch_norm(inputs,training,data_format)
#实现shortcut,即对输入与输出做加法计算
inputs+=shortcut
inputs=tf.nn.relu(inputs)
return inputs代码中连续执行两次3×3卷积运算,并在每次卷积后面加入Batch Normalization和ReLU激活函数。最后执行shortcut路经中的加法计算。而右图Block(Bottleneck模块)源代码:
#创建Block
def _bottleneck_block_v1(inputs,filters,training,projection_shortcut,strides,data_format):
#保留输入的引用
shortcut=inputs
#如果输入通道数与输出通道数不一致,则通过传入projection_shortcut变换,即1×1卷积
if projection_shortcut is not None:
#projection_shortcut函数是1×1卷积计算
shortcut=projection_shortcut(inputs)
shortcut=batch_norm(inputs=shortcut,training=training
#执行kernels_size=1×1,stride=1卷积运算,输出指定通道数为filters
inputs=conv2d_fixed_padding(inputs=inputs,filters=filters,
#执行BatchNorm
inputs=batch_norm(inputs,training,data_format)
#ReLU激活函数
inputs=tf.nn.relu(inputs)
#执行kernels_size=3×3卷积运算,输出指定通道数为filters
inputs=conv2d_fixed_padding(inputs=inputs,filters=filters
#执行BatchNorm
inputs=batch_norm(inputs,training,data_format)
#ReLU激活函数
inputs=tf.nn.relu(inputs)
#执行kernels_size=1×1,stride=1卷积运算,输出指定通道数为4*filters
inputs=conv2d_fixed_padding(inputs=inputs,filters=4*filters
#执行BatchNorm
inputs=batch_norm(inputs,training,data_format)
#实现shortcut,即对输入与输出做加法计算
inputs+=shortcut
inputs=tf.nn.relu(inputs)
return inputs代码中分别做1×1、3×3、1×1的卷积运算,并且在每次卷积后面加入Batch Normalization和ReLU激活函数。最后执行shortcut路经的加法运算。
2016年,ResNet作者提出了升级版V2,TensorFlow官方源码中也实现了ResNet V2,可查看https:
3)完整的ResNet网络结构:
ResNet按照有训练参数的网络层(包括卷积层和全连接层)的层数,可以分为ResNet34、ResNet50、ResNet101、ResNet152,下表为ResNet34和ResNet50的完整网络结构:
| ResNet34 [height×width,out_channels]×repeat_n |
ResNet50 [height×width,out_channels]×repeat_n |
|---|---|
| [7×7,64],stride=2 | |
| 3×3 max pool, stride=2 | |
|
|
|
|
|
|
|
|
| Average pool, 1000-d fc, softmax | |
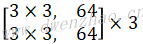
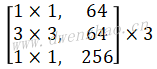
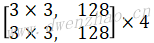
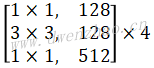
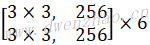
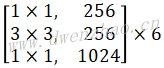
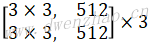
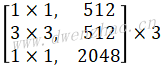
3. DenseNet:
DenseNet全称是Dense Convolutional Network,于2017年提出,其借鉴了ResNet的思想,采用了全新的结构,网络结构并不复杂。
1)DenseNet的结构和优势:
近年的研究表明,如果将前面的网络层通过shortcut连接到后面的网络层,卷积神经网络可以增加更多层,精度更高,并且可以更高效地训练模型。DenseNet由多个DenseBlock和TransitionBlock组成,1个DenseBlock由多个BottleneckBlock组成,TransitionBlock由1个1×1的卷积、Batch Normalization、ReLU及Pooling层组成。
DenseNet借鉴了shortcut的思想,在一个DenseBlock中,将所有层连接起来。若1个DenseNet有L层Bottleneck,那么DenseNet中会有L×(L+1)/2个连接。换言之,DenseBlock中的每一层的输入来自于前面所有层的输出。DenseBlock+TransitionBlock结构如下图:
DenseNet采用了更多的shortcut,显然减轻了梯度消失问题;另外,shortcut将特征往后传递,使得后面的网络层能够利用前面网络层提取的特征。DenseNet的Block中的Grow Rate为32,通过shortcut的concat的方式降低了参数量。
2)TensorFlow中实现DenseNet:
DenseNet由多个Dense Block和Trition Block组成,因此需要实现Dense Block和Transition Block。为了复用代码及增加可读性,先把Block中需要调用的卷积、Batch Normalization及Bottleneck单独封装:
def conv(x,layer_name,kernel_size,stride,out_chan,is_training=True
with ts.variable_scope(layer_name,reuse=reuse)
in_size=x.get_shape().as_list()
stride=[1,stride,stride,1]
kernel_shape=[kernels_size,kernels_size,on_size[3],out_chan]
#conv
kernel=tf.get_variable('weights',kernel_shape,tf.float32
x=tf.nn.con2d(x,kernel,strides,padding=padding_style)
if bias:
#bias
biases=tf.get_variable('biases',[kernel_shape[3]]
x=tf.nn.bias_add(x,biases,name='add')
return x
def batch_norm(input,eps=1.1e-5,is_training=True):
return tf.contrib.layers.batch_norm(input,center=True,decay=0.9997
def bottleneck_layer(x,bottleneck_name,nb_filter,dropout_keep_prob=None,is_training=True,reuse=False):
with tf.variable_scope(bottleneck_name,reuse=reuse):
eps=1.1e-5
#1×1卷积
inter_channel=nb_filter*4
x=batch_norm(x,eps=eps,is_training=is_training)
x=tf.nn.relu(x)
x=conv(x,'bottleneck_1',kernel_size=1,stride=1,out_chan=nb_filter
if dropout_keep_prob:
x=tf.nn.dropout(x,dropout_keep_prob)
#3×3卷积
x=batch_norm(x,eps=eps,is_training=is_training)
x=tf.nn.relu(x)
x=conv(x,'bottleneck_2',kernel_size=3,stride=1,out_chan=nb_filter
if dropout_keep_prob:
x=tf.nn.dropout(x,dropout_keep_prob)
return x有了上面定义的基础网络结构后,接着要组装DenseBlock和TransitionBlock:
'''
x:输入
transition_block_name: 当前TransitionBlock名称
nb_filter: 输出Ferture Map通道数
compression:实际输出通道比例,即为nb_filter*compression
dropout_keep_prob: dropout中参数保留率
is_training: 指定当前是inference还是training
reuse: 指定参数reuse
'''
def transition_block(x,transition_block_name,nb_filter,compression=1.0
with tf.variable_scope(transition_block_name,reuse=reuse):
eps=1.1e-5
x=batch_norm(x,eps=eps,is_training=is_training)
x=tf.nn.relu(x)
x=conv(x,'conv',kernel_size=1,stride=1
if dropout_keep_prob:
x=tf.nn.dropout(x,dropout_keep_prob)
x=tf.nn.avg_pool(x,[1,2,2,1],strides=[1,2,2,1]
return x
'''
dense_block_name: 当前DenseBlock名称
bottleneck_layers: 指定当前DenseBlock的Bottleneck的层数
nb_filter: 输出Feature Map的通道数
growth_rate: 指定growth_rate
dropout_keep_prob: dropout中参数保留概率
is_training: 指定当前是inference还是training
reuse:指定参数reuse
'''
def dense_block(x,dense_block_name,bottleneck_layers,nb_filter
with tf.variable_scope(dense_block_name,reuse=reuse):
for i in range(bottleneck_layers):
bottleneck_out=bottleneck_layer(x,'bottle_%d'%i
x=tf.concat([x,bottle_out],axis=-1)
nb_filter+=growth_rate
return x,nb_filter有了DenseBlock和TransitionBlock后,就可以利用这些Block组装成完整的DenseNet。
3)完整的DenseNet网络结构:
通过修改DenseBlock中的Bottleneck层数,可以将DenseNet中的网络层数设置为121、169、201、264层,即DenseNet-121、DenseNet-169、DenseNet-201、DenseNet-264。完整的DenseNet结构见下表:
| 网络层 | 输出宽高 | DenseNet-121 | DenseNet-169 | DenseNet-201 | DenseNet-264 |
|---|---|---|---|---|---|
| Conv | 112×112 | 7×7 Conv, stride=2 | |||
| Pooling | 56×56 | 3×3 max pool, stride=2 | |||
| DenseBlock | 56×56 |
|
|
|
|
| TransitionBlock | 56×56 | 1×1 Conv | |||
| 28×28 | 2×2 avg pool, stride=2 | ||||
| DenseBlock | 28×28 |
|
|
|
|
| TransitionBlock | 28×28 | 1×1 Conv | |||
| 14×14 | 2×2 avg pool, stride=2 | ||||
| DenseBlock | 14×14 |
|
|
|
|
| TransitionBlock | 14×14 | 1×1 Conv | |||
| 7×7 | 2×2 avg pool, stride=2 | ||||
| DenseBlock | 7×7 |
|
|
|
|
| Classification Layer | 1×1 | 7×7 global avg pool | |||
| 1000D fully-connected,softmax | |||||
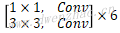
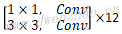
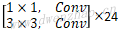
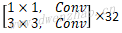
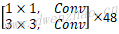
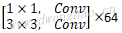
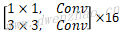
五、TensorFlow数据存取:
训练模型的第一步是读取数据。在卷积神经网络中,读取的数据主要是图片及其对应的标签信息;模型训练完成后,需要对模型进行存储;模型训练如果被中断,则需要对训练过程中存储的模型重新加载再训练。
1. 队列:
队列是常用的数据结构之一,TensorFlow在各个设置之间传递数据时使用了队列。
1)构建队列:
常见的队列有先来先服务队列FIFOQueue、优先级队列PriorityQueue、随机乱序队列Random ShuffleQueue等。
①FIFOQueue:
先来先服务是最简单的队列,按照先来后到的顺序,先来的优先出队,后到的排在队尾。
TensorFlow中,tf.FIFOQueue对象用来管理FIFOQueue数据结构,构造函数:
__init__(
capacity,
dtypes,
shape=None,
names=None,
shared_name=None,
name='fifo_queue'
)
tf.FIFOQueue对象管理着capacity个元素,每个元素是固定长度的Tensor对象元组,且元组中的Tensor对象的数据类型在dtypes参数中定义,shape在shapes参数中定义。如果指定了shapes参数,那么队列的每个元组中的Tensor对象必须与shapes中指定的shape一致;如果没有指定shapes参数,那么队列的各个元素中Tensor的shape允许不一致,但是不允许执行dequeue_name函数。构造函数中各个参数的含义及类型:
· capacity:整数类型,指定队列的容量,即最大能存储的元素个数。
· dtypes:列表类型,指定队列元素(存储的是元组)中每个Tensor的数据类型。
· shapes:列表类型,指定队列元素(存储的是元组)中每个Tensor的shape,
· names:;列表类型,指定队列元素(存储的是元组)中每个Tensor的名称,如果指定了该参数,那么队列返回的是字典对象,names对应字典的keys。
· shared_name:字符串类型,如果指定了shared_name,那么通过shared_name可以在各个Session之间共享队列。
· name:字符串类型,当前队列Operation对象的名称。
FIFOQueue对象的入队函数为enqueue,出队函数为dequeue,示例FIFOQueue队列的使用:
import tensorflow as tf
import numpy as np
#初始化数据
def init_data():
data_list=[]
for i in range(10):
float_data=[i,i,i]
str_data=['str_'+str(i),'str'+str(i))
data_list.append((float_data,str_data))
return data_list
#构建图
def build_queue():
queue=tf.FIFOQueue(capacity=10,dtypes=[tf.float32,tf.string],shapes=[(3,),(2,)])
return queue
#主函数
def main():
# 创建队列
queue=build_queue()
#获取样例数据
data_list=init_data()
#定义Placeholder
fp_data_tf=tf.placeholder(shape=(3,),dtype=tf.float32)
str_data_tf=tf.placeholder(shape=(2,),dtype=tf.string)
#将placeholder中的数据入队
enqueue_op=queue.enqueue((fp_data_tf,str_data_tf)
#将队列中的数据出队
dequeue_data=queue.dequeue()
with tf.Session() as sess:
#以循环方式,按顺序将数据出队
for fp_data,str_data in data_list:
sess.run(enqueue_op,feed_dict={fp_data_tf:fp_data
#执行出队操作,将队列中数据取出
for i in range(10):
print(sess.run(dequeue_date))
if __name__=='__name__':
main()
代码中,先创建FIFOQueue队列,并指定队列容量为10,队列中存储的元组中有两个Tensor对象,并且数据类型分别为tf.float32和tf.string,其shape分别为(3,)和(2,);后面代码构建测试样例数据,然后定义Placeholder,用于作为图的输入;然后将Placeholder中的数据加入队列,并从队列中取出数据;最后将生成的样例数据插入队列中,取出队列中的数据并打印显示。显示结果:
[array([0., 0., 0.],dtype=float32), array([b''str_0',b'str0'],dtype=object)]
从0到9,共10行输出。可以看出,从队列取出数据按照先进先出的顺序出列。
②PriorityQueue:
在TensorFlow中,优先级队列通过对象tf.PriorityQueue来管理,其构造函数:
__init__(
capacity,
types,
shape=None,
names=None,
shared_name=None,
name='priority_queue'
)
构造函数的参数与FIFOQueue构造函数的含义及参数类型类型,但tf.PriorityQueue执行入队操作时必须将元组的第一个位置的值作为优先级,入队Tensor从元组的第二个位置开始存储。示例:
import tensorflow as tf
import numpy as np
#初始化数据
def init_data():
data_list=[]
for i in range(10):
priority=10-i
float_data=[i,i,i]
str_data=['str_'+str(i),'str'+str(i))
data_list.append((priority,float_data,str_data))
return data_list
#构建图
def build_queue():
queue=tf.PriorityQueue(capacity=10,types=[tf.float32,tf.string],shapes=[(3,),(2,)])
return queue
#主函数
def main():
# 创建队列
queue=build_queue()
#获取样例数据
data_list=init_data()
#定义Placeholder
priority_tf=tf.placeholder(shape=(),dtype=tf.int64)
fp_data_tf=tf.placeholder(shape=(3,),dtype=tf.float32)
str_data_tf=tf.placeholder(shape=(2,),dtype=tf.string)
#将placeholder中的数据入队
enqueue_op=queue.enqueue((priority_tf,fp_data_tf,str_data_tf)
#将队列中的数据出队
dequeue_data=queue.dequeue()
with tf.Session() as sess:
#以循环方式,按顺序将数据出队
for priority,fp_data,str_data in data_list:
sess.run(enqueue_op,feed_dict={priority_tf,:prioroty
#执行出队操作,将队列中数据取出
for i in range(10):
print(sess.run(dequeue_date))
if __name__=='__name__':
main()
显示结果:
[1,array([9., 9., 9.],dtype=float32), array([b''str_9',b'str9'],dtype=object)]
从9到0,共10行输出。可以看出,优先级数值越小,表示优先级越高。
③RandomShuffleQueue:
在TensorFlow中,通过对象tf.RandomShuffleQueue来管理随机队列,队列中的元素随机打乱,再随机返回队列中的元素。其构造函数:
__init__(
capacity,
min_after_dequeue,
dtypes,
shape=None,
names=None,
seed=None,
shared_name=None,
name='random_shuffle_queue'
;)
其中大部分参数含义及数据类型与FIFOQueue类似,但有另外两个参数:
· min_after_dequeue:整数类型,指定队列中至少保留的元素个数。
· seed:整数类型,随机数种子,用于生成随机数。
对象tf.RandomShuffleQueue同样使用enqueue函数实现入队,通过dequeue函数实现出队,但如果队列中元素个数小于等于min_after_dequeue时,出队会处于阻塞状态,直到有新的元素入队使得队列中元素个数大于min
import tensorflow as tf
import numpy as np
#初始化数据
def init_data():
data_list=[]
for i in range(10):
float_data=[i,i,i]
str_data=['str_'+str(i),'str'+str(i))
data_list.append((float_data,str_data))
return data_list
#构建图
def build_queue():
queue=tf.RandomShuffleQueue(capacity=10,min_after_dequeue=5,dtypes=[tf.float32,tf.string],shapes=[(3,),(2,)])
return queue
#主函数
def main():
# 创建队列
queue=build_queue()
#获取样例数据
data_list=init_data()
#定义Placeholder
fp_data_tf=tf.placeholder(shape=(3,),dtype=tf.float32)
str_data_tf=tf.placeholder(shape=(2,),dtype=tf.string)
#将placeholder中的数据入队
enqueue_op=queue.enqueue((fp_data_tf,str_data_tf)
#将队列中的数据出队
dequeue_data=queue.dequeue()
with tf.Session() as sess:
#以循环方式,按顺序将数据出队
for fp_data,str_data in data_list:
sess.run(enqueue_op,feed_dict={fp_data_tf:fp_data,str_data_tf:str_data})
#执行出队操作,将队列中数据取出
for i in range(10):
print(sess.run(dequeue_date))
if __name__=='__name__':
main()
虽然代码中for循环次数为10,实际出队元素只有5个,因为设定了min_after_dequeue=5,经5次出队后会处于阻塞状态,直到有新的元素加入队列。tf.RandomShuffleQueue取出元素是乱序的,因此输出会每次不一样。
2)Queue、QueueRunner及Coordinator:
实际上使用队列更多情况下是为了将队列作为缓冲机制,使用两个线程分别做入队和出队操作。TensorFlow提供了多线程队列存储机制,主要涉及Queue、QueueRunner及Coordinator三个概念。Queue是队列,已经介绍;QueueRunner是TensorFlow对操作Queue线程的封装;Coordinator用于管理线程,如管理线程同步等操作。
①使用QueueRunner实现异步入队出队:
在TensorFlow中使用tf.train.QueueRunner实现对线程的封装,QueueRunner维护着一个Operation列表,用于实现队列相关操作。Operation列表中包含多个入队Operation对象,每一个入队Operation对象在一个单独的线程中执行。tf.train.QueueRunner对象构造函数:
__init__(
queue=None,
enqueue_ops=None,
close_op=None,
cancel_op=None,
queue_closed_exception_types=None,
queue_runner_def=None,
import_scope=None
)
对象tf.train.QueueRunner的构造函数常用的参数为queue和enqueue_ops,参数含义及类型:
· queue:需要操作的队列对象。
· enqueue_ops:列表类型,存放的是在线程中执行入队的Operation。
QueueRunner对象的create_threads函数自动为enqueue_ops中的每个入队Operation创建线程。示例代码:
import tensorflow as tf
#创建队列,队列的元素为一个对象(没有用元组)
queue=tf.FIFOQueue(10,dtypes=tf.float32)
#计数器
counter=tf.Variable(0.0,dtype=tf.float32)
#给计数器加1
increment_op=tf.assign_add(counter,1.0)
#将计数器加入队列
enqueue_op=queue.enqueue(counter)
#创建QueueRunner
#用多个线程向队列添加数据
runner=tf.train.QueueRunner(queue,enqueue_ops=[increment_op,enqueue_op])
#主线程中运行的代码
sess=tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
#启动入队线程
runner.create_threads(sess.start=True)
for i in range(10):
print(sess.run(queue,dequeue()))
代码中,先创建FIFOQueue,定义了入队Operation类型的对象enqueue_op;构建Queue Runner对象时,构造函数中指定enqueue_op为increment_op和enqueue_op,后面时QueueRunner对象会为这两个Operation对象分别创建一个线程并执行;后面为enqueue_ops列表中每个Operation对象单独创建线程,并开始启动线程执行。由于线程之间是异步的,因此每次执行的输出结果会不一致。执行increment_op的线程会一直不停地执行,执行enqueue
②配合Coordinator对象使用多线程:
Coordinator对象本身与队列无关,与TensorFlow框架也无关,可以单独与Python中的线程一起使用。Coordinator的典型使用场景为:
· 线程同步等待,使得所有线程都执行结束后,再继续往后执行。
· 请求其他线程停止循环执行任务。
· 使用Coordinator对象协调线程时,主要使用Coordinator对象的request_stop()函数、should _stop()函数及join函数。
⑴request_stop()函数:当线程集合中有任意一个线程调用request_stop()函数时,表示该线程要求所有线程停止运行。
⑵should_stop()函数:查询是否有其他线程调用了request_stop()。
⑶join(threads)函数:阻塞当前进程,直到threads中所有线程执行结束。
Coordinator配合Python中的线程使用示例:
import tensorflow as tf
import threading, time
#子线程函数
def loop(coord,id):
t=0
#查询是否有线程请求停止
while not coord.should_stop():
print('thread_id=',id)
time,sleep(1)
t+=1
#只有1号线程调用request_stop()方法
if (t>=2 and id==1):
# 1号线程发出请求,所有线程停止
coord.request_stop()
coord=tf.train.Coordination()
#创建5个线程,每个线程执行loop函数
threads=[threading.Thread(target=loop,args=(coord,i)) for i in range(5)]
#启动所有线程
for t in threads:
t.start()
#等待所有线程结束
coord.join(threads)
代码中创建了5个线程,每个线程执行loop函数。在loop函数中,线程首先查询当前是否有其他线程请求停止执行任务,如果有则跳出循环,1号线程循环2次后发出停止执行任务命令,所有线程查询到指令后跳出循环。
在前面的FIFOQueue示例中,increment_op线程会一直执行而不会停,如果Session强行关闭会出现线程继续往被关闭的队列中执行入队操作而抛出异常。用Coordinator配合Queue Runner来处理的示例:
import tensorflow as tf
#创建队列,队列的元素为一个对象(没有用元组)
queue=tf.FIFOQueue(10,dtypes=tf.float32)
#计数器
counter=tf.Variable(0.0,dtype=tf.float32)
#给计数器加1
increment_op=tf.assign_add(counter,1.0)
#将计数器加入队列
enqueue_op=queue.enqueue(counter)
#创建QueueRunner
#用多个线程向队列添加数据
runner=tf.train.QueueRunner(queue,enqueue_ops=[increment_op,enqueue_op]*2)
#主线程中运行的代码
with tf.Session() as sess:
coord=tf.train.Coordinator()
sess.run(tf.global_variables_initializer())
#启动入队线程
threads=runner.create_threads(sess,coord=coord,start=True)
for i in range(10):
print(sess.run(queue,dequeue()))
coord.request_stop()
coord,join(threads)
print('finished!')
代码中创建了4个线程,其中两个线程执行加1,另外两个线程执行入队操作。创建Coordinator,将coord传入QueueRunner对象,用于验证线程是否需要中止,无须显式调用should_stop()函数判断是否跳出循环。
3)队列中批量读取数据:
实际训练神经网络模型时,每一次传入网络的数据不会是单一数据,而是一批一批地传入,即按Batch传入。TensorFlow框架定义网络时,网络中的Feature Map的数据存储格式为[batch,height,width,channel]或[batch
在TensorFlow中,提供tf.train.batch、tf.train.batch_join、tf.train.shuffle_batch、tf.train.shuffle_batch_join等函数用于批量读取数据,这些函数内部维护着Queue和QueueRunner对象来管理数据读取。tf.train.batch函数的原型:
tf.train.batch(
tensors,
batch_size,
num_threads=1,
capacity=32,
enqueue_many=False,
shapes=None,
dynamic_pad=False,
allow_smaller_final_batch=False,
shared_name=None,
name=None
)
各个参数的含义及数据类型:
· tensors:列表类型或字典类型,存放的是需要批量读取的Tensor对象。
· batch_size:整数类型,从队列中批量读取Tensor的数量。
· num_threads:整数类型,执行出队操作的线程数量,如果大于1,那么Batch的数量将会是不确定大小。
· capacity:整数类型,表示队列中最大元素个数。
· enqueue_many:bool类型,如果为True,则Tensor本身保存的是一个批量数据,且第1个维度表示样本索引;如果为False,则表示Tensor是单个样本数据。
· shapes:各个样本的shape,作为Tensor的默认shape。
· dynamic_pad:bool类型,表示是否允许Tensor对象的shape是可变的。如果为True,则每个Tensor对象的shape允许有动态大小,即shape中允许None。在出队时,输出的批量Tensor对象取当前一批数据中shape的各个维度中最大的维度,小于最大维度的Tensor会在右端填充数据。对于数值类型,填充0;对于字符串类型,填充空串。如果dynamic_pad设为False,那么必须满足所有Tensor对象shape一致的条件,或者设置shapes参数。
· allow_smaller_final_batch:bool类型,如果设为True,则表示当队列关闭时,返回比指定的batch_size要小的批量数据。
· shared_name:字符串数据,如果设置了该参数,那么在不同的Session环境中,可以通过该参数共享队列。
· name:字符串类型,表示当前Operation对象的名称。
tf.train.batch内部维护着Queue和QueueRunner对象,并且会将QueueRunner对象加入当前环境中的图的QUEUE
tf.train.batch_join功能类似,也是从队列中读取数据直到达到batch_size个后返回,不同的是在执行入队操作时,tf.train.batch_join函数会使用多个队列读取Tensor对象,并加入队列中。函数原型:
tf.train.batch_join(
tensors_list,
batch_size,
capacity=32,
enqueue_many=False,
shapes=None,
dynamic_pad=False,
allow_smaller_final_batch=False,
shared_name=None,
name=None
)
其中大部分参数与tf.train.batch参数含义一致,还有两个参数需要注意:
· tensors_list:元组列表类型或字典类型,存放的是需要批量读取的Tensor对象。
· batch_size:整数类型,从队列中批量读取的Tensor的数量。
使用tf.train.batch和tf.train.batch_join从队列中读取数据时,并没有将队列中的数据打乱。TensorFlow还提供了tf.train.shuffle_batch、tf.train.shuffle _batch_join函数,用于从队列中随机乱序读取数据。tf.train.shuffle_batch函数原型:
tf.train.shuffle_batch(
tensors,
batch_size,
capacity,
min_after_dequeue,
num_threads=1,
seed=None,
enqueue_many=False,
shapes=None,
allow_smaller_final_batch=False,
shared_name=None,
name=None
)
其中大部分参数前面已经介绍过,min_after_dequeue表示元素出队后队列中至少应保留的元素个数。
tf.train.shuffle _batch_join函数也是从队列中随机乱序读取数据,但在执行入队操作时采用多线程读取多个列表,然后将列表作为一个元素加入队列。函数原型:
tf.train.shuffle_batch_join(
tensors_list,
batch_size,
capacity,
min_after_dequeue,
seed=None,
enqueue_many=False,
shapes=None,
allow_smaller_final_batch=False,
shared_name=None,
name=None
)
使用示例代码:
import tensorflow as tf
#构建队列作为数据集
def init_dataset():
data_tf=tf.placeholder(shape=(),dtype=tf.int64)
queue=tf.FIFOQueue(100,shapes=(),dtypes=tf.int64)
enqueue_op=queue.enqueue(data_tf)
return data_tf,enqueue_op,queue
#为指定的队列加入数据
def init_data_source(sess,op,input)
for i in range(100):
sess.run([op],feed_dict={input:i})
#创建4个数据集
input1,op1,queue1=init_dataset()
input2,op2,queue2=init_dataset()
input3,op3,queue3=init_dataset()
input4,op4,queue4=init_dataset()
#从4个数据集取数据op
data_tf_1=queue1.dequeue()
data_tf_2=queue2.dequeue()
data_tf_3=queue3.dequeue()
data_tf_4=queue4.dequeue()
#按Batch读取数据
batch_tf=tf.train.batch([data_tf_1],batch_size=2,capacity=10)
batch_join_tf=tf.train.batch_join([data_tf_2],batch_size=2,capacity=10)
shuffle_batch_tf=tf.train.shuffle_batch([data_tf_3],batch_size=2,capacity=10,min_after_dequeue=5)
shuffle_batch_join_tf=tf.train.shuffle_batch_join([data_tf_4],batch_size=2,capacity=10,min_after_dequeue=5)
with tf.Session() as sess:
#为数据集加入初始数据
init_data_source(sess,op1,input1)
init_data_source(sess,op2,input2)
init_data_source(sess,op3,input3)
init_data_source(sess,op4,input4)
coord=tf.train.Coordinator()
threads=tf.train.start_queue_runners(coord=coord)
#4种方式循环批量读取数据
print('batch:')
for i in range(10):
batch=sess.run(batch_tf)
print('\t',batch)
print('batch_join:')
for i in range(10):
batch_join=sess.run(batch_join_tf)
print('\t',batch_join)
print('shuffle_batch:')
for i in range(10):
shuffle_batch=sess.run(shuffle_batch_tf)
print('\t',shuffle_batch)
print('shuffle_batch_join:')
for i in range(10):
shuffle_batch_join=sess.run(shuffle_batch_join_tf)
print('\t',shuffle_batch_join)
coord.request_stop()
coord.join(threads)
上面4个函数内部维护着Queue和QueueRunner对象,并且将QueueRunner对象加入当前环境的图的QUEUE
2. 文件存取:
介绍的TensorFlow中的文件存储方法主要针对单个文件,如文本类型文件、字节类型文件及图片类型文件。
1)读取文本文件:
在TensorFlow中,函数tf.read_file用于读取读取文件,并返回字符串类型(或者说是字节数组类型)的Tensor对象。另外,TensorFlow还提供了对象tf.TextLineReader用于按行读取文本。
①tf.read_file:
函数tf.read_file可以将整个文本文件读取,并返回tf.string对象。函数原型:
tf.read_file(
filename,
name+None
)
其中,filename为文本文件的路径,name为文件读取Operation对象的名称。示例:
import tensorflow as tf
str_tf=tf.read_file('test_file.txt')
with tf.Session() as sess:
str=sess.run(str_tf)
print(str.decode())
②tf.TextLineReader:
实际训练卷积神经网络模型时,往往是将图片及其对应的标注信息按行存放在文本文件中,因此需要按行读取文本文件。tf.TextLineReader对象就是按行解析,其构造函数:
__init__(
skip_header_lines=None,
name=None
)
其中,参数skip_header_lines用于指定跳过起始的行数,name用于指定Operation对象的名称。构造tf
read(
queue,
name=None
)
其中,参数queue为队列对象,队列中存放的是文件名称。示例:
import tensorflow as tf
#创建文件名称队列,返回队列对象,并自动创建QueueRunner
#test_file.txt内容有两行:1,2,3和4,5,6
filename_queue=tf.train.string_input_producer(['text_file.txt'])
reader=tf.TextLineReader()
#read函数将Queue输入
_,value=reader.read(filename_queue)
#value为文件的某一行,接下来解析
value_arr=tf.string_split([value],',')
value_arr=tf.string_to_number(value_arr.values,out_type=tf.int64)
with tf.Session() as sess:
coord=tf.train.Coordinator()
#地带·启动计算图中所有的队列线程
threads=tf.train.start_queue_runner(coord=coord)
for i in range(4):
features=sess.run(value_arr)
print(features)
#主线程计算完成,停止所有采集数据的进程
coord.request_stop()
coord.join(threads)
代码中先创建filename_queue文件名队列时内部会创建QueueRunner对象,并将QueueRunner对象加入当前环境的图的QUEUE_RUNNER集合容器中;接着从文件名队列中取出文件名,并按行读取内容,继而将字符串按“,”分割成稀疏矩阵,并将稀疏矩阵中的values转为tf.int64数据类型;后面启动了当前环境的图的QUEUE_RUNNER集合容器中所有的QueueRunner线程,读取4次数据并打印。
2)读取定长字节文件:
实际项目中,为了存储和管理,有时需要将所有数据集放入一个二进制文件中。TensorFlow框架提供了对象tf
__init__(
record_bytes,
header_bytes=None,
footer_bytes=None,
hop_bytes=None,
name=None,
encoding=None
)
构造函数中各个参数含义及数据类型:
· record_bytes:整数类型,用于指定每一项数据占用的字节长度。
· header_bytes:整数类型,默认为0,用于指定文件头占的字节长度。
· footer_bytes:整数类型,默认为0,用于指定文件尾占的字节长度。
· hop_bytes:整数类型,默认为0,用于指定每一项数据之间间隔的字节数。
· name:字符串类型,用于指定当前Operation对象的名称。
· encoding:指定文件编码格式。
示例代码中实现DatasetWriter和DatasetReader类用于实现二进制文件的写和读,其中使用两张图片为数据集,其Label数据分别为[0,1]和[1,0]。
import struct
import cv2
class DatasetWriter:
def __init__(self,dst_file):
self.dst_file=dst_file
def write(self,dataset):
imgs,labels=dataset
with open(self.dst_file,'wb+') as f:
for img,label in zip(imgs,labels)"
#读取文件
im=cv2.imread(img)
#将图片中每个像素写入文件中
for x in range(im.shape[0]):
for y in range(im.shape[1]):
f.write(struct.pack('b',im[x,y,0]))
f.write(struct.pack('b',im[x,y,1]))
f.write(struct.pack('b',im[x,y,2]))
#将Label写入二进制文件
f.write(struct.pack('f',label[0]))
f.write(struct.pack('f',label[1]))
def get_dataset():
imgs=['datasets/imgs/01.jpg','datasets/imgs/02.jpg']
labels=[[0,1],[1,0]]
return (imgs,labels)
def main()
dataset=get_dataset()
writer=DatasetWriter(dst_file='datasets/6_2_2_dataset.bin')
writer.write(dataset)
if __name__=='__main__':
main()
代码中先定义了DatasetWriter,其中包括将数据集写入二进制文件中,使用了OpenCV读取图片文件,并将图片中的每个像素值利用struct库转为字节类型后写入;后面还将浮点类型Label数据通过struct库转为字节类型后写入字节文件中。后面的get_dataset()模拟读取数据集,在实际项目中根据实际数据集来具体实现该函数。主程序中,演示如何通过DatasetWriter对象,执行完成后会在dataset目录中生成6_2_2_dataset.bin文件。DatasetReader代码为:
import tensorflow as tf
import cv2
class DatasetReader:
def __init__(self,bin_file):
self.bin_file=bin_file
def get(self):
#计算每一项数据所占的字节长度
record_bytes=256*256*3 # 图片所占字节长度
record_bytes=record_bytes+4*2 # Label所占字节长度
#生成数据读取对象
reader=tf.FixedLengthRecordReader(header_bytes=0,record_bytes=record_bytes)
#读取数据
_,value=reader.read(tf.train.string_input_producer([self.bin_file]))
#从读取的数据中解析图片
record_bytes_uint8=tf.decode_raw(value,tf.uint8)
image=tf.reshape(tf.slice(record_bytes_uint8,[0],[256*256*3]),[256,256,3]))
#从读取的数据中解析Label
record_bytes_float32=tf.decode_raw(value,tf.float32)
label=tf.slice(record_bytes_float32,[256*256*3//4]),[2])
return image,label
def main():
reader=DatasetReader(bin_file='datasets/6_6_2_dataset.bin')
img_tf,label_tf=reader.get()
with tf.Session() as sess:
coord=tf.train.Coordinator()
#启动计算图中所有的队列线程
threads=tf.train.start_queue_runner(coord=coord)
for i in range(2):
img,label=sess.run([img_tf,label_tf])
cv2.imwrite('datasets/outputs/%d_%d%d.jpg'%(i,int(label[0]),int(label[1])),img)
coord.request_stop()
coord.join(threads)
if __name__=='__main__':
main()
代码中,定义了DatasetReader对象,用于从二进制文件中读取图片和对应的Label数据,图片宽高256×256,且通道数3,因此占用256×256×3个字节;由于Lable为两个浮点数,因此占用4×2字节;下面则用于解析tf.uint8数据类型的图片和tf.float32数据类型的Label。主函数中演示DatasetReader对象的使用,执行代码后,在datasets
3)读取图片:
读取图片时需要针对不同格式的图片使用不同的编码方式解析图片。TensorFlow提供了tf.image.decode_bmp函数解析BMP格式图片,tf.image.decode_gif函数解析GIF格式图片,tf.image.decode_jpeg函数解析JPEG格式图片,tf.image.decode_png函数解析PNG格式图片。
为了便于使用,TensorFlow提供了tf.image.decode_image函数自动检测图片格式并返回解析后的Tensor对象。函数原型分别为:
tf.image.decode_image(
contents,
channels=None,
dtype=tf.uint8,
name=None
)
tf.image.decode_png(
contents,
channels=0,
dtype=tf.uint8,
name=None
)
tf.image.decode_jpeg(
contents,
channels=0,
ratio=1,
fancy_upscaling=True,
try_recover_truncated=False,
acceptable_fraction=1,
dct_method='',
name=None
)
tf.image.decode_gif(
contents,
name=None
)
tf.image.decode_bmp(
contents,
channels=0,
name=None
)
各个函数的参数含义及数据类型为:
· contents:0维且数据类型为字符串的Tensor对象。
· channels:整数类型,默认为0,表示解析的图片通道数量。
· dtype:Dtype类型,指定返回Tensor对象的数据类型。
· name:字符串类型,表示当前Operation对象的名称。
· ratio:整数类型,默认1,表示缩小比例。
· fancy_upscaling:bool类型,默认True。如果为True,则使用较慢但效果更好的放大算法。
· try_recover_truncated:bool类型,默认False。如果为True,则尝试从被截断的输入中恢复图片。
· acceptable_fraction:float类型,默认1,指定被裁剪输入的最小行数。
· dct_method:字符串类型,默认’’。指定解压算法,当前只能取INTEGER_FAST或INTEGER _ACCURATE。
使用前面的数据集通过TensorFlow读取并解析指定目录中所有图片的示例:
import tensorflow as tf
import cv2
import os
def main()
files=['datasets/imgs/'+f for f in os.listdir('datasets/imgs')]
imgs_list_tf=tf.convert_to_tensor(files,dtype=tf.string)
[img_path_tf]=tf.train.slice_input_producer([imgs_list_tf])
img_data_tf=tf.read_file(img_path_tf)
img_tf=tf.image.decode_jpeg(img_data_tf,channels=3)
with tf.Session() as sess:
coord=tf.train.Coordinator()
threads=tf.train.start_queue_runners(coord=coord)
for i in range(2):
img=sess.run(img_tf)
cv2.imwrite('datasets/decode_imgs/%d.jpg'%i,img)
coord.request.stop()
coord.join(threads)
if __name__=='__main__':
main()
代码中先获取设定目录下所有图片的路径,将列表类型对象转为Tensor对象,然后从一维Tensor读取数据,其内部通过维护一个队列及其对应的QueueRunner对象返回队列中的元素。接着从字符串类型的Tensor对象中读取图片文件,对JPEG格式图片进行解析,循环执行两次取数据和保存数据操作。执行完成后,会在指定目录中得到两张图片,与原目录中的图片一致。
使用tf.image.decode_image函数可以避免因图片编码格式与解析格式不一致带来的异常。如果输入是GIF格式,那么tf.image.decode_image返回的Tensor的shape为[num_fames,height, width],而BMP、JPEG、PNG格式返回的shape则是[height,width,num_channels]。
3. 从CSV文件中读取训练集:
CSV即Comma-Separated Values,也称为字符分隔值,以纯文本的方式存储数据。实际项目中,用CSV文件保存图片路径及其对应的Label数据。
1)解析CSV格式文件:
在TensorFlow中,函数tf.decode_csv用于解析CSV格式的数据,其中CSV文件的每一列对应一个Tensor对象。函数原型:
tf.decode_csv(
records,
record_defaults,
field_delim=',',
use_quote_delim=True,
name=None,
na_value='',
select_cols=None
)
各个参数的含义及数据类型:
· records:数据类型为字符串的Tensor对象。每个字符串表示一条记录,并且所有的字符串的格式相同。
· record_defaults:list类型,存放的是Tensor对象。每个Tensor对象的数据类型与对应的列的数据类型一致,作为每一列的默认值。
· field_delim:字符串类型,默认为英文逗号“,”。指定每行数据中的分隔符,每一列数据通过field_delim间隔。
· use_quote_delim:bool类型,默认True。如果为False,则将字符串中的双引号作为普通字符。
· name:字符串类型,指定当前Operation对象的名称。
· na_value:字符串类型,作为NA/NaN对待。
· select_cols:list类型,指定返回的列。
首先创建csv文件csv_data.csv,内容:
imgs/01.jpg,1,3,5
imgs/02.jpg,2,4,6
使用tf.decode_csv函数解析csv_data.csv的示例:
import tensorflow as tf
def main()
# 构建文件名路径队列
filename_queue=tf.train.string_input_producer(["datasets/csv_data.csv"])
reader=tf.TextLineReader()
#从文件路径队列中取出文件路径,并取出文件的每一行
_,value=reader.read(filename_queue)
#设置每一行的默认值
record_defaults=[[''],[0],[0],[0]]
#解析CSV文件的每一行
img_path_tf,col1_tf,col2_tf,col3_tf=tf.decode_csv(value,record_defaults)
with tf.Session() as sess:
coord=tf.train.Coordinator()
#启动所有队列进程
threads=tf.train.start_queue_runners(coord=coord)
for i in range(2):
img_path,col1,col2,col3=sess.run([img_path_tf,col1_tf,col2_tf,col3_tf])
print(img_path.decode(),col1,col2,col3)
coord.request.stop()
coord.join(threads)
if __name__=='__main__':
main()
代码中先构建文件路径队列,然后从队列中提取文件路径,读取文件后把文件每一行加入队列并从队列中读取每一行数据;继而设置CSV文件的每一列默认值,注意每一列必须与对应的数据类型一致,然后解析CSV文件中一行。启动所有队列中的线程,使得数据源源不断地入队出队,使用循环执行两次从图中提取数据的操作,并将读取的数据打印输出。代码执行后输出:
imgs/01.jpg 1 3 5
imgs/02.jpg 2 4 6
2)封装CSV文件读取类:
实际项目中,大部分情况下需要随机批量处理读取数据,可以把批量随机读取数据封装为类CSVDataReader。
import tensorflow as tf
class CSVDataReader:
def __init__(self,csv_path,batch_size):
self.batch_size=batch_size
#构建文件名路径队列
self.file_path_queue=tf.train.string_input_producer([csv_patch])
def get(self):
reader=tf.TextLineReader()
#从文件路径队列中取出文件路径,并取出文件的每一行
_,value=reader.read(self.file_path_queue)
#设置每一行的默认值
record_defaults=[[''],[0],[0],[0]]
#解析CSV文件的一行
img_path_tf,col1_tf,col2_tf,col3_tf=tf.decode_csv(value,record_defaults)
tensors=[[img_path_tf,col1_tf,col2_tf,col3_tf]]
img_path_batch,col1_batch,col2_batch,col3_batch=tf.train.shuffle_batch_join
return img_path_batch,col1_batch,col2_batch,col3_batch
def main():
#从datasets/csv_data.csv文件中读取数据,设置Batchsize为6
dataReader=CSVDataReader('datasets/csv_data.csv',6)
img_path_batch,col1_batch,col2_batch,col3_batch=dataReader.get()
with tf.Session() as sess:
coord=tf.train.Coordinator()
#启动所有队列进程,使得每个队列源源不断执行入队和出队操作
threads=tf.train.start_queue_runners(coord=coord)
img_path,col1,col2,col3=sess.run([img_path_tf,col1_batch,col2_batch,col3_batch])
for img_path_v,col1_v,col2_v,col3_v in zip(img_path,col1,col2,col3):
print( img_path_v.decode(),col1_v,col2_v,col3_v)
coord.request.stop()
coord.join(threads)
if __name__=='__main__':
main()
代码中对CSV文件行读取并解析一行数据,使用随机乱序方式批量读取随机,从图中取出批量数据并打印。
4. 从自定义文本格式文件中读取训练集:
使用CSV格式文件存储训练集已经能满足大部分需求,但使用自定义文件格式文件方式更直观灵活。
1)解析自定义文本格式文件:
首先需要自定义每一项记录的存储格式,以及各项记录之间的间隔符。一般使用换行符作为各项记录之间的间隔符,即每一项记录占一行;每一项记录中的每个属性可以采用逗号、空格、分号等符号间隔。这里使用空格间隔图片路径和对应记录,使用逗号间隔标记各个属性。
在datasets目录中创建文件custom_txt_data.txt,内容:
imgs/01.jpg 1,3,5
imgs/02.jpg 2,4,6
解析思路,首先按行读取每一行,对于每一行按空格将图片路径和标记分开,使用字符“,”将标记属性分割成数组,对应于稀疏矩阵,然后对于数组的每个数据强制数据转换。示例:
import tensorflow as tf
def main()
# 构建文件名路径队列
filename_queue=tf.train.string_input_producer(["datasets/custom_txt_data.txt"])
reader=tf.TextLineReader()
#从文件路径队列中取出文件路径,并取出文件的每一行
_,line_tf=reader.read(filename_queue)
#按空格分割图片路径及其对应Label
kvs_tf=tf.string_split([line_tf],delimiter=' ')
img_path_tf=kvs_tf.values[0]
label_str_tf=kvs_tf.values[1]
#解析Label,按逗号分隔Label,得到稀疏矩阵
label_str_arr_tf=tf.string_split([label_str_tf],delimiter=',')
#将稀疏矩阵Label中的每个value强制转换类型,得到Tensor对象
label_int_arr_tf=tf.string_to_number(label_str_arr_tf.values,out_type=tf.int64)
with tf.Session() as sess:
coord=tf.train.Coordinator()
#启动所有队列进程,使得每个队列源源不断地执行入队和出队操作
threads=tf.train.start_queue_runners(coord=coord)
for i in range(2):
img_path,label_int_arr=sess.run([img_path_tf,col1_tf,label_int_arr_tf])
print(img_path.decode(),label_int_arr)
coord.request.stop()
coord.join(threads)
if __name__=='__main__':
main()
代码中,第一步按照惯例构建文件路径队列并按行读取文件,然后按空格将文件路径及其Label分割为长度为2的稀疏矩阵,稀疏矩阵的values属性即为矩阵的值,接着将Label按逗号分割成稀疏矩阵,并取出稀疏矩阵中的values转为整数类型。
2)封装自定义文本格式文件读取类:
封装一个批量数据读取类MyDataReader,按照乱序方式批量读取数据,示例代码:
import tensorflow as tf
class MyDataReader:
def __init__(self,csv_path,batch_size):
self.batch_size=batch_size
#构建文件名路径队列
self.file_path_queue=tf.train.string_input_producer([csv_patch])
def get(self):
reader=tf.TextLineReader()
#从文件路径队列中取出文件路径,并取出文件的每一行
_,line_tf=reader.read(self.file_path_queue)
#按空格分割图片路径及其对应Label
kvs_tf=tf.string_split([line_tf],delimiter=' ')
img_path_tf=kvs_tf.values[0]
label_str_tf=kvs_tf.values[1]
#解析Label,按逗号分隔Label,得到稀疏矩阵
label_str_arr_tf=tf.string_split([label_str_tf],delimiter=',')
#将稀疏矩阵Label中的每个value强制转换类型,得到Tensor对象
label_int_arr_tf=tf.string_to_number(label_str_arr_tf.values,out_type=tf.int64)
#按Batch读取时需要先设置shape
label_int_arr_tf.set_shape((3,))
tensors=[[img_path_tf,label_int_arr_tf]]
img_path_batch,label_int_arr_batch=tf.train.shuffle_batch_join(tensors,batch_size
return img_path_batch,label_int_arr_batch
def main():
#从custom_txt_data.txt文件中读取数据,设置Batchsize为6
dataReader=MyDataReader('datasets/custom_txt_data.txt',6)
img_path_batch,label_int_arr_batch=dataReader.get()
with tf.Session() as sess:
coord=tf.train.Coordinator()
#启动所有队列进程,使得每个队列源源不断执行入队和出队操作
threads=tf.train.start_queue_runners(coord=coord)
img_path,label_int_arr=sess.run([img_path_tf,col1_batch,label_int_arr_batch])
for img_path_v,label_int_arr_v in zip(img_path,label_int_arr):
print( img_path_v.decode(),label_int_arr_v)
coord.request.stop()
coord.join(threads)
if __name__=='__main__':
main()
代码中构建了MyDataReader类,其中构造函数创建了文件路径队列,以随机乱序方式并以Batch为6批量读取数据,然后对自定义格式字符串进行解析。
5. TFRecord方式存取数据:
TensorFlow中,提供了TFRecord存储数据集,可以存储任意大小的数据集。
1)将数据写入TFRecord文件:
使用TFRecord文件的第一步是将数据写入TFRecord文件中,TensorFlow框架使用类tf.python_io.TFRecordWriter将数据写入TFRecord文件。示例代码:
import tensorflow as tf
import cv2
class TFRecordWriter:
def __init__(self,tfrecord_path,labels_list):
self.labels_list=labels_list
self.tfrecord_path=tfrecord_path
def write(self):
writer=tf.python_io.TFRecordWriter(self.tfrecord_path) #要生成的文件
for item in self.labels_list: #对Label遍历
img_path=item[0]
label=item[1]
img=cv2.imread(img_path)
img=cv2.resize(img,(256,256))
img_bytes=img.tostring()
example=tf.train.Example(features=tf.train.Features(feature={'label'
writer.write(example.SerializeToString())) #序列化为字符串并写入文件
writer.close()
def get_labels():
datasets=[]
datasets.append(["datasets/imgs/01.jpg",[0,1])
datasets.append(["datasets/imgs/02.jpg",[1,0])
return datasets
def main()
datasets=get_labels()
writer=TFRecordWriter('datasets/6_5_1_dataset.tfrecords',datasets)
writer.write()
if __name__=='__main__':
main()
代码中,构建TFRecordWriter类,构造函数用于保存Label和TFRecord文件存放路径,然后对Label遍历,将每一项数据写入TFRecord文件中。下面是生成数据集,实际项目中根据数据存放情况来编写此文件。主函数中开始执行文件写入,执行完成会在指定目录中生成tfrecord文件。
代码中定义了tf.train.Example对象,表示一项数据,其中feature参数表示一项数据中的公共属性,例如示例中的label和img属性,其中label属性数据类型为int64列表,img属性数据类型为字节类型的列表。属性通过类tf
2)从TFRecord文件中读取数据:
将所有数据集封装到一个TFRecord文件后,接下来解析TFRecord文件,并按照随机乱序方式批量读取数据集。在前面生成的TFRecord文件中,每一项数据包含label和img两个属性,因此接下来的TFRecord文件解析也必须按照生成文件时定义的属性关键字读取数据。示例:
import tensorflow as tf
import cv2
class TFRecordReader:
def __init__(self,tfrecord_path,batch_size):
self.batch_size=batch_size
self.tfrecord_path=tfrecord_path
def get(self):
#根据文件名生成一个队列
file_path_queue=tf.train.string_input_producer([self.tfrecord_path])
reader=tf.TFRecordReader()
_,serialized_example=reader.read(file_path_queue)
features=tf.parse_single_example(serialized_example
#读取Label
label=tf.cast(features['label'],tf.int64)
img=tf.decode_raw(features['img'],tf.uint8)
#将维度指定为256×256的3通道
img=tf.reshape(img,[256,256,3])
img_batch,label_batch=tf.train.shuffle_batch_join([[img,label]]
return img_batch,label_batch
def main():
#从指定路径中的指定tfrecord文件中读取数据,设置BatchSize=6
dataReader=TFRecordReader('datasets/6_5_1_dataset.tfrecords',6)
img_batch,label_batch=dataReader.get()
with tf.Session() as sess:
coord=tf.train.Coordinator()
#启动计算图中所有的队列线程
threads=tf.train.start_queue_runner(coord=coord)
imgs,labels=sess.run([img_batch,label_batch])
index=0
dst_dir='datasets/6_5_2_outputs'
for img,label in zip(imgs,labels):
dst_file=dst_dir+'/index(%d)_%d_%d.jpg'%(index,label[0],lable[1])
cv2.imwrite(dst_file,img)
cv2.imwrite(dst_file,img)
index=index+1
coord.request_stop()
coord.join(threads)
if __name__=='__main__':
main()
需要注意,按Batch读取数据时,每个数据必须有明确的shape值,因此代码中要指定图片的shape。
6. 模型存取:
在训练神经网络模型的过程中和训练完成之后,均需要存储模型数据。训练完成之后需要使用训练的模型,因此需要保存模型数据;而训练过程中保存网络模型主要是为了保证程序意外停止后还能加载原来训练的中间模型继续训练。
1)存储模型:
TensorFlow模型文件包括meta文件、data文件及index文件,其中meta文件存储的是图结构,data文件存放的是训练的参数数据,index文件存放的是Tensor对象的数据索引、校验值和其他辅助数据。TensorFlow使用tf
__init__(
var_list=None,
reshape=False,
sharded=False,
max_to_keep=5,
keep_checkpoint_every_n_hours=10000.0,
name=None,
restore_sequentially=False,
saver_def=None,
builder=None,
defer_build=False,
allow_empty=False,
write_version=tf.train.SaverDef.V2,
pad_step_number=False,
save_relative_paths=False,
filename=None
)
其中的参数比较多,常用的参数含义及数据类型:
· var_list:list类型或字典类型,存放的是变量Tensor对象,用于指定存储或者加载的Tensor对象。如果设置None,则表示所有的可存储的对象。
· reshape:bool类型,如果为True,则表示允许将模型文件中与变量shape不同的数据赋值给网络图中的变量。
· sharded:bool类型,如果为True,则表示在每个设备中共享模型文件。
· max_to_keep:整数类型,表示存储的最大模型数量,默认5个。也就是说,当存储的模型数量超过5个时,则会自动将最先存储的模型删除。
· keep_checkpoint_every_n_hours:浮点类型,表示每隔n小时自动存储一次模型。
· name:字符串类型,当添加Operation时,该参数会作为Operation对象名称前缀。
tf.train.Saver对象的save函数用于存储模型,restore函数用于从模型文件中加载参数数据。
save函数的原型:
save(
sess,
save_path,
global_step=None,
latest_filename=None,
meta_graph_suffix='meta',
write_meta_graph=True,
write_state=True,
strip_default_attrs=False
)
各个参数的含义及数据类型:
· sess:tf.Session对象,存储sess关联的图中的训练参数和图结构。
· save_path:字符串类型,指定存储模型的路径。
· global_step:整数类型,指定当前模型的step。
· latest_filename:字符串类型,指定checkpoint列表文件,默认checkpoint。
· meta_graph_suffix:字符串类型,表示图文件后缀,默认meta。
· write_meta_graph:bool类型,用于指定是否①保存文件。
· write_state:bool类型,用于指定是否存储CheckpointStateProto。
· strip_default_attrs:bool类型,如果设置为True,则有默认值的节点会被从模型文件中移除。
①存储所有参数:
TensorFlow框架中存储模型数据的示例:
import tensorflow as tf
def build_graph(alpha,beta):
v1=tf.Variable([[1,1,1],[2,2,2]],name='v1')
v2=tf.Variable([[3,3,3],[4,4,4]],name='v2')
output=tf.add(alpha*v1,beta*v2,name='add')
return output
def main():
output_tf=build_graph(3,5)
saver=tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variable_initializer())
step=0
saver.save(sess,'datasets/6_6_1_model/model',global_step=0)
if __name__=='__main__':
main()
代码中,创建了一个简单的网络结构图,即两个变量Tensor对象做线性加法运算;然后创建了tf.train.Saver对象,将所有变量初始化后,将模型数据存储。执行代码后,会在指定目录下创建如下文件:
checkpoint
model-0.data-00000-of-00001
model-0.index
model-0.meta
其中,checkpoint是一个文本文件,存放的是模型文件列表,可以使用文本编辑器打开查看;model-0.meta文件存放的是图结构,model-0.data-00000-of-00001文件存放的是训练参数,model-0.index文件存放的是索引数据。存储的模型文件名称后面所加的0表示当前模型的step,即反向传播训练次数。
②存储部分参数:
在默认情况下,tf.train.Saver存取的是当前关联图中的所有训练参数。当需要修改部分网络结构时,为了加快训练速度,需要从已训练的模型中只加载未发生变化的网络层参数。
在构造tf.train.Saver对象时,可以指定需要存储或加载的Tensor对象,示例:
import tensorflow as tf
def build_graph(alpha,beta):
v1=tf.Variable([[1,1,1],[2,2,2]],name='v1')
v2=tf.Variable([[3,3,3],[4,4,4]],name='v2')
output=tf.add(alpha*v1,beta*v2,name='add')
return output,v1,v2
def main():
output_tf,v1,v2=build_graph(3,5)
saver=tf.train.Saver(var_list=[v1])
with tf.Session() as sess:
sess.run(tf.global_variable_initializer())
step=0
saver.save(sess,'datasets/6_6_1_model/model',global_step=1)
if __name__=='__main__':
main()
代码中指定存储v1变量中的参数,代码执行后指定目录中创建如下文件:
model-1.data-00000-of-00001
model-1.index
model-1.meta
2)从checkpoint文件中加载模型:
模型参数数据存放在data文件中,index文件为Tensor对象的参数存放索引,meta文件存放的是图结构。因此,从checkpoint文件中只加载模型变量类型的Tensor参数时,只需要data文件和index文件。TensorFlow中,通过tf.train.Server对象的restore函数将模型数据中的参数赋值给网络中的Tensor对象,函数原型:
restore(
sess,
save_path
)
各个参数含义及数据类型:
· sess:tf.Session类型,用于关联当前图结构及图中的变量。
· save_path:字符串变量,用于指定模型文件路径。
通过tf.train.Server对象的restore函数将前面存储的参数加载到当前图中的示例:
import tensorflow as tf
def build_graph(alpha,beta):
v1=tf.Variable([[1,1,1],[2,2,2]],name='v1')
v2=tf.Variable([[3,3,3],[4,4,4]],name='v2')
output=tf.add(alpha*v1,beta*v2,name='add')
return output,v1,v2
def main():
output_tf,v1_tf,v2_tf=build_graph(3,5)
with tf.Session() as sess:
saver=tf.train.Saver()
saver.restore(sess,'datasets/6_6_1_model/model-0')
output,v1,v2=sess.run([output_tf,v1_tf,v2_tf])
print(3,'*',v1.tolist(),'+',5,'*',v2.tolist())
print('=',output.tolist())
if __name__=='__main__':
main()
代码中构建图,注意变量的名称需要与保存模型时图中的变量名一致;后面将模型文件中的参数加载到当前图中,最后将变量值从图中取出并将结果打印出来。代码执行后输出:
3*[[1.0,1.0,1.0],[[2.0,2.0,2.0]]+5*[[3.0,3.0,3.0],[[4.0,4.0,4.0]]
=[[18.0,18.0,18.0],[[26.0,26.0,26.0]]
实际项目中,常常是将最新的模型参数加载到图中,checkpoint文件中保存了存储的模型路径列表。TensorFlow提供函数tf.train.latest_checkpoint,可自动从checkpoints文件中读取最新的模型文件路径。因此如果希望从最新模型文件中加载数据,可以将上面的restore行替换为下面两行代码:
latest_model=tf.train.latest_checkpoint('datasets/6_6_1_model')
saver.restore(sess,latest_model)
3)从meta文件中加载模型:
可以不定义网络结构图,而是直接从meta文件中还原网络结构图,然后将模型数据赋值给还原后的图中的Tensor对象。
在TensorFlow中,函数tf.train.import_meta_graph可从meta文件中提取网络结构图传入tf.train.Saver对象中,并将tf.train.saver对象返回。示例:
import tensorflow as tf
with tf.Session() as sess:
#从meta文件中加载图结构
saver=tf.train.import_meta_graph('datasets/6_6_1_model/model-0.meta')
#从data文件和index文件中加载模型参数
saver.restore(sess,'datasets/6_6_1_model/model-0')
#获取当前图对象
graph=tf.get_default_graph()
#获取Tensor对象
v1_tf=graph.get_tensor_by_name("v1:0")
v2_tf=graph.get_tensor_by_name("v2:0")
output_tf=graph.get_tensor_by_name("add:0")
#打印输出结果
output,v1,v2=sess.run([output_tf,v1_tf,v2_tf])
print(3,'*',v1.tolist(),'+',5,'*',v2.tolist())
print('=',output.tolist())
代码中调用函数tf.train.import_meta_graph从meta文件中导入图结构,然后从当前图中获取指定的Tensor对象,最后取出打印。输出结果:
3*[[1.0,1.0,1.0],[[2.0,2.0,2.0]]+5*[[3.0,3.0,3.0],[[4.0,4.0,4.0]]
=[[18.0,18.0,18.0],[[26.0,26.0,26.0]]
4)将模型导出为单个pb文件:
TensorFlow框架存储模型数据时,会用三个文件存储,即meta文件、index文件和data文件。TensorFlow允许将这三个模型文件转为一个pb文件。使用一个pb文件存储模型数据有如下好处:
· 使用方便,相比同时管理三个文件,使用一个文件更加方便。
· 隐藏网络结构。封装成一个pb文件后,存储的参数全部为常量,即所有变量都转为常量存储,可以隐藏网络结构细节。
此外,TensorFlow还提供了移动端模型运行库,使用时需要将模型转为pb文件。
①将模型转为pb文件:
将模型转为pb文件,也就是将变量转为常量存放在图中。TensorFlow框架提供了将变量转为常量的函数tf
tf.graph_util.convert_variables_to_constants(
sess,
input_graph_def,
output_node_names,
variable_names_whitelist=None,
variable_names_blacklist=None
)
各个参数的含义及数据类型:
· sess:包含需要转换的变量的tf.Session对象。
· input_graph_def:GraphDef对象,持有指定图的引用。
· output_node_names:名称列表,指定转换后的图的输出节点列表。
· variable_names_whitelist:集合对象,指定需要转换为常量的变量名称,默认所有的变量都会转换。
· variable_names_blacklist:集合对象,指定不需要转为常量的变量。
将模型存储为pb文件的示例:
import tensorflow as tf
def build_graph(alpha,beta):
v1=tf.Variable(tf,zeros((2,3)),dtype=tf.float32,name='v1')
v2=tf.Variable(tf,zeros((2,3)),dtype=tf.float32,name='v2')
output=tf.add(alpha*v1,beta*v2,name='add')
return output
def main():
alpha_tf=tf.placeholder(shape(),dtype=tf.float32,name='alpha')
beta_tf=tf.placeholder(shape(),dtype=tf.float32,name='beta')
output_tf=build_graph(alpha_tf,beta_tf)
saver=tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess,'datasets/6_6_1_model/model-0')
#将图中的变量转为常量
output_graph_def=tf.graph_util
#将新的图保存到datasets/6_6_1_model/out.pb文件中
tf.train.write_graph(output_graph_def
if __name__=='__main__':
main()
代码中,首先定义了网络结构,然后将模型参数加载到当前图中,继而将当前图中的所有变量转为常量,并将add计算节点的输出作为最终图的输出结果。后面的代码将当前图保存到指定路径的指定文件中。注意,指定输出节点时,名称要与图中计算节点中定义的名称一致。
②使用pb模型文件:
生成pb模型文件后,就可以使用。示例代码:
import tensorflow as tf
with tf.Session() as sess:
with open('datasets/6_6_1_model/out.pb','rb') as f:
graph_def=tf.GraphDef()
graph_def=ParseFromString(f.read())
#导入图,并传入输入数据,取出输出数据
output=tf.import_graph_def(graph_def,input_map
print(sess.run(output))
代码中,读取pb文件,创建图对象,解析读取到的pb文件并传入图中;导入图并传入输入数据后,取出输出结果。其中,input_map参数用于将数据传入placeholder,return_elements参数用于指定输出Tensor。代码执行后,输出:
[array([[7.,7.,7.],[10.,10.,10.]],dtype=float32)]
注意,input_map参数指定的placeholder名称要与图中的placeholder名称一致,return _elements指定的名称需要与图中定义的输出名称一致。
六、TensorFlow数据预处理:
在读取图片数据后,通过对图片做随机光照变化、随机裁剪、随机旋转等预处理操作,可以扩充训练集。Tensor
1. 随机光照变化:
实际项目中,大部分卷积神经网络模型在训练时都可以通过对图像随机修改光照来扩充训练集。可以使用TensorFlow框架内置的预处理函数来随机修改饱和度、对比度、色相及亮度等。
1)随机饱和度变化:
在TensorFlow中,函数tf.image.random_saturation用于对图片做随机饱和度变化,函数原型:
tf.image.random_saturation(
image,
lower,
upper,
seed=None
)
各个参数的含义及数据类型:
· image:Tensor对象,数据为三维的RGB图像,或者第一维为Batch的四维批量Tensor图片。
· lower:float类型,作为随机饱和度变化的最小比例系数。
· upper:float类型,作为随机饱和度变化的最大比例系数。
· seed:整数类型,最终的种子会根据seed参数和TensorFlow图中的种子参数计算得到。
函数tf.image.random_saturation返回的Tensor与输入的image的shape一致。并且数据类型也一致。需要注意,如果参数upper≤lower或者lower<0,则会抛出异常。示例:
import tensorflow as tf
import cv2
img_path_tf=tf.convert_to_tensor(['datasets/imgs/test.jpg'],dtype=tf.string)
[img_path_queue]=tf.train.slice_input_producer([img_path_tf])
img_data_tf=tf.read_file(img_path_queue)
img_tf=tf.image.decode_jpeg(img_data_tf,channels=3)
img_tf=tf.image.random_saturation(img_tf,2.0,10.0)
with tf.Session() as sess:
coord=tf.train.Coordinator()
#启动所有队列线程,使得每个队列源源不断执行入队和出队操作
threads=tf.train.start_queue_runner(coord=coord)
for i in range(10):
img=sess.run(img_tf)
#opencv存储的是RGB格式,需要将RGB图片转为BGR格式
img=cv2.cvtColor(img,cv2.COLOR_RGB2BGR)
cv2.imwrite('datasets/outputs/output_%d.jpg'%i,img)
coord.request.stop()
coord.join(threads)
代码中,先构建图片路径队列,这里只读取一张图片,队列里存放的图片路径完全相同;然后读取图片数据,并对JPEG格式图片进行数据解码;下面是对图片做随机饱和度变化,为了有明显的对比效果,将随机饱和度变化最小比例系数设置为2,最大比例系数设置为10;最后将图片保存到指定目录中。需要注意,OpenCV所管理的图片的数据格式是BGR,因此需要将图片先转为BGR格式。代码执行后,指定目录下生成了图片。
除了随机饱和度变化,TensorFlow框架还提供了tf.image.adjust_saturation,用于指定饱和度系数,函数原型:
tf.image.adjust_saturation(
image,
saturation_factor,
name=None
)
其中,image参数与上面的一致;saturation_factor参数的数据类型为float,用于指定饱和度系数;name参数的数据类型为字符串,表示当前Operation对象的名称。
2)随机色相变化:
在TensorFlow中,函数tf.image.random_hue用于对图片做随机色相变化。做色相变化时,首先将图片从RGB格式转为HSV格式,根据用户传入的参数delta对H通道的值做调整后,再将HSV格式转回RGB格式。函数原型:
tf.image.random_hue(
image,
max_delta,
seed=None
)
各个参数的含义及数据类型:
· image:Tensor对象,数据为三维的RGB图像,或者第一维为Batch的四维批量Tensor图片。
· max_delta:float类型,随机delta的最大值,取值范围[0,0.5],传入图片的delta从[-max_delta, max_delta]中随机抽取。
· seed:整数类型,最终的种子会根据seed参数和TensorFlow图中的种子参数计算得到。
函数tf.image.random_hue返回的Tensor与输入的image的shape一致,数据类型也一致。
示例:
img_tf=tf.image.random_hue(img_tf,0.5)
TensorFlow框架还提供了函数tf.image.adjust_hue,用于指定参数delta。函数原型:
tf.image.adjust_hue(
image,
delta,
name=None
)
其中delta参数数据类型为float,用于指定delta的值,取值范围[-1,1]。
3)随机对比度变化:
在TensorFlow中,函数tf.image.random_contrast用于对图片做随机对比度变化。函数原型:
tf.image.random_contrast(
image,
lower,
upper,
seed=None
)
函数tf.image.random_contrast首先将传入的image数据转为float类型,完成对对比度调整后再将数据类型转回原数据类型。对比度变换算法:
· 计算每个通道的像素值的均值mean
· 随机算法随机取出对比度参数contrast_factor
· 对每个通道的像素值x,对比度变换后的值为(x-mean)*contrast_factor+mean
函数tf.image.random_contrast返回的Tensor与输入的image的shape一致,数据类型也一致。示例:
img_tf=tf.image.random_contrast(img_tf,0.0,20.0)
TensorFlow框架还提供了函数tf.image.adjust_contrast,用于指定对比度系数。函数原型:
tf.image.adjust_contrast(
image,
contrast_factor
)
其中contrast_factor参数数据类型为float,用于指定对比度系数。
4)随机亮度变化:
通过随机亮度变化,可以将训练数据尽可能多地覆盖到不同的光照亮度场景。TensorFlow中,tf.image.adjust_brightness用于对图片做随机亮度变化,函数原型:
tf.image.random_brightness(
image,
max_delta,
seed=None
)
参数max_delta为float类型,随机delta的最大值,要大于等于0,即[0,+∞),传入图片的delta从[-max_delta, max_delta]中随机抽取。
函数tf.image.random_brightness首先将传入的image数据转为float类型,完成对亮度调整后再将数据类型转回原数据类型。返回的Tensor与输入的image的shape一致,数据类型也一致。示例:
img_tf=tf.image.random_brightness(img_tf,100.0/255)
TensorFlow框架还提供了函数tf.image.adjust_brightness,用于指定参数delta调整亮度。函数原型:
tf.image.adjust_brightness(
image,
delta
)
其中参数为标量,计算亮度时会转为浮点数,取值范围为[0,1)。
5)随机伽马变化:
在TensorFlow中,没有直接对图像做随机伽马变化的函数,但是提供了调整伽马值的函数,可以通过生成随机数结合伽马变化函数的方式来实现随机伽马变化。tf.image.adjust_gamma函数原型:
tf.image.adjust_gamma(
image,
gamma=1,
gain=1
)
各个参数的含义及数据类型:
· image:Tensor对象。
· gamma:标量或者Tensor对象,非负实数。
· gain:标量或者Tensor对象,常量系数。
函数tf.image.adjust_gamma首先将传入的image的数据范围放缩到[0,1]。对于像素x,其输出值为out=gain*(x**gamma)。伽马调整完成后,再按缩放系数将数据范围恢复。如果gamma大于1,输出图比输入图更暗;如果gamma小于1,则输出图比输入图更亮。示例:
img_tf=tf.image.adjust_gamma(img_tf,gamma=2.0,gain=2)
通过生成随机数方式,随机改变gamma参数的值,来实现随机伽马变化的示例:
import tensorflow as tf
import cv2
#封装随机伽马变化函数
def random_gamma(image,min_gamma,max_gamma):
gamma=tf.random_uniform(shape=(),minval=min_gamma,maxval=max_gamma
ori_dtype=image.dtype
image=tf.cast(image,tf.float32)
image=tf.image.adjust_gamma(image,gamma=gamma)
return tf.cast(image,ori_dtype)
#读取图片
img_path_tf=tf.convert_to_tensor(['datasets/imgs/test.jpg'],dtype=tf.string)
[img_path_queue]=tf.train.slice_input_producer([img_path_tf])
img_data_tf=tf.read_file(img_path_queue)
img_tf=tf.image.decode_jpeg(img_data_tf,channels=3)
img_tf=random_gamma(img_tf,0.7,1.3)
with tf.Session() as sess:
coord=tf.train.Coordinator()
#启动所有队列线程,使得每个队列源源不断执行入队和出队操作
threads=tf.train.start_queue_runner(coord=coord)
for i in range(10):
img=sess.run(img_tf)
#opencv存储的是RGB格式,需要将RGB图片转为BGR格式
img=cv2.cvtColor(img,cv2.COLOR_RGB2BGR)
cv2.imwrite('datasets/outputs/output_%d.jpg'%i,img)
coord.request.stop()
coord.join(threads)
伽马变化要求输入的数据类型为浮点数,因此先将输入图的数据类型保留,然后将输入图的数据类型转为浮点数后执行伽马变化,完成后再将输出的数据类型转为原数据类型。
2. 翻转、转置与旋转:
对训练集做随机翻转、随机旋转及随机转置,可以使得模型对图像方向有更强的适应能力。
1)随机上下左右翻转:
TensorFlow中,函数tf.image.flip_up_down用来对图像做上下翻转,函数tf.image.flip_left_right用来对图像做左右翻转。函数原型:
tf.image.flip_up_down(image)
tf.image.flip_left_right(image)
其中的image是shape为[batch,height,width,channels]的四维Tensor对象,或者shape为[height
import tensorflow as tf
import cv2
#读取图片
img_path_tf=tf.convert_to_tensor(['datasets/imgs/test.jpg'],dtype=tf.string)
img_tf=tf.image.decode_jpeg(img_data_tf,channels=3)
#上下翻转
up_down_img_tf=tf.image.flip_up_down(img_tf)
#左右翻转
left_right_img_tf=tf.image.flip_left_right(img_tf)
#在width维度连接
up_down_concat=tf.concat([img_tf,up_down_img_tf],axis=1)
left_right_concat=tf.concat([img_tf,left_right_img_tf],axis=1)
with tf.Session() as sess:
up_down,left_right=sess.run([up_down_concat,left_right_concat])
#opencv存储的是RGB格式,需要将RGB图片转为BGR格式
up_down=cv2.cvtColor(up_down,cv2.COLOR_RGB2BGR)
left_right=cv2.cvtColor(left_right,cv2.COLOR_RGB2BGR)
#保存图片
cv2.imwrite('datasets/outputs/up_down.jpg',up_down)
cv2.imwrite('datasets/outputs/left_right.jpg',left_right)
在TensorFlow中,函数tf.image
tf.image.random_flip_up_down(
image,
seed=None
)
tf.image.random_flip_left_right(
image,
seed=None
)
2)随机图像转置:
图像转置功能是将图像中像素点坐标系中的x轴和y轴交换,TensorFlow框架中,函数tf.image.transpose_image就是将图像转置。函数原型:
tf.image.transpose_image(image)
其中参数image是shape为[batch,height,width,channels]的四维Tensor对象,或者shape为[height
import tensorflow as tf
import cv2
#读取图片
img_path_tf=tf.convert_to_tensor(['datasets/imgs/test.jpg'],dtype=tf.string)
img_tf=tf.image.decode_jpeg(img_data_tf,channels=3)
transposed_tf=tf.image.transpose_image(img_tf)
with tf.Session() as sess:
ori_img,transposed_img=sess.run([img_tf,transposed_tf])
#opencv存储的是RGB格式,需要将RGB图片转为BGR格式
ori_img=cv2.cvtColor(ori_img,cv2.COLOR_RGB2BGR)
transposed_img=cv2.cvtColor(transposed_img,cv2.COLOR_RGB2BGR)
#保存图片
cv2.imwrite('datasets/outputs/ori.jpg',ori_img)
cv2.imwrite('datasets/outputs/transposed.jpg'
为了实现随机转置功能,可以先利用函数tf.random_uniform产生随机数,再根据随机数的大小来随机做转置。示例:
import tensorflow as tf
import cv2
#读取图片
img_path_tf=tf.convert_to_tensor(['datasets/imgs/test.jpg'],dtype=tf.string)
[img_path_queue]=tf.train.slice_input_producer([img_path_tf])
img_data_tf=tf.read_file(img_path_queue)
img_tf=tf.image.decode_jpeg(img_data_tf,channels=3)
random_num=tf.random_uniform(shape=(),minval=0,maxval=1,dtype=tf.float32)
img_tf=tf.cond(tf.less(random_num,0.5),true_fn=lambda:img_tf,false_fn
with tf.Session() as sess:
coord=tf.train.Coordinator()
#启动所有队列线程,使得每个队列源源不断执行入队和出队操作
threads=tf.train.start_queue_runner(coord=coord)
for i in range(5):
img=sess.run(img_tf)
#opencv存储的是RGB格式,需要将RGB图片转为BGR格式
img=cv2.cvtColor(img,cv2.COLOR_RGB2BGR)
cv2.imwrite('datasets/outputs/output_%d.jpg'%i,img)
coord.request.stop()
coord.join(threads)
代码中将生成的随机数与0.5比较,如果比0.5小不做变换,否则转置。
3)随机旋转:
在大部分实际项目中,希望模型对同一张照片不同拍摄角度的识别结果是一致的,因此在训练模型时需要对输入图进行随机旋转预处理。在Tensor框架中,函数tf.contrib.image.rotate是对图片做指定角度的逆时针方向旋转。函数原型:
tf.contrib.image.rotate(
images,
angles,
interpolation='NEAREST',
name=None
)
各个参数的含义及数据类型:
· images:shape为[batch,height,width,channels]的四维Tensor对象,或者shape为[height,width, channels]的三维Tensor对象,也或者shape为[,height,width]的二维Tensor对象。并且每个维度的大小必须确定,即每个维度都不能为None。
· angles:标量类型,表示所有图片的旋转角度,或者是长度为Batch的一维Tensor(此时images必须是四维),表示Batch中每张图片的旋转角度。
· interpolation:字符串类型,表示插值算法,目前只支持NEAREST和BILINEAR两种。
· name:字符串类型,表示当前Operation对象的名称。
对不同维度Tensor对象的旋转示例:
import tensorflow as tf
import cv2
import math
#读取图片
img_path_tf=tf.convert_to_tensor(['datasets/imgs/test.jpg'],dtype=tf.string)
[img_path_queue]=tf.train.slice_input_producer([img_path_tf])
img_data_tf=tf.read_file(img_path_queue)
#二维Tensor
img_tf_1c=tf.image.decode_jpeg(img_data_tf,channels=1)
img_tf_1c.set_shape((256,256,1))
img_tf_1c=tf.squeeze(img_tf_1c,axis=2)
#三维Tensor
img_tf_3c=tf.image.decode_jpeg(img_data_tf,channels=3)
img_tf_3c.set_shape((256,256,3))
#四维Tensor
img_tf_batch=tf.train.batch(img_tf_3c,batch_size=5,capacity=20)
#逆时针方向旋转30度
img_tf_1c=tf.contrib.image.rotate(img_tf_1c,angles=math.pi/6)
img_tf_3c=tf.contrib.image.rotate(img_tf_3c,angles=math.pi/6)
img_tf_batch=tf.contrib.image.rotate(img_tf_batch,angles=math.pi/6)
with tf.Session() as sess:
coord=tf.train.Coordinator()
#启动所有队列线程,使得每个队列源源不断执行入队和出队操作
threads=tf.train.start_queue_runner(coord=coord)
for i in range(5):
img_1c,img_3c=sess.run([img_tf_1c,img_tf_3c])
#opencv存储的是RGB格式,需要将RGB图片转为BGR格式
img_1c=cv2.cvtColor(img_1c,cv2.COLOR_RGB2BGR)
img_3c=cv2.cvtColor(img_3c,cv2.COLOR_RGB2BGR)
cv2.imwrite('datasets/outputs/2d_%d.jpg'%i,img_1c)
cv2.imwrite('datasets/outputs/3d_%d.jpg'%i,img_3c)
img_batch=sess.run(img_tf_batch)
for i in range(5):
img=cv2.cvtColor(img_batch[i],cv2.COLOR_RGB2BGR)
cv2.imwrite('datasets/outputs/4d_%d.jpg'%i,img)
coord.request.stop()
coord.join(threads)
为了实现随机旋转,也需要借助函数tf.random_uniform随机生成旋转角度。示例:
import tensorflow as tf
import cv2
import math
#读取图片
img_path_tf=tf.convert_to_tensor(['datasets/imgs/test.jpg'],dtype=tf.string)
[img_path_queue]=tf.train.slice_input_producer([img_path_tf])
img_data_tf=tf.read_file(img_path_queue)
#三维Tensor
img_tf=tf.image.decode_jpeg(img_data_tf,channels=3)
#随机生成旋转角度
angle=tf.random_uniform(shape=(),minval=0,maxval=2*math.pi,dtype=tf.float32)
img_tf=tf.contrib.image.rotate(img_tf,angles=angle)
with tf.Session() as sess:
coord=tf.train.Coordinator()
#启动所有队列线程,使得每个队列源源不断执行入队和出队操作
threads=tf.train.start_queue_runner(coord=coord)
for i in range(5):
img=sess.run(img_tf)
#opencv存储的是RGB格式,需要将RGB图片转为BGR格式
img=cv2.cvtColor(img,cv2.COLOR_RGB2BGR)
cv2.imwrite('datasets/outputs/rotate_%d.jpg'%i,img)
coord.request.stop()
coord.join(threads)
3. 裁剪与Resize:
实际项目中,训练模型的数据往往来自许多不同的站点,这可能会导致每张图的宽高大小不一致。在TensorFlow中按Batch读取数据时,Batch中的所有图片的shape必须一致,因此需要对图片统一Resize或者裁剪。在裁剪与Resize对模型学习结果无影响前提下,建议在预处理时对图像做随机裁剪并Resize到指定宽高。
1)图像裁剪:
TensorFlow框架提供相关函数接口用于实现裁剪图像指定区域和随机裁剪图像区域。
①裁剪图像指定区域:
TensorFlow中,函数tf.image.decode_and_crop_jpeg可对JPEG格式图片进行数据解码并裁剪指定窗口区域。函数原型:
tf.image.decode_and_crop_jpeg(
contents,
crop_window,
channels=0,
ratio=1,
fancy_upscaling=True,
try_recover_truncated=False,
acceptable_fraction=1,
dct_method='',
name=None
)
此函数返回数据类型为uint8的Tensor对象,其常用参数的含义及数据类型:
· contents:0维的数据类型为string的Tensor对象,为JPEG编码的图片数据。
· crop_window:数据类型为int32、shape为[crop_y,crop_x,crop_height,crop_width]的一维Tensor对象,表示裁剪窗口。
· channels:整数类型,只能取0、1、3,默认0。0表示按照JPEG图片编码时采用的通道数,1表示转为灰度图后输出,3表示输出为RGB图像。
· ratio:整数类型,默认1,表示缩小倍数。
· name:字符串类型,表示当前Operation对象的名称。
另外,函数tf.image.crop_to_bounding_box用来裁剪指定图像的指定区域,函数原型:
tf.image.crop_to_bounding_box(
image,
offset_height,
offset_width,
target_height,
target_width
)
各个参数的含义及数据类型:
· image:shape为[height,width,channel]的三维Tensor对象,或者是shape为[batch ,height,width,channels]的四维Tensor对象。
· offset_height:左上角的Y坐标值。
· offset_width:左上角的X坐标值。
· target_height:裁剪区域的高度。
· target_width:裁剪区域的宽度。
此外,tf.image.center_crop用于以图像中心为中点裁剪指定比例区域,函数原型:
tf.image.center_crop(
image,
central_fraction
)
其中。imag是shape为[height,width,channel]的三维Tensor对象,或者是shape为[batch
import tensorflow as tf
import cv2
#读取图片
img_data_tf=tf.read_file('datasets/imgs/test.jpg')
img_tf=tf.image.decode_jpeg(img_data_tf,channels=3)
#对原数据解码,并裁剪指定区域
decode_and_crop_tf=tf.image.decode_and_crop_jpeg(img_data_tf,[0,0,128,128])
crop_to_bb_tf=tf.image.crop_to_bounding_box(img_tf,128,128,128,128)
central_crop_tf=tf.image.central_crop(img_tf,0.5)
with tf.Session() as sess:
img,decode_crop,crop_bb,central_crop=sess.run([img_tf,decode_and_crop_tf
#opencv存储的是RGB格式,需要将RGB图片转为BGR格式
img=cv2.cvtColor(img,cv2.COLOR_RGB2BGR)
decode_crop=cv2.cvtColor(decode_crop,cv2.COLOR_RGB2BGR)
crop_bb=cv2.cvtColor(crop_bb,cv2.COLOR_RGB2BGR)
central_crop=cv2.cvtColor(central_crop,cv2.COLOR_RGB2BGR)
#保存图片
cv2.imwrite('datasets/outputs/0_ori_img.jpg',img)
cv2.imwrite('datasets/outputs/1_decode_crop.jpg',decode_crop)
cv2.imwrite('datasets/outputs/2_crop_bb.jpg',crop_bb)
cv2.imwrite('datasets/outputs/3_central_crop.jpg',central_crop)
②随机裁剪:
实际项目中,可能会用到随机裁剪,这样可以得到更多样本。TensoFlow中,函数tf.random_crop用于随机裁剪,裁剪对象可以为图像或任意Tensor对象。函数原型:
tf.random_crop(
value,
size,
seed=None,
name=None
)
各个参数的含义及数据类型:
· value:需要裁剪的Tensor对象。
· size:一维Tensor对象,其列表中每个参数对应value的shape中每个维度需要裁剪的大小。
· seed:整数类型,用于创建随机种子。
· name:字符串类型,表示当前Operation对象的名称。
函数tf.random_crop会在value的每个维度随机产生偏移量,因此需要确保value的shape中每个维度的大小要大于等于size设置的值。如果某个维度不需要裁剪,只需将size中对应的值设置为value中对应维度的大小。示例:
import tensorflow as tf
import cv2
import math
#读取图片
img_path_tf=tf.convert_to_tensor(['datasets/imgs/test.jpg'],dtype=tf.string)
[img_path_queue]=tf.train.slice_input_producer([img_path_tf])
img_data_tf=tf.read_file(img_path_queue)
#img_tf的shape为[256,256,3]
img_tf=tf.image.decode_jpeg(img_data_tf,channels=3)
#对图像随机裁剪
random_crop_tf=tf.random_crop(img_tf,[160,160,3])
with tf.Session() as sess:
coord=tf.train.Coordinator()
#启动所有队列线程,使得每个队列源源不断执行入队和出队操作
threads=tf.train.start_queue_runner(coord=coord)
for i in range(5):
random_crop=sess.run(random_crop_tf)
#opencv存储的是RGB格式,需要将RGB图片转为BGR格式
random_crop=cv2.cvtColor(img,cv2.COLOR_RGB2BGR)
cv2.imwrite('datasets/outputs/random_crop_%d.jpg'%i
coord.request.stop()
coord.join(threads)
2)图像Resize:
对图像裁剪后,一般需要对裁剪后的图像做一次Resize操作。Resize操作需要指定经过变换后的输出宽高,如果指定的输出宽高比例与输入图的宽高比例不一致,有两种处理方式:
· 强制拉伸,将宽高伸缩到指定大小。
· 等比放缩,剩余区域填充常数。
①强制拉伸:
在TensorFlow中,函数tf.image.resize_image_with_crop_or_pad及函数tf.image.crop_and _resize可用于对图像Resize操作,其中tf.image.crop_and_resize的函数原型:
tf.image.crop_and _resize(
image,
boxes,
box_ind,
crop_size,
method='bilinear',
extrapolation_value=0,
name=None
)
各个参数的含义及数据类型:
· image:Tensor对象,数据类型只能取uint8、uint16、int8、int16、int32、int64、half、float32、float64中的一种,并且必须是shape为[batch,height,width,channels]的四维Tensor对象。
· boxes:数据类型为float32,且shape为[num_boxes,4]的二维Tensor对象。每一行代表一个裁剪窗口,裁剪窗口格式[y1,x1,y2,x2],其中x和y为归一化后的值,即取值范围[0,1],换算回原坐标为x=x*(width-1),y=y*(height-1)。允许y1>y2及x1>x2。如果归一化坐标不在区间[0,1]中,根据参数extrapolation_value的值来推算超出的部分值。
· box_ind:数据类型int32,且shape为[num_boxes]的一维Tensor对象,取值范围[0,batch],box_ind[i]指定参数boxes中窗口区域作为第i个输出图。
· crop_size:数据类型int32,且长度为2的一维Tensor对象,shape为[crop_height,crop_width],两个值必须大于0。所有图片被裁剪后的区域都要Resize到crop_size大小,原图像的宽高比不会被保留。
· method:string类型,只能取bilinear或nearest,默认bilinear,表示Resize算法。
· extrapolation_value:float类型,默认0,用于推算超出区域的值。
· name:字符串类型,表示当前Operation对象的名称。
函数tf.image.crop_and _resize的参数box_ind的长度必须与参数boxes的第一个维度的长度相等。示例:
import tensorflow as tf
import cv2
#读取图片
img_path_tf=tf.convert_to_tensor(['datasets/imgs/test.jpg'],dtype=tf.string)
[img_path_queue]=tf.train.slice_input_producer([img_path_tf])
img_data_tf=tf.read_file(img_path_queue)
img_tf=tf.image.decode_jpeg(img_data_tf,channels=3)
img_tf.set_shape((256,256,3))
img_batch=tf.train.batch([img_tf],batch_size=4)
boxes=[[0.0,0.0,0.5,0.5],[0.0,0.5,0.5,1.0],[0.5,0.0,1.0,0.5],[0.5,0.5,1.0,1.0]]
#对图像裁剪并Resize
crop_and_resize_tf=tf.image.crop_and_resize(img_batch,boxes,[0,1,2,3],[256,256])
with tf.Session() as sess:
coord=tf.train.Coordinator()
#启动所有队列线程,使得每个队列源源不断执行入队和出队操作
threads=tf.train.start_queue_runner(coord=coord)
crop_and_resize=sess.run(crop_and_resize_tf)
for i in range(4):
img=crop_and_resize[i]
#opencv存储的是RGB格式,需要将RGB图片转为BGR格式
img=cv2.cvtColor(img,cv2.COLOR_RGB2BGR)
cv2.imwrite('datasets/outputs/crop_and_resize_%d.jpg'%i,img)
coord.request.stop()
coord.join(threads)
代码中设置图像shape,并按batch_size=4来批量读取数据;然后设置裁剪窗口区域,将图片按照从上到下、从左到右的顺序平均分为4个区域;接着按照参数boxes的顺序裁剪,并且Resize到宽高[256,256];最后保存到指定目录中。
②裁剪多余区域或填充不够区域:
函数tf.image.resize_image_with_crop_or_pad可将图像Resize到指定宽高,如果指定宽高比与图像原宽高比不一致,那么采用按中心裁剪或者边界补0的方式resize到指定大小。
如果原图像的宽度(或高度)比指定宽度(或高度)大,那么将图像的宽度(或高度)按正中心裁剪到指定宽度(或高度)大小;如果原图像宽度(或高度)小于指定宽度(或高度),那么将图像的宽度(或高度)维度两边补0。函数原型:
tf.image.resize_image_with_crop_or_pad(
image,
target_height,
target_width,
method=ResizeMethod.BILINEAR
)
各个参数含义及数据类型:
· image:shape=[batch,height,width,channels]的四维Tensor对象,或者shape=[height,width, channels]的三维Tensor对象。
· target_height:整数类型,Resize后的高度。
· target_width:整数类型,Resize后的宽度。
· method:ResizeMethod对象,指定Resize算法,默认ResizeMethod.BILINEAR。
示例:
import tensorflow as tf
import cv2
#读取图片
img_data_tf=tf.read_file('datasets/imgs/test.jpg')
img_tf=tf.image.decode_jpeg(img_data_tf,channels=3)
#原图像宽高256*256,将原图像Resize到[height,width]=[256,128]
img_1_tf=tf.image.resize_image_with_crop_or_pad(img_tf,target_height=256
#将原图像Resize到[height,width]=[128,384]
img_2_tf=tf.image.resize_image_with_crop_or_pad(img_tf,target_height=128
with tf.Session() as sess:
img_1,img_2=sess.run([img_1_tf,img_2_tf])
#opencv存储的是RGB格式,需要将RGB图片转为BGR格式
img_1=cv2.cvtColor(img_1,cv2.COLOR_RGB2BGR)
img_2=cv2.cvtColor(img_2,cv2.COLOR_RGB2BGR)
#保存图片
cv2.imwrite('datasets/outputs/crop_pad_1.jpg',img_1)
cv2.imwrite('datasets/outputs/crop_pad_1.jpg',img_2)
③其他Resize函数:
TensorFlow还提供了可以指定Resize算法的函数,函数原型分别为:
#使用area插值算法
tf.image.resize_area(
images,
size,
align_corners=False,
name=None
)
#使用bicubic插值算法
tf.image.resize_bicubic(
images,
size,
align_corners=False,
name=None
)
#使用bilinear插值算法
tf.image.resize_bilinear(
images,
size,
align_corners=False,
name=None
)
#使用nearest neighbor插值算法
tf.image.resize_nearest_neighbor(
images,
size,
align_corners=False,
name=None
)
上面函数的参数是一致的,各个参数的含义及数据类型:
· images:shape=[batch,height,width,channels]的四维Tensor对象,其数据类型只能取int8、uint8、int16、int32、int64、half、float32、float64中的一种。
· size:数据类型为int32的一维Tensor对象,Tensor对象长度为2,shape=[new_height, new_width],表示Resize后的高度和宽度。
· align_corners:bool类型,默认False。如果为True,则输入图与输出图边界上下左右四个顶点会对齐,保留四个顶点的像素值。
· name:string类型,表示当前Operation对象的名称。
以上算法不会保留宽高比,即输出图会将输入图的宽高强制伸缩到指定的宽高。示例:
import tensorflow as tf
import cv2
#读取图片
img_data_tf=tf.read_file('datasets/imgs/test.jpg')
img_tf=tf.image.decode_jpeg(img_data_tf,channels=3)
#在索引0处添加一个新的维度,[height,width,channels]-->[1,height,width,channels]
img_tf=tf.expand_dims(img_tf,axis=0)
#分别执行不同的Resize算法
area_tf=tf.image.resize_area(img_tf,(128,64))
bicubic_tf=tf.image.resize_bicubic(img_tf,(64,128))
bilinear_tf=tf.image.resize_bilinear(img_tf,(128,128))
nearest_neighbor_tf=tf.image.resize_nearest_neighbor(img_tf,(128,256))
#去掉第一个维度
area_tf=tf.squeeze(area_tf,axis=0)
bicubic_tf=tf.squeeze(bicubic_tf,axis=0)
bilinear_tf=tf.squeeze(bilinear_tf,axis=0)
nearest_neighbor_tf=tf.squeeze(nearest_neighbor_tf,axis=0)
with tf.Session() as sess:
area,bicubic,bilinear,nearest_neighbor=sess.run([area_tf,bicubic_tf
#opencv存储的是RGB格式,需要将RGB图片转为BGR格式
area=cv2.cvtColor(area,cv2.COLOR_RGB2BGR)
bicubic=cv2.cvtColor(bicubic,cv2.COLOR_RGB2BGR)
bilinear=cv2.cvtColor(bilinear,cv2.COLOR_RGB2BGR)
nearest_neighbor=cv2.cvtColor(nearest_neighbor,cv2.COLOR_RGB2BGR)
#保存图片
cv2.imwrite('datasets/outputs/area.jpg',area)
cv2.imwrite('datasets/outputs/bicubic.jpg',bicubic)
cv2.imwrite('datasets/outputs/bilinear.jpg',bilinear)
cv2.imwrite('datasets/outputs/nearest_neighbor.jpg',nearest_neighbor)
4. 用OpenCV对图像进行动态预处理:
实际项目中,TensorFlow自带的图像处理函数无法满足需求,可以借助OpenCV库对图像做预处理。
1)静态预处理和动态预处理:
预处理分为静态预处理和动态预处理。静态预处理即对原数据集做各种随机处理以生成更庞大的数据集,这是在训练之前将训练集中所有图片做处理,可以使用任何工具或者库实现,处理简单,但生成的训练集太大,不易管理维护,而且生成的数据集覆盖范围有限,一旦生成出来就数据集后覆盖范围也随之确定。
动态预处理为运行时对输入图进行随机处理,是在训练期间随机处理图片,理论上可以把训练集看成无穷张不一样的图片,训练时间越长,训练集覆盖的范围越广。
2)在TensorFlow中调用OpenCV:
在Python库中,OpenCV的cv::Mat对象为numpy.ndarray对象,因此可以将Tensor对象与OpenCV对象做转换。先将Tensor对象转为numpy.ndarray对象,利用OpenCV库处理图像后再转为Tensor对象返回。
创建对训练图Tensor对象和遮挡物Tensor对象进行随机融合的函数示例:
import tensorflow as tf
import cv2
import numpy as np
#img_tf为训练集图像,obj_tf为遮挡物
def random_add_obj(img_tf,obj_tf):
h,w,c=img_tf.get_shape().as_list()
def random_add_func(img,obj)
#将遮挡物Resize大小
random_w=int(np.random.uniform(50,w))
random_h=int(np.random.uniform(50,h))
obj=cv2.resize(obj,(random_w,random_h))
#计算遮挡物的mask
obj_gray=cv2.cvtColor(obj,cv2.COLOR_RGB2GRAY)
locs=np.where(obj_gray!=255)
mask=np.zeros((random_h,random_w),np.uint8)
mask[locs[0],locs[1]]=255
#随机生成图像融合中心
offset_x=np.random.uniform(0,w-random_w-1)
offset_y=np.random.uniform(0,h-random_h-1)
center=(int(offset_x+random_w/2),int(offset_y+random_h/2))
#使用泊松融合算法将图片融合
outout=cv2.seemlessClone(obj,img,mask,center,cv2.MIXED_CLONE)
return output
output_tf=tf.py_func(random_add_func,[img_tf,obj_tf],(tf.uint8))
output_tf.set_shape((h,w,c))
return output_tf
代码中使用OpenCV库中的泊松融合算法将图片与遮挡物随机融合,先将遮挡物Resize到随机大小,接着提取遮挡物的mask,即将非白色区域作为前景,白色区域作为透明背景;然后随机生成融合位置,并使用泊松融合算法将两张图进行融合。其中使用tf.py_func函数实现将Tensor对象与numpy.ndarray对象无缝自动转换。
有了融合函数,接下来使用TensorFlow队列机制读取训练集和遮挡物,将二者随机融合。示例:
def get_data(batch_size):
#读取训练图片
img_path_tf=tf.convert_to_tensor(['datasets/imgs/test.jpg'],dtype=tf.string)
[img_path_queue]=tf.train.slice_input_producer([img_path_tf])
img_data_tf=tf.read_file(img_path_queue)
img_tf=tf.image.decode_jpeg(img_data_tf,channels=3)
img_tf.set_shape((256,256,3))
#读取遮挡物
obj_path_tf=tf.convert_to_tensor(['datasets/imgs/test2.jpg'],dtype=tf.string)
[obj_path_queue]=tf.train.slice_input_producer([obj_path_tf])
obj_data_tf=tf.read_file(obj_path_queue)
obj_tf=tf.image.decode_jpeg(obj_data_tf,channels=3)
#对图像做预处理
output_tf=random_add_obj(img_tf,obj_tf)
#批量读取
img_batch=tf.train.batch([output_tf],batch_size=batch_size)
return img_batch
input_tf=get_data(4)
with tf.Session() as sess:
coord=tf.train.Coordinator()
#启动所有队列线程,使得每个队列源源不断执行入队和出队操作
threads=tf.train.start_queue_runner(coord=coord)
input=sess.run(input_tf)
for i in range(4):
img=input[i]
#opencv存储的是RGB格式,需要将RGB图片转为BGR格式
img=cv2.cvtColor(img,cv2.COLOR_RGB2BGR)
cv2.imwrite('datasets/outputs/random_add_%d.jpg'%i,img)
coord.request.stop()
coord.join(threads)
代码中读取训练图片并解析JPEG格式图片,再读取遮挡物图片数据并解析JPEG格式图片,然后调用图片随机融合函数,并批量读取,最后保存到指定目录中。
七、TensorFlow模型训练:
使用TensorFlow训练模型时,需要掌握一些常见功能的实现,比如如何动态调整学习率并使之逐步降低,又如如何利用已有的网络模型只训练其中被修改的网络层中的参数,还有如何利用本机多GPU以提升Barch大小加快训练速度。
1. 反向传播中的优化器与学习率:
学习率指的是反向传播过程中,按照梯度方向更新参数的步长。在训练模型时,学习率往往是逐步下降的。
1)Global Step与Epoch:
一次反向传播完成后,称为一个Global Step。在没有特别注明情况下,为了简化描述,step均指Global Step。除了使用Step来描述训练次数外,Epoch也用于表达训练的次数多少,并且Epoch尤指训练集中所有数据训练的轮数。假设训练集有N张照片,当前训练的次数为Step,那么Epoch=Step/N。
2)梯度理论:
导数反映的是变化率,而方向导数是指函数f沿着某个方向v的变化率。在一个平面中方向有360°,梯度则是找函数f变化的最大方向。梯度是一个向量,它具有大小和方向。方向是指指数值增长最快的方向,大小则表示变化率。
3)使用学习率与梯度下降法求最优值:
学习率是指在反向传播过程中,按照梯度方向更新参数的步长。学习率本身离不开梯度和梯度下降法,使用梯度下降法求最优值时,每一次根据输入数据与其对应的输出数据更新参数,使得参数不断逼近真实值。
4)TensorFlow中的优化器:
实际应用中发现,梯度下降法得到的最优解往往是局部最优解及靠近局部最小值时收敛慢。在梯度下降法基础上,提出了随机梯度下降法、批量梯度下降法、SGDM算法、NAG算法、AdaGrad算法、RMSProp算法、Adam算法等,这些算法都是在梯度下降法基础上不断改进而来。
在TensorFlow中,所有优化算法都是tf.train.Optimizer对象的子类,包含如下优化器算法:
tf.train.Optimizer.AdadeltaOptimizer
tf.train.Optimizer.AdagradDAOptimizer
tf.train.Optimizer.AdamOptimizer
tf.train.Optimizer.FtrlOptimizer
tf.train.Optimizer.GradientDescentOptimizer
tf.train.Optimizer.MomentumOptimizer
tf.train.Optimizer.ProximalAdagradOptimizer
tf.train.Optimizer.ProximalGradientDescentOptimizer
tf.train.Optimizer.RMSPropOptimizer
tf.train.Optimizer.SyncReplicasOptimizer
各个优化器的接口一致。其中,tf.train
5)优化器中常用的函数:
使用梯度下降法求最优参数时,有如下必不可少的操作:计算各个变量的梯度;每次梯度更新时根据当前参数值计算其对应的梯度;更新参数值;反向传播时根据梯度值和学习率更新当前参数值。
①利用函数compute_gradients计算梯度:
函数compute_gradients用于计算从输入端到loss端所有路径中包含的变量对应的梯度。函数原型:
compute_gradients(
loss,
var_list=None,
gate_gradients=Gate_op,
aggregation_method=None,
colocate_gradients_with_ops=False,
grad_loss=None
)
常用参数含义及数据类型:
· loss:Tensor对象,表示最终需要最小化的Tensor对象。
· var_list:list对象,列表存放的是tf.Variable对象,用于指定需要计算梯度的参数变量,默认为所有变量,即集合tf.GraphKeys.TRAINABLE_VARIABLES中的所有变量。
此函数返回的是list对象,其中存放(gradient,variable)元组,variable表示tf.Variable对象,gradient表示variable的梯度。其中,variable是真实有效的tf.Variable对象。而gradient可能是None。
②利用函数apply_gradients更新参数:
函数apply_gradients用于根据指定变量及其对应梯度来更新变量的值。函数原型:
apply_gradients(
grads_and_vars,
global_step=None,
name=None
)
各个参数的含义及数据类型:
· grads_and_vars:list类型,存放的是(gradient,variable)元组,该参数一般是通过函数compute _gradients获得。
· global_step:tf.Variable类型,表示Global Step。如果传入该参数,则完成本次梯度更新后,指定的tf.Variable类型的Global Step会加1。
· name:字符串类型,表示返回的Operation对象的名称。
函数apply_gradients返回Operation对象,调用tf.Session的run函数执行该Operation时,会启动执行参数更新,若global_step不为None,则Global_step对应的Global Step自动加1。
③利用函数minimize计算梯度且更新参数:
函数minimize组合了函数compute_gradients和函数apply_gradients,即将函数compute _gradients的输出作为函数apply_gradients的输入。如果不关心梯度,可以直接调用函数minimize;而如果需要获取梯度,则需要分别使用compute_gradients和apply_gradients。函数minimize的原型:
minimize(
loss,
global_step=None,
var_list=None,
gate_gradients=Gate_op,
aggregation_method=None,
colocate_gradients_with_ops=False,
name=None,
grad_loss=None
)
其中参数可以参照前面的两个函数说明。
④使用优化器:
各个优化器的使用方法一致,以梯度下降法为例介绍。梯度下降优化器tf.train.Optimizer
__init__(
learning_rate,
use_locking=False,
name='GradientDecent'
)
各个参数的含义及数据类型:
· learning_rate:数据类型为浮点数的Tensor对象,表示学习率。
· use_locking:bool类型,表示在更新参数时,是否使用锁。
· name:字符串类型,表示梯度更新时Operation对象名称的前缀。
使用TensorFlow内置优化器实现梯度下降的示例:
import tensorflow as tf
import random
# 数据集解析式逼近y=5x+7
def get_data():
x=random.randint(0,100)
y=5*x+7
#随机生成误差,误差取值为[-1,1]
x_noise=random.random()*2-1
y_noise=random.random()*2-1
return x+x_noise,y+y_noise
def build_graph(input_tf,label_tf):
k_tf=tf.Variable(0,name='k',dtype=tf.float32)
b_tf=tf.Variable(0,name='b',dtype=tf.float32)
output_tf=k_tf*input_tf+b_tf
loss_tf=tf.abs(output_tf-label_tf)
return loss_tf,k_tf,b_tf
#直接使用函数minimize自动计算梯度并更新参数
def use_minimize(opt,loss_tf):
train_op=opt.minimize(loss_tf)
return train_op
#使用compute_gradients计算梯度并用apply_gradients更新参数
def use_compute_apply_gradients(opt,loss_tf):
#计算梯度
grads_and_vars=opt.compute_gradients(loss_tf)
#根据梯度和学习率更新参数,opt中保存有学习率
train_op=opt.apply_gradients(grads_and_vars)
return train_op
x_tf=tf.placeholder(shape=(),dtype=tf.float32,name='x')
y_tf=tf.placeholder(shape=(),dtype=tf.float32,name='y')
loss_tf,k_tf,b_tf=build_graph(x_tf,y_tf)
opt=tf.train.Optimizer.GradientDescentOptimizer(0.01)
#如果使用minimize函数就去掉下一行的注释
#train_op=use_minimize(opt,loss_tf)
train_op=use_compute_apply_gradients(opt,loss_tf)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(40000):
x,y=get_data()
_,k,b,loss=sess.run([train_op,k_tf,b_tf,loss_tf],feed_dict={x_tf:x,y_tf:y})
if i%2000==0:
print('step: ',i,', k=',k,', b=',b,', loss=',loss)
代码中,get_data()用于生成训练集;build_graph()用于构造网络结构;use_minimize()采用优化器的minimize函数来实现梯度计算与参数更新;use_compute_apply_gradients()采用优化器的compute
输出结果:
step: 0 , k=0.041346755 , b=0.01 , loss=27.994015
........................
step: 380000 , k=4.339712 , b=7.370074 , loss=6.6717224
从输出结果上看,参数k不断逼近5,参数b不断逼近7,但loss还没有完全收敛到0。注意原因是:学习率一直取0.01,并未随着训练的次数下降,使得loss在逼近0时步长过大,跨过了最优值;训练只有40000个step,还没有训练到最优。
6)TensorFlow中动态调整学习率:
在训练过程中为了提升训练精度,往往需要将学习率逐步下降。TensorFlow中,动态调整学习率的方法有很多种,常用有三种:
· 先在图外计算学习率,再通过feed_dict传入图中。定义tf.placeholder,在训练时根据循环的次数计算当前学习率,并通过feed_dict方式将学习率传入图中。
· 在图中计算学习率。在图中计算学习率就意味着计算学习率时,所有计算操作必须采用TensorFlow内置函数,对存放step的Tensor对象进行计算得到存放学习率的Tensor对象。
· 使用函数tf.train.exponential_decay。此函数用于动态调整学习率,使得学习率指数下降。
前两种方法比较简单,也容易理解。函数tf.train.exponential_decay的原型为:
tf.train.exponential_decay(
learning_rate,
global_step,
decay_steps,
decay_rate,
staircase=False,
name=None
)
各个参数的含义及数据类型:
· learning_rate:数据类型float64或float32的标量Tensor对象,或者是Python中的数值类型,表示初始的学习率。
· global_step:数据类型int32或int64的标量Tensor对象,或者是Python中的数值类型,表示Global Step,必须大于等于0。
· decay_steps:数据类型int32或int64的标量Tensor对象,或者是Python中的数值类型,表示下降的间隔Step。
· decay_rate:数据类型float64或float32的标量Tensor对象,或者是Python中的数值类型,表示初始的下降率。
· staircase:bool类型,若为True,表示每个区间段([0,decay_steps)、[decay_steps,2*decay _steps) ......)的学习率相同;反之,每个区间段的学习率以离散递减方式下降。
· name:字符串类型,表示当前Operation的名称。
函数tf.train.exponential_decay计算返回的学习率的公式:
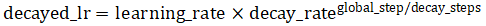
import tensorflow as tf
global_step=tf.placeholder(shape=(),name='global_step',dtype=tf.int64)
lr_1_tf=tf.train.exponential_decay(learning_rate=1e-1,global_step=global_step
lr_2_tf=tf.train.exponential_decay(learning_rate=1e-1,global_step=global_step
with tf.Session() as sess:
for i in range(40000):
lr_1,lr_2=sess.run([lr_1_tf,lr_2_tf],feed_dict={global_step:i})
if I/2000==0:
print('step=%5d, lr_1=%f, lr_2=%f'%(i,lr_1,lr_2))上面代码主要为了显示staircase不同设置的学习率的差别。然后将动态学习率加入训练代码中以提升训练精度,示例:
import tensorflow as tf
import random
# 数据集解析式逼近y=5x+7
def get_data():
x=random.randint(0,100)
y=5*x+7
#随机生成误差,误差取值为[-1,1]
x_noise=random.random()*2-1
y_noise=random.random()*2-1
return x+x_noise,y+y_noise
def build_graph(input_tf,label_tf):
k_tf=tf.Variable(0,name='k',dtype=tf.float32)
b_tf=tf.Variable(0,name='b',dtype=tf.float32)
output_tf=k_tf*input_tf+b_tf
loss_tf=tf.abs(output_tf-label_tf)
return loss_tf,k_tf,b_tf
global_step=tf.Variable(0,name='global_step',dtype=tf.float64)
x_tf=tf.placeholder(shape=(),dtype=tf.float32,name='x')
y_tf=tf.placeholder(shape=(),dtype=tf.float32,name='y')
loss_tf,k_tf,b_tf=build_graph(x_tf,y_tf)
#指数下降学习率
lr_tf=tf.train.exponential_decay(1e-1,global_step,decay_steps=10000
opt=tf.train.Optimizer.GradientDescentOptimizer(lr_tf)
train_op=opt.minimize(loss_tf,global_step=global_step)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(40000):
x,y=get_data()
_,k,b,loss=sess.run([train_op,k_tf,b_tf
if i%2000==0:
print('step: ',i,', k=',k,', b=',b,', loss=',loss)代码执行后显示:
step: 0 , k=8.241446 , b=0.1 , loss=417.2956
........................
step: 380000 , k=5.010882 , b=7.035273 , loss=2.9532776可见精度有明显提升。
2. 模型数据与参数名称映射:
在TensorFlow中,模型文件中的参数都有唯一对应的名称。如果定义的网络结构中某个参数名称在模型文件中不存在对应参数值,则无法加载模型到当前网络环境中。其实,对于参数名称与模型文件中名称不一致但对应参数shape是一致的情况,有其他方法可以加载参数。
1)通过名称映射加载:
如果模型文件中参数分别为k、b、m、n,但一个网络参数名不同,而为my_net/k、my_net/b、my_net/m、my_net/n,如果需要加载参数,方法示例:
import tensorflow as tf
def create_mode(x):
k=tf.Variable(0,name='my_net/k',dtype=tf.float32)
b=tf.Variable(0,name='my_net/b',dtype=tf.float32)
m=tf.Variable(0,name='my_net/m',dtype=tf.float32)
n=tf.Variable(0,name='my_net/n',dtype=tf.float32)
y=k*x+b
z=m*x*x+n*y*y
return z
def save_model(sess):
vars=tf.get_collecttion(tf.GraphKeys.TRAINABLE_VARIABLES)
vars_dict=dict()
for v in vars:
#将'my_net/k'截取字串k
key=''.join(v.name.split(':')[0:-1])
vars_dict[key[7:]]=v
saver=tf.train.Saver(var_list=vars_dict)
saver.restore(sess,'model/model-0')
input_tf=tf.placeholder(dtype=tf.float32)
output_tf=create_model(input_tf)
with tf.Session() as sess:
#加载所有参数k=2,b=3,m=4,n=5
sess.run(tf.global_variables_initialize())
load_model(sess)
output=sess.run(output_tf,feed_dict={input_tf:1})
print(output)
2)以pickle文件为中介加载模型:
将模型参数转为pickle文件,然后从pickle文件中加载参数赋值给网络中的Tensor对象,这种方法更通用。以pickle文件为中介加载模型分为两步,首先将模型参数保存为pickle文件,然后将pickle文件中存放的参数赋值给Tensor
①保存模型参数为pickle文件:
将所有训练参数保存到pickle文件时,对每一个参数对应变化后的名称与其参数值做映射,将每个映射关系存放在字典中,再将字典存储为pickle文件。示例:
import tensorflow as tf
import pickle
def create_mode(x):
k=tf.Variable(0,name='k',dtype=tf.float32)
b=tf.Variable(0,name='/b',dtype=tf.float32)
m=tf.Variable(0,name='m',dtype=tf.float32)
n=tf.Variable(0,name='n',dtype=tf.float32)
y=k*x+b
z=m*x*x+n*y*y
return z
def load_model(sess):
saver=tf.train.Saver()
saver.restore(sess.'model/model-0')
def save_to_pickle():
vars=tf.get_collecttion(tf.GraphKeys.TRAINABLE_VARIABLES)
model_dict=dict()
for v in vars:
#将'my_net/k'截取字串k
model_dict['my_net/'_v.name]=sess.graph
with open('model/model_dict.pickle','wb') as handle:
pickle.dump(model_dict,handle,protocol=pickle
input_tf=tf.placeholder(dtype=tf.float32)
output_tf=create_model(input_tf)
with tf.Session() as sess:)
load_model(sess)
save_to_pickle()
将模型保存到字典中,要将名称与Tensor对象的值做映射并保存到字典中,然后将字典保存为pickle文件。执行Session时,将参数从模型文件中读取,再将参数转存到pickle文件。
②从pickle文件中加载模型参数:
有了pickle文件后,也就有了当前网络中的参数名称及与其对应的Tensor对象的参数值,利用这种映射关系,为网络中的每个Tensor对象赋值。示例:
import tensorflow as tf
import pickle
def create_mode(x):
k=tf.Variable(0,name='my_net/k',dtype=tf.float32)
b=tf.Variable(0,name='my_net/b',dtype=tf.float32)
m=tf.Variable(0,name='my_net/m',dtype=tf.float32)
n=tf.Variable(0,name='my_net/n',dtype=tf.float32)
y=k*x+b
z=m*x*x+n*y*y
return z
def load_from_pickle(sess):
with open('model/model_dict.pickle','rb') as f:
weight_dict=pickle.load(f)
init_op,init_feed=tf.contrib.framework.assign_from_values(weight_dict)
sess.run(init_op,init_feed)
input_tf=tf.placeholder(dtype=tf.float32)
output_tf=create_model(input_tf)
with tf.Session() as sess:
load_from_pickle(sess)
load_model(sess)
output=sess.run(output_tf,feed_dict={input_tf:1})
print(output)
代码中,利用函数tf.contrib.framework.assign_from_values以字典中的映射关系为网络中的Tensor对象赋值。
3. 冻结指定参数:
冻结指定参数,是指在反向传播时指定参数不参与更新,只更新其他参数。冻结参数的主要应用场景是指训练号的模型的基础上,加入新的少量网络层,或者修改少量网络层参数的shape。冻结指定参数常用两种方式,一种是完全冻结,即指定参数不参与训练;另一种是不完全冻结,即以很小的学习率训练冻结参数,以较大的学习率训练其他参数。首先需要从模型中加载部分指定的参数。
1)从模型中加载部分参数:
从模型中加载部分参数,先通过tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES)获取所有的训练参数,再根据指定的参数名称获取指定的tf.Variable对象。示例:
import tensorflow as tf
def create_mode(x):
k=tf.Variable(0,name='my_net/k',dtype=tf.float32)
b=tf.Variable(0,name='my_net/b',dtype=tf.float32)
m=tf.Variable(0,name='my_net/m',dtype=tf.float32)
n=tf.Variable(0,name='my_net/n',dtype=tf.float32)
y=k*x+b
z=m*x*x+n*y*y
return z
def load_model(sess,var_names=None):
vars=tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES)
if var_names is not None:
vars=[v for v in vars if v.name in var_names]
saver=tf.train.Saver(var_list=vars)
saver.restore(sess.'model/model-0')
input_tf=tf.placeholder(dtype=tf.float32)
output_tf=create_model(input_tf)
with tf.Session() as sess:
#init variables:k=0,b=0,m=0,n=0
sess.run(tf.global_variables_initializer())
#load model:k=2,b=3,m=4,n=5
load_model(sess)
output=sess.run(output_tf,feed_dict={input_tf:1})
print(output)
#init variables:k=0,b=0,m=0,n=0
sess.run(tf.global_variables_initializer())
#load k,n from model:k=2,b=0,m=0,n=5
load_model(sess,var_names=['k:0','n:0'])
output2=sess.run(output_tf,feed_dict={input_tf:1})
print(output2)
2)指定网络层参数不参与更新:
假设示例的网络需要复用第一层,而第二层定义为z=m*x+n*y。第一层网络已经训练比较好,因此只加载第一层网络参数,并且只训练第二层网络参数m和n。示例:
import tensorflow as tf
import random
def get_data():
x=random.random()
y=2*x+3
z=40*x+50*y
#随机生成误差,误差取值为[-0.01,0.01]
x_noise=(random.random()-0.5)/50
z_noise=(random.random()-0.5)/50
return x+x_noise,z+z_noise
def load_model(sess,ckpt_path,var_names):
vars=tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES)
if var_names is not None:
vars=[v for v in vars if v.name in var_names]
saver=tf.train.Saver(var_list=vars)
saver.restore(sess,ckpt_path)
def build_graph(x,label_tf):
k=tf.Variable(0,name='k',dtype=tf.float32)
b=tf.Variable(0,name='b',dtype=tf.float32)
m=tf.Variable(0,name='m',dtype=tf.float32)
n=tf.Variable(0,name='n',dtype=tf.float32)
y=k*x+b
z=m*x+n*y
loss_tf=tf.abs(z-label_tf)
return loss_tf,m,n,k,b
global_step=tf.Variable(0,name='global_step',dtype=tf.float64)
x_tf=tf.placeholder(shape=(),dtype=tf.float32,name='x')
z_tf=tf.placeholder(shape=(),dtype=tf.float32,name='z')
loss_tf,m_tf,n_tf,k_tf,b_tf=build_graph(x_tf,z_tf)
lr_tf=tf.train.exponential_decay(0.1,global_step,decay_steps=30000,decay_rate=0.1)
vars=tf.get_collecttion(tf.GraphKeys.TRAINABLE_VARIABLES)
vars=[v for v in vars if v.name in ['m:0','n:0']]
opt=tf.train.Optimizer.GradientDescentOptimizer(lr_tf)
train_op=opt.minimize(loss_tf,global_step=global_step,var_list=vars)
with tf.Session() as sess:
#init variables:k=0,b=0,m=0,n=0
sess.run(tf.global_variables_initializer())
#load model:k=2,b=3,m=4,n=5
load_model(sess,'model/model-0',['k:0','b:0'])
for i in range(6000):
x,z=get_data()
_,m,n,loss=sess.run([train_op,m_tf,n_tf,loss_tf],feed_dict={x_tf:x,z_tf:z})
if i%1000==0:
print('step: ',i,', m=',m,', n=',n,', loss=',loss)
代码中加载模型参数时,只加载第一层网络参数k和b。代码运行结果:
step: 0 , m=0.0399576766 , n=0.37991536 , loss=204.84729
........................
step: 5000 , m=39.935276 , n=50.06158 , loss=1.7207489
可见,只训练第二层网络参数时,参数m和n很快趋近于收敛值。
3)两个学习率同时训练:
将冻结指定参数方式改为小学习率更新参数方式更合适,因为当网络结构发生变化时,未发生变化的网络层中的参数可能不再是最优的。将未发生变化的网络层用小学习率更新,发生变化的网络层用较大学习率更新,即采用两个学习率同时训练,这种方式比所有网络层从零开始训练收敛更快,可以节约训练时间。示例:
import tensorflow as tf
import random
#数据集解析式逼近y=2*x+3, z=40*x+50*y
def get_data():
x=random.random()
y=2*x+3
z=40*x+50*y
#随机生成误差,误差取值为[-0.01,0.01]
x_noise=(random.random()-0.5)/50
z_noise=(random.random()-0.5)/50
return x+x_noise,z+z_noise
def load_model(sess,ckpt_path,var_names):
vars=tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES)
if var_names is not None:
vars=[v for v in vars if v.name in var_names]
saver=tf.train.Saver(var_list=vars)
saver.restore(sess,ckpt_path)
def build_graph(x,label_tf):
k=tf.Variable(0,name='k',dtype=tf.float32)
b=tf.Variable(0,name='b',dtype=tf.float32)
m=tf.Variable(0,name='m',dtype=tf.float32)
n=tf.Variable(0,name='n',dtype=tf.float32)
y=k*x+b
z=m*x+n*y
loss_tf=tf.abs(z-label_tf)
return loss_tf,m,n,k,b
global_step=tf.Variable(0,name='global_step',dtype=tf.float64)
x_tf=tf.placeholder(shape=(),dtype=tf.float32,name='x')
z_tf=tf.placeholder(shape=(),dtype=tf.float32,name='z')
loss_tf,m_tf,n_tf,k_tf,b_tf=build_graph(x_tf,z_tf)
#大学习率
lr_2_tf=tf.train.exponential_decay(0.1,global_step,decay_steps=30000,decay_rate=0.1)
vars=tf.get_collecttion(tf.GraphKeys.TRAINABLE_VARIABLES)
#两层网络中的参数列表
vars_1=[v for v in vars if v.name in ['k:0','b:0']]
vars_2=[v for v in vars if v.name in ['m:0','n:0']]
#两个优化器
opt_1=tf.train.Optimizer.GradientDescentOptimizer(1e-6)
opt_2=tf.train.Optimizer.GradientDescentOptimizer(lr_2_tf)
train_1_op=opt_1.minimize(loss_tf,global_step=global_step,var_list=vars_1)
train_2_op=opt_2.minimize(loss_tf,global_step=global_step,var_list=vars_2)
#两个优化器操作合并成一个Operation对象
train_op=tf.group(train_1_op,train_2_op)
with tf.Session() as sess:
#init variables:k=0,b=0,m=0,n=0
sess.run(tf.global_variables_initializer())
#load model:k=2,b=3,m=4,n=5
load_model(sess,'model/model-0',['k:0','b:0'])
for i in range(20000):
x,z=get_data()
_,k,b,m,n,loss=sess.run([train_op,k_tf,b_tf,m_tf,n_tf,loss_tf],feed_dict={x_tf:x,z_tf:z})
if i%1000==0:
print('step: ',i,', k=',k,', b=',b,', m=',m,', n=',n,', loss=',loss)
代码执行后,输出结果:
step: 0 , k=2.0, b=3.0, m=0.02714306 , n=0.35428613 , loss=189.2953
........................
step: 19000 , k=2.021439, b=2.9882812, m=38.37232 , n=50.252296 , loss=1.2939911
4. TensorFlow中的命名空间:
神经网络中的网络节点少则几十个,多则上百个。为了更好地管理神经网络中的节点,TensorFlow中可以使用命名空间,利用命名空间可以将不同功能的节点放入到不同的命名空间下。
1)使用tf.variable_scope添加名称前缀:
类tf.variable_scope可对当前上下文所有变量和Operation对象的名称添加指定前缀,其中变量包括利用tf
__init__(
name_or_scope,
default_name=None,
values=None,
initializer=None,
regularizer=None,
catching_device=None,
partitioner=None,
custom_getter+None,
reuse=None,
dtype=None,
use_resource=None,
constraint=None,
auxiliary_name_scope=True
)
其中的常用参数含义及数据类型:
· name_or_scope:字符串类型或者是tf.variable_scope类型,如果是字符串类型,则表示当前tf.variable_scope对象的名称。
· default_name:指定当前tf.variable_scope对象的默认名称。如果name_or_scope值为None,则使用default
· initializer:指定当前命名空间中所有变量默认的初始化方法。
· regularizer:指定当前命名空间中所有变量默认的正则化方法。
· reuse:指定当前命名空间中所有变量的默认reuse属性。
· dtype:指定当前命名空间中所有变量的默认数据类型。
示例:
import tensorflow as tf
with tf.variable_scope("my_net"):
A=tf.get_variable(name="A",shape=(),dtype=tf.int32)
B=tf.Variable(2,name="B",,dtype=tf.int32)
C=tf.add(A,B)
print('A.name=',A.name)
print('B.name=',B.name)
print('C.name=',C.name)
print(tf.get_default_graph().get_operations())
代码中创建了tf.variable_scope对象,名称为“my_net”,在这个命名空间下,以三种方法创建Tensor对象,然后打印这些Tensor对象及Operation对象,前缀均以“my_net”开头。
A.name=my_net/A:0
B.name=my_net/B:0
C.name=my_net/Add:0
[<tf.Operation 'my_net/A/Initializer/zeros' type=Const>,
...................................................
<tf.Operation 'my_net/Add' type=Add>]
2)使用tf.name_scope添加名称前缀:
类tf.name_scope功能类型,用于对当前上下文环境中创建的部分Tensor对象和部分Operation对象的名称添加指定前缀,但只是一部分。
具体来说,对于使用tf.get_variable函数定义的变量Tensor对象名称中不会添加前缀,而使用tf.Variable类创建的变量Tensor对象名称中则会添加指定前缀。对于输出Tensor对象,是通过tf.get_variable函数定义的变量Tensor的Operation对象,其名称中不会添加前缀,而其他Operation对象则会添加指定前缀。tf.name_scope的构造函数:
__init__(
name,
default_name=None,
values=None
)
其中,name为当前命名空间的名称;default_name在参数name为None时起作用,即作为默认命名空间名称。示例:
import tensorflow as tf
with tf.name_scope("my_net"):
A=tf.get_variable(name="A",shape=(),dtype=tf.int32)
B=tf.Variable(2,name="B",,dtype=tf.int32)
C=tf.add(A,B)
print('A.name=',A.name)
print('B.name=',B.name)
print('C.name=',C.name)
print(tf.get_default_graph().get_operations())
代码中,只是使用tf.name_scope替代了前面代码的tf.variable_scope,输出中因为变量A使用tf.get_variable定义,因此名称前不加前缀,其他变量都加前缀“my_net”;而A相关的初始化、赋值、取值操作的Operation对象名称中不加前缀,而其他Operation对象的名称都会加“my_net”前缀。
3)tf.variable_scope与tf.name_scope的混合使用:
在一些复杂场景中,需要在不同的命名空间下使用共享变量,这时就需要搭配使用tf
import tensorflow as tf
with tf.variable_scope("my_net"):
with tf.name_scope("my_net1"):
A=tf.get_variable(name="A",shape=(),dtype=tf.float32)
B=tf.Variable(0,name="B",,dtype=tf.float32)
C=tf.add(A,B)
with tf.variable_scope("my_net",reuse=True):
with tf.name_scope("my_net2"):
D=tf.get_variable(name="A",shape=(),dtype=tf.float32)
E=tf.Variable(0,name="B",,dtype=tf.float32)
F=tf.add(D,E)
print('A.name=',A.name)
print('B.name=',B.name)
print('C.name=',C.name)
print('D.name=',D.name)
print('E.name=',E.name)
print('F.name=',F.name)
print('A==D?',A==D)
print('B==E?',B==E)
print('C==F?',C==F)
输出结果:
A.name=my_net/A:0
B.name=my_net/my_net1/B:0
C.name=my_net/my_net1/Add:0
D.name=my_net/A:0
E.name=my_net1/my_net2/B:0
F.name=my_net1/my_net2/Add:0
A==D? True
B==E? False
C==F? False
可见,以tf.get_variable函数创建或者获取的变量Tensor对象的名称只会受到tf.variable_scope的影响,而不受tf.name_scope的影响。而其他Tensor对象的名称则同时受到tf.name_scope和tf.variable_scope的影响。
5. TensorFlow多GPU训练:
在训练大模型时,尤其对输入为大图的网络进行训练时,由于单块GPU显存大小的限制,一次传入网络的Batch的取值往往很小。采用多GPU训练可以扩大Batch的取值,也加快模型训练速度,可以采用多GPU取梯度均值和较大学习率的方式实现提速。
1)多GPU训练读取数据:
在使用多GPU训练模型时,需要为TensorFlow指定使用哪些GPU。首先需要通过os.environ
import tensorflow as tf
import cv2
import numpy as np
import os
GPU_NUMS=2
os.environ['CUDA_VISIBLE_DEVICES']='0,2'
def get_data():
x=tf.tandom_uniform((),minval=-5,maxval=5)
y=2*x+3
#随机生成误差,误差取值为[-0.5,0.5]
x_noise=tf.random_uniform((),minval=0,maxval=1)-0.5
y_noise=tf.random_uniform((),minval=0,maxval=1)-0.5
return x+x_noise,y+y_noise
def main():
x_tf,y_tf=get_data()
data_queue=tf.contrib.slim.prefetch_queue.prefetch_queue([x_tf,y_tf]
xys_tf=[]
#multiGPU
with tf.variable_scope(tf.get_variable_scope()):
for i in range(GPU_NUMS):
with tf.device('/gpu:%d' % i):
with tf.name_scope('GPU_%d' % i) as scope:
#当前GPU执行出队操作
x,y=data_queue.dequeue()
xys_tf.append((x,y))
tf_config=tf.ConfigProto()
tf_config.gpu_options.allow_growth=True
tf_config.allow_soft_placement=True
with tf.Session(config=tf_config) as sess:
coord=tf.train.Coordinator()
threads=tf.train.start_queue_runners(coord=coord)
for i in range(10):
print('第%d次读取数据:',%i)
xys=sess.run(xys_tf)
for j in range(GPU_NUMS):
print('\t gpu-%d: '%j,xys[j])
coord.request_stop()
coord.join(threads)
main()
代码中定义了GPU卡的数量,指定第0号和第2号可用,其他则隐藏;后面生成训练数据集,生成队列,让不同GPU从队列中取数据。对TensorFlow来说,可用GPU会重新从0开始编号。输出结果:
第0次读取数据:
gpu-0: (-4.2343655, -5.666461)
gpu-1: (-4.062232, -4.624128)
.....................................
第9次读取数据:
gpu-0: (-3.4160669, -3.1376262)
gpu-1: (-2.4596185, -1.681697)
可见,如果有N块GPU可见并用于并行操作,那么通过tf.device(‘gpu:%d’ %i)中的i指定GPU时是从0到N-1进行编号。
2)平均梯度与参数更新:
使用多块GPU训练模型时,不同的GPU各自计算得到多个梯度,需要将所有GPU计算得到的梯度求平均值,再将平均值应用到所有参数中完成参数更新。实现实现多GPU并行计算梯度:
import tensorflow as tf
import cv2
import numpy as np
import os
GPU_NUMS=2
os.environ['CUDA_VISIBLE_DEVICES']='0,2'
def inference(x):
k=tf.get_variable(name='k',dtype=tf.float32,shape=(),initializer=tf.zeros.initializer)
b=tf.get_variable(name='b',dtype=tf.float32,shape=(),initializer=tf.zeros.initializer)
y=k*x+b
return y,k,b
def compute_loss(logits,labels):
loss_tf=tf.abs(logits-labels)
tf.add_to_collection('losses',loss_tf)
#每个GPU计算各自当前的loss
def tower_loss(scope,x_tf,y_tf):
logits,k,b=inference(x_tf)
compute_loss(logits,y_tf)
#只获取当前GPU对应的loss
losses=tf.get_collrction('losses',scope)
#计算当前GPU的loss之和
total_loss=tf.add_n(losses,name='total_loss')
return total_loss,k,b
def main():
global_step=tf.get_variable('global_step',[],initializer=tf.constant_initializer(0)
x_tf,y_tf=get_data()
data_queue=tf.contrib.slim.prefetch_queue.prefetch_queue([x_tf,y_tf],capacity
opt=tf.train.AdamOptimizer(0.01)
#用于存储每块GPU中的梯度
tower_grads=[]
#multiGPU
with tf.variable_scope(tf.get_variable_scope()):
for i in range(GPU_NUMS):
with tf.device('/gpu:%d' % i):
with tf.name_scope('GPU_%d' % i) as scope:
#当前GPU执行出队操作
x,y=data_queue.dequeue()
loss_tf,k_tf,b_tf=tower_loss(scope,x,y)
#针对get_variable函数,设置reuse为True
tf.get_variable_scope().reuse_variables()
#计算当前GPU的梯度
grads=opt.compute_gradients(loss_tf,trainable_variables())
tower_grads.append(grads)
#将所有GPU计算得到的梯度求平均值
grads=average_gradients(tower_grads)
#对共享变量使用平均梯度更新参数
apply_gradient_op=opr.apply_gradients(grads,global_step=global_step)
#对所有变量使用指数平滑算法更新
variables_averages=tf.train.ExponentialMovingAverage(0.999,global_step)
variables_averages_op=variable_averages.apply(tf.trainable_variables())
#将两个OP组合成一个OP
train_op=tf.group(apply_gradient_op,variables_averages_op)
tf_config=tf.ConfigProto()
tf_config.gpu_options.allow_growth=True
tf_config.allow_soft_placement=True
with tf.Session(config=tf_config) as sess:
sess.run(tf.grobal_variables_inirializer())
coord=tf.train.Coordinator()
threads=tf.train.start_queue_runners(coord=coord)
for i in range(1000):
_,loss,k,b=sess.run([train_op,loss_tf,k_tf,b_tf])
if i%100==0:
print('step=%d,loss=%f,k=%f,b=%f'%(i,loss,k,b))
coord.request_stop()
coord.join(threads)
main()
代码中先构建网络,根据网络输出结果及真实的Label数据计算loss,并将loss放入当前scope的名为losses的集合中,主要用于将不同GPU计算的loss放到不同的集合中,并在后面实现不同的GPU计算各自的loss。后面为不同的GPU指定并行执行任务,其中指定当前GPU计算loss,根据loss计算各个参数的梯度值,并将梯度值加入列表中。统计了每块GPU计算的梯度后,对每个变量参数在不同GPU中的梯度求对应的平均值,得到平均梯度后,执行应用梯度和学习率更新参数。为了使训练更加稳定,对变量加入指数平滑算法。其中用到的get_data()函数与前面一致,而计算平均梯度示例代码为:
#计算平均梯度
#参数tower_gradss是长度为GPU_NUMS的list对象
#其中tower_grads[i]为第1块GPU中保存的梯度list
#list中元素为(gradient,variable)元组
def average_gradients(tower_grads):
average_grads=[]
for grad_and_vars in zip(*tower_grads):
#grad_and_vars表示第1个变量及其梯度
#格式为((gpu0_grad_i,gpu0_var_i),(gpu1_grad_i,gpu1_var_i),...)
grads=[]
for g,_ in grad_and_vars:
#对所有GPU计算得到的梯度,在第0个位置添加维度并保存到列表
expanded_g=tf.expand_dims(g,0)
grads.append(expanded_g)
#对每个GPU中的梯度求平均值
grad=tf.concat(axis=0,values=grads)
grad=tf.reduce_mean(grad,0)
#由于所有变量共享,因此第1块GPU中传入的变量
#代表所有GPU指向的变量
v=grad_and_vars[0][1]
grad_and_var=(grad,v)
average_grads.append(grad_and_var)
return average_grads
代码执行后输出结果:
step=0, loss=3.856453, k=0.000000, b=0.000000
...........................................
step=900, loss=0.262995, k=1.893141, b=3.017826
八、TensorBoard可视化工具:
在模型训练过程中,可用借助TensorBoard可视化工具对误差值loss的变化曲线、学习率变化曲线、参数变量变化及图像中间结果等实现可视化监控能够。
1. 可视化静态图:
1)图结构系列化并写入文件:
TensorBoard工具对训练过程中的日志数据实现可视化的前提是生成系列化日志文件。TensorFlow中,类tf.
__init__(
logdir,
graph=None,
max_queue=10,
flush_secs=120,
graph_def=True,
filename_suffix=None,
session=None
)
各个参数含义及数据类型:
· logdir:字符串类型,指定系列化的日志文件的保存目录。
· graph:tf.Graph对象,指定关联的静态图对象。
· max_queue:整数类型,指定需要写入系列化文件的数据所在的等待队列的最大数量。
· flush_secs:数值类型,单位秒,指定将队列中数据写入磁盘文件中的间隔时间。
· graph_def:已废弃的参数,现用graph取代。
· filename_suffix:字符串类型,指定系列化文件名称的后缀。
· session:tf.Session对象,默认None。所有拥有相同session参数和logdir参数的FileWriter对象共享同一个系列化文件。
使用tf.summary.FileWriter类将网络写入系列化文件的示例:
import tensorflow as tf
input_tf=tf.placeholder(dtype=tf.float32,shape=(),name='input')
k=tf.Variable(0,name='k',dtype=tf.float32)
b=tf.Variable(0,name='b',dtype=tf.float32)
output_tf=k*input_tf+b
writer=tf.summary.FileWriter('./graph_logs',tf.get_default_graph())
代码中构建了网络结构output=k*input+b,即定义静态图,然后定义了tf.summary.FileWriter,系列化数据文件保存到graph_logs目录中,并指定当前默认图为其关联的静态图。代码执行后生成文件:
event.out.tfevents.nnnnnnnnnn.xxxxxx
生成文件的文件名后缀默认为当前计算机名,后缀前面的数值是当前时间戳,生成的系列化文件是经过编码的数据。
2)启动TensorBoard:
在安装TensorFlow框架时,会自动安装TensorBoard工具,如果Python环境没有安装,可以通过命令pip install tensorboard完成安装。TensorBoard库安装后,使用如下命令启动:
tensorboard --logdir=./graph_logs
其中,参数logdir为系列化日志文件所在目录。执行以上命令后,在控制台会输出:
TensorBoard 1.8.0 at http://xxxxxx:6006 (Press CTRL+C to quit)
在输出提示中,http://xxxxxx:6006为可视化TensorBoard的地址,其中xxxxxx为计算机名。复制这段URL地址并在浏览器中打开后,可以看到一个页面,显示了静态图结构。单击其中节点会显示相关属性。
使用命令tensorboard --logdir=./graph_logs启动TensorBoard时,默认端口是6006。如果该端口被其他程序占用,可以通过参数port为TensorBoard指定其他端口,命令为:
tensorboard --logdir=./graph_logs --port=6007
2. 图像显示:
TensorFlow所有写入文件的数据都是通过protocol buffer库系列化得到的,系列化后的数据保存到文件供TensorBoard库读取并显示。
1)系列化图像Tensor并写入文件:
函数tf.summary.image用于将图像Tensor对象系列化,系列化后的数据通过tf.summary. FileWriter对象的add_summary函数写入文件。函数tf.summary.image的原型:
tf.summary.image(
name,
tensor,
max_outputs=3,
collections=None,
family=None
)
各个参数的含义及数据类型:
· name:字符串类型,在TensorBoar中查看图像时,该图像会以name为显示的标题名称。
· tensor:四维Tensor对象,shape=[batch,height,width,channels]。存放图像数据的Tensor对象,通道数channels为1、3、4。
· max_outputs:整数类型,指定当前batch张图像中最多系列化的图像数量。
· collections:tf.GraphKeys列表中指定的集合名称,用于将返回的系列化后的Tensor对象加入指定集合中,默认tf.GraphKeys.SUMMARIES。
· family:字符串类型,用于将图像分类显示,所有相同的family图像会放入一个标签页中。
系列化图像时,如果输入Tensor对象的数据类型为uint8,则不会对其数据做任何处理;如果数据类型为浮点类型,则会将其数据标准化到[0,255]。标准化就是为图像中的数据同时乘以一个系数对数据的值放缩,系数的值分以下两种情况:
· 如果输入数据全是正数,设最大值为M,则系数为255.0/M。
· 如果输入数据中有负数,则通过偏移量将0变成127,即对图像中所有数据加127,然后再将最小值放缩到0,或最大值放缩到255。
系列化操作也是静态图中的一个节点,因此需要将系列化后的数据通过tf.Session的run函数取出,并通过tf.
add_summary(
summary,
global_step=None
)
其中参数summary即为系列化后的数据,global_step用于指定当前的global_step。示例:
import tensorflow as tf
def build_graph():
img_path_tf=tf.convert_to_tensor(['imgs/test.jpg'],dtype=tf.string)
[img_path_queue]=tf.train.slice_input_producer([img_path_tf])
img_data_tf=tf.read_file(img_path_queue)
img_tf=tf.image.decode_jpeg(img_data_tf,channels=3)
img_tf.expand_dims(img_tf,axis=0)
img_tf=tf.random_crop(img_tf,[1,160,160,3])
return img_tf
img_tf=build_graph()
#创建FileWriter对象
writer=tf.summary.FileWriter('./img_logs/single',tf.get_default_graph())
#图像系列化后的Tensor对象
serialized_img_tf=tf.summary.image('croped_img',img_tf,family="my_imgs")
with tf.Session() as sess:
coord=tf.train.Coordinator()
threads=tf.train.start_queue_runners(coord=coord)
for i in range(10):
img_str=sess.run(serialized_img_tf)
writer.add_summary(img_tf,global_step=i)
coord.request_stop()
coord.join(threads)
代码中将指定存放图像的Tensor对象执行系列化,并将系列化后的数据取出并写入文件。
如果需要系列化的图像Tensor对象有N个,需要在run函数中传入N个系列化后的Tensor对象,一旦N很大就会影响效率并容易出错。TensorFlow提供了将所有系列化后的Tensor对象合并到一个系列化数据的函数,包括tf
tf.summary.merge(
inputs,
collections=None,
name=None
)
各个参数的含义及数据类型:
· inputs:list类型,存放的是系列化后的Tensor对象。
· collections:list类型,默认[],存放的是集合名称,将存放当前合并后的系列化数据的Tensor对象放入到指定的集合中。
· name:字符串类型,表示当前Operation的名称。
函数tf.summary.merge_all可将指定集合中指定命名空间的系列化后的Tensor对象做合并,使用该函数可在任何地方执行图像系列化操作。函数原型:
tf.summary.merge_all(
key=tf.GraphKeys.SUMMARIES,
scope=None,
name=None
)
各个参数的含义及数据类型:
· key:集合名称指定需要合并的Tensor所在的集合。
· scope:字符串类型或者是Scope类型,表示命名空间,指定key集合中只有在scope命名空间中的Tensor对象才合并。
· name:字符串类型,表示当前Operation的名称。
使用函数tf.summary.merge_all合并系列化数据操作的示例:
import tensorflow as tf
def build_graph():
img_path_tf=tf.convert_to_tensor(['imgs/test.jpg'],dtype=tf.string)
[img_path_queue]=tf.train.slice_input_producer([img_path_tf])
img_data_tf=tf.read_file(img_path_queue)
img_tf=tf.image.decode_jpeg(img_data_tf,channels=3)
img_tf.expand_dims(img_tf,axis=0)
img_1_tf=tf.random_crop(img_tf,[1,200,200,3])
img_2_tf=tf.random_crop(img_tf,[1,160,160,3])
with tf.name_scope('my_scope'):
tf.summary.image('img_200*200',img_1_tf)
tf.summary.image('img_160*160',img_2_tf)
build_graph()
serialized_img_tf=tf.summary.merge_all(scope='my_scope')
#创建FileWriter对象
writer=tf.summary.FileWriter('./img_logs/merged',tf.get_default_graph())
with tf.Session() as sess:
coord=tf.train.Coordinator()
threads=tf.train.start_queue_runners(coord=coord)
for i in range(10):
img_str=sess.run(serialized_img_tf)
writer.add_summary(img_tf,global_step=i)
coord.request_stop()
coord.join(threads)
代码中分别生成宽高均为200和宽高均为160的两张图像,然后将这两个图像Tensor对象系列化,默认会将系列化后的Tensor对象放入集合tf.GraphKeys.SUMMARIES中。后面代码将集合tf.GraphKeys.SUMMARIES中所有在命名空间“my_scope”下的Tensor对象合并,以循环方式取出合并后的系列化数据并写入文件中。
2)用TensorBoard查看图像:
输入命令tensorflow --logdir=img_logs/single后,用浏览器打开TensorBoard显示。然后输入命令tensorflow --logdir=img_logs/merged后,用浏览器打开TensorBoard显示。导航栏中选中IMAGES类别后,可以看到所有写入系列化文件中的图像。在显示图像的界面左侧,包含一些图像处理相关操作,如调整显示图像的亮度、对比度等。
3. 标量曲线:
在训练模型时,需要将一些模型评价指标显示出来,如误差loss变化、学习率变化、模型精度变化等。TensorFlow中可以将标量以曲线方式在TensorBoard显示,这些显示曲线经过平滑算法计算后以相对比较稳定的曲线显示。
1)系列化标量Tensor并写入文件:
函数tf.summary.scalar用于将标量Tensor对象系列化,系列化后的数据通过tf.summary. FileWriter对象的add
tf.summary.scalar(
name,
tensor,
collections=None,
family=None
)
各个参数的含义及数据类型:
· name:字符串类型,在TensorBoard中查看曲线时,该曲线会以这里设置的name为显示的标题名称。
· tensor:只包含一个实数数据的Tensor对象。
· collections:tf.GraphKeys列表中指定的集合名称,用于将返回的系列化后的Tensor对象加入指定集合中,默认为tf.GraphKeys.SUMMARIES。
· family:字符串类型,用于将曲线分类显示。所有相同的family曲线会放入一个标签页中显示。
标量系列化到文件并在TensorBoard中显示的示例:
import tensorflow as tf
def get_noise(input):
input=tf.cast(input,dtype=tf.float32)
noise=tf.random_uniform((),minval=-10,maxval=10)
return input+noise
global_step=tf.placeholder(shape=(),dtype=tf.int32)
#模拟loss
loss_tf=100/get_noise(global_step)
#模拟accuracy
accuary_tf=tf.exp(-1/get_noise(global_step))
with tf.name_scope('my_scope') as scope:
tf.summary.scalar('accuary',accuary_tf)
merged_summary_tf=tf.summary.merge_all(scope=scope)
#创建FileWriter对象
writer=tf.summary.FileWriter('./scalar_logs',tf.get_default_graph())
with tf.Session() as sess:
for i in range(10000):
merged_summary=sess.run(merged_summary_tf,{global_step:i})
writer.add_summary(merged_summary,global_step=i)
代码中为指定数据添加噪点,生成模拟的误差loss数据和精度accuracy数据。代码执行后,会在目录“scalar_logs”中生成系列化后的数据。
2)用TensorBoard查看标量曲线:
输入命令tensorflowboard --logdir=scalar_logs后,用浏览器打开TensorBoard显示。在顶部导航栏中选中“SCALARS”类别,可以看到所有写入系列化文件中的标量曲线。在曲线界面左侧,包含对曲线平滑力度系数、水平坐标轴显示方式等操作选项。
4. 参数直方图:
参数直方图能够将Tensor对象的数据在训练过程中分布的变化过程以图的形式展现,并能将Tensor中每个区间的数据进行统计并以直方图的方式显示。
1)系列化参数Tensor并写入文件:
函数tf.summary.histogram用于将Tensor对象的分布统计数据系列化,系列化后的数据通过tf.summary.FileWriter对象的add_summary函数写入文件。函数tf.summary.histogram的原型:
tf.summary.histogram(
name,
values,
collections=None,
family=None
)
各个参数的含义及数据类型:
· name:字符串类型,在TensorBoard中查看数据分布时,该曲线会以这里设置的name为显示的标题名称。
· values:实数数值类型的Tensor对象,其shape可以为任意。
· collections:tf.GraphKeys列表中指定的集合名称,用于将返回的系列化后的Tensor对象加入指定集合中,默认为tf.GraphKeys.SUMMARIES。
· family:字符串类型,用于将曲线分类显示。所有相同的family曲线会放入一个标签页中显示。
将四维Tensor对象中的数据分布系列化到文件中并在TensorBoard中显示的示例:
import tensorflow as tf
def get_noise(input):
shape=input.get_shape().as_list()
noise=tf.random_normal(shape,0,10)
return input+noise
global_step=tf.placeholder(shape=(),dtype=tf.float32)
shape=[4,64,64,8]
input=tf.ones(shape)*global_step
input=get_noise(input)
histogram_tf=tf.summary.histogram('histogram',input)
#创建FileWriter对象
writer=tf.summary.FileWriter('./histogram_logs',tf.get_default_graph())
with tf.Session() as sess:
for i in range(100):
histogram=sess.run(histogram_tf,{global_step:i})
writer.add_summary(histogram,global_step=i)
代码中对四维Tensor对象添加正态分布随机噪点以模拟训练过程中模型参数数据分布,以循环方式不断将当前step的Tensor对象中的数据分布情况系列化并写入文件。执行代码,会在“histogram_logs”目录中生成系列化后的数据文件。
2)用TensorBoard查看参数直方图:
输入命令tensorboard --logdir=histogram_logs后,用于浏览器打开TensorBoard会显示直方图。在顶部导航栏中选中“HISTOGRAMS”类别后,可以看到所有写入系列化文件中的参数数据分布直方图。参数数据分布直方图是由多个“分布平面”构成的,每一个“分布平面”表示对应的Tensor对象中数据的分布情况,其中水平方向坐标轴表示值分布区间,垂直方向坐标轴表示当前step。
其中,step越大的“分布平面”越靠前,越小的step对应的“分布平面”越靠后。在界面的左侧包含对分布图显示模式进行切换的选项,默认是OFFSET模式。
可以切换为OVERLAY`显示模式,移动光标到指定的分布线时会显示该分布的对应的step、数据值及其对应的量值。其中水平方向坐标轴表示Tensor对象中的数值,垂直方向坐标轴表示Tensor对象具体数值对应的数量。
另外导航栏还有DISTRIBUTIONS选项,显示的也是数据分布,像数据分布的俯视图。默认水平方向坐标轴表示step,垂直方向坐标轴表示数据取值,水平方向坐标轴的含义可以在界面左侧切换。根据图中颜色深浅可以看出整体数据分布情况。
5. 文本显示:
在文字识别和语音识别相关网络模型训练时,模型输出一般是字符串类型数据。字符串数据也可以在TensorBoard中显示。
1)系列化文本Tensor并写入文件:
函数tf.summary.text用于将字符串类型Tensor对象系列化,系列化后数据通过tf.summary. FileWriter对象的add
tf.summary.text(
name,
tensor,
collections=None
)
各个参数的含义及数据类型:
· name:字符串类型,在TensorBoard中查看数据分布时,该曲线会以name为显示的标题名称。
· tensor:数据类型为字符串的Tensor对象。
· collections:tf.GraphKeys列表中指定的集合名称,用于将返回的系列化后的Tensor对象加入指定集合中,默认tf.GraphKeys.SUMMARIES。
将Tensor对象中的数据分布系列化到文件并在TensorBoard中显示的示例:
import tensorflow as tf
str_tf=tf.placeholder(shape=(),dtype=tf.string)
histogram_tf=tf.summary.text('string',str_tf)
#创建FileWriter对象
writer=tf.summary.FileWriter('./text_logs',tf.get_default_graph())
with tf.Session() as sess:
for i in range(10):
data="当前是第%d个Step"%i
histogram=sess.run(histogram_tf,{str_tf:data})
writer.add_summary(histogram,global_step=i)
代码中通过模拟产生字符串类型Tensor数据,经系列化写入文件,代码执行后在目录“text_logs”中生成系列化后的文件。
2)用TensorBoard查看文本:
输入命令tensorboard --logdir=text_logs后,用浏览器打开TensorBoard显示。在顶部导航栏中选中TEXT类别后,可以看到所有写入系列化文件中的文本。显示的每一项文本中,都包含该文本对应的step。
九、移植TensorFlow模型到Android端:
TensorFlow官方为Android编译了模型接口库,在Android端可轻松使用TensorFlow模型。移动端TensorFlow库分为TensorFlow Mobile和TensorFlow Lite,其中TensorFlow Lite是在TensorFlow Mobile基础上改进的,有更好的性能,但目前还存在一些不足,比如并不是所有TensorFlow中的计算函数都能执行。
示例中使用的一个卷积神经网络是MobileNetV2,用于64×64的中文识别,一个输入为64*64的image图像,两个输出分别为汉字分类索引class及对应的概率score,可以输出5个概率最高的结果。
1. 使用TensorFlow Mobile库:
使用TensorFlow Mobile库将TensorFlow模型移植到Android端的第一步是转换模型,使之能够被TensorFlow Mobile识别。完成模型转换后,使用TensorFlow Mobile提供的调用接口函数完成模型调用。
1)模型转换:
模型转换是先将模型参数加载到当前网络结构静态图中,再使用函数tf.graph_util
import tensorflow as tf
from nets.mobilenet import MobileNetV2
def inference(input_tf,n_classes):
net=MobileNetV2(n_classes=n_classes,depth_rate=1.0,is_training=False)
output=net.build_graph(input_tf)
output=tf.nn.softmax(output)
output=tf.nn.top_k(output,k=5,sorted=True)
return output
def main():
graph=tf.Graph()
with graph.as_default();
input_tf=tf.placeholder(shape=(1,64,64,3),dtype=tf.float32
classes_tf,scores_tf=tf.inference(input_tf,3755)
classes=tf.identity(classes_tf,name='classes')
scores=tf.identity(scores_tf,name='scores')
restore_saver=tf.train.Saver()
with tf.Session(graph=graph) as sess:
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
restore_saver.restore(sess,'datasets/model/model-80000')
#将图中的变量转为常量
output_graph_def=tf.graph_util.convert_variables_to_constants
#将新的图保存到datasets/model/out.pb文件中
tf.train.write_graph(output_graph_def,'datasets/model',"out.pb"
if __name__=='__main__':
main()
代码中,前面定义网络结构静态图,完成模型参数加载,并定义网络中的输入和输出;然后将当前图中的变量固化为常量,并写入指定路径的文件中保存。其中的输入名称input和输出名称classes、scores在模型调用时会用到。
2)模型调用:
在使用TensorFlow Mobile库之前,需要填写库的依赖,即在文件app/build.gradle的dependencies中添加:
dependencies{
...................................
compile 'org.tensorflow:tensorflow-android:+'
}
使用TensorFlow Mobile需要使用Android Studio 3.0以上版本。
接下来可以直接使用与TensorFlow Mobile库相关的接口函数,主要用到org.tensorflow
/**构造函数,从assets目录加载指定名称的模型pb文件**/
public TensorFlowInferenceInterface(AssetManager assetManager, String model){...}
/**构造函数,从输入流中加载模型数据**/
public TensorFlowInferenceInterface(InputStream is){...}
/**执行前向计算,计算节点为输入节点到指定的输出对象路径的所有节点**/
public void run(String[] outputNames){...}
/**将数据传入到输入节点中**/
public void feed(String inputName,int src,long...dims){...}
/**读取指定名称的Tensor对象,并将数据复制到Java数组的dst中**/
public void fetch(String outputName,float[] dst){...}
接下来可以调用模型。根据训练模型时的经验,Inference阶段基本步骤为:
· 加载模型参数,通过构造函数实现
· 输入数据传入输入节点,通过feed函数实现
· 执行网络模型,通过run函数实现
· 取出输出结果,通过fetch函数实现
示例代码:
package com.xxxxxx.cnr;
import android.content.res.AssetManager;
import android.graphics.Bitmap;
import android.graphics.Matrix;
import org.tensorflow.contrib.android.TensorFlowInferenceInterface;
import java.util.HashMap;
import java.util.Map;
public class RunModel{
private TensorFlowInferenceInterface inferenceInterface;
private String inputName;
private String[] outputNames;
private int inputHW
private int[] inputIntData;
private float[] inputFloatData;
public RunModel(String modelName,String inputName,String[] outputNames
this.inputName=inputName;
this.outputNames=outputNames;
this.inputWH=inputWH;
this.inputIntData=new int[inputWH*inputWH];
this.inputIFloatData=new float[inputWH*inputWH*3];
//从assets目录加载模型
inferenceInterface=new TensorFlowInferenceInterface(assetMngr
}
public Map
float[] inputData=getFloatImage(birmap);
//将输入数据复制到TensorFlow中
inferenceInterface.feed(inputName,inputData,1,inputWH
//执行模型
inferenceInterface.run(outputNames);
//将输出Tensor对象复制到指定数组中
int[] classes=new int[5];
float[] scores=new float32[5];
inferenceInterface.fetch(outputNames[0],classes)
inferenceInterface.fetch(outputNames[1],scores)
Map
results.put("classes",classes);
results.put("scores",scores);
return results;
}
//读取Bitmap像素值,并放入浮点数数组中
private float[] getFloatImage(Bitmap bitmap){
Bitmap bm=getResizedBitmap(bitmap,inputWH,inputWH);
bm.getPixels(inputIntData,0,bm.getWidth(),0,0,bm.getWidth()
for(int i=0;i
inputIntData[i*3+0]=(val>>16)&0xFF;
inputIntData[i*3+1]=(val>>8)&0xFF;
inputIntData[i*3+2]=val&0xFF;
}
return inputFloatData;
}
//对图像Resize
public Bitmap getResizedBitmap(Bitmap bm,int newWidth,int newHeight){
int width=bm.getWidth();
int height=bm.getHeight();
float scaleWidth=((float)newWidth)/width;
float scaleHeight=((float)newHeight)/Height;
Matrix matrix=new Matrix();
matrix.postScale(scaleWidth,scaleHeight);
Bitmap resizedBitmap=Bitmap,createBitmap(bm,0,0,width
bm.recycle();
return resizedBitmap
}
}
构造函数中,创建整数类型输入数据缓存数组inputIntData、浮点类型输入数据缓存数组,从assets目录加载指定模型pb文件;然后将图像传入模型输入节点,并返回模型输出。将图像中的数据存入浮点类型数组缓存,将浮点类型数组通过feed函数传入网络,执行从输入到输出路径中所有节点的计算,通过fetch将数据取出。
3)模型测试:
将汉字字符与索引值映射关系文件char_list.txt存放到assets目录中,定义Activity,其中实现加载映射文件、撤销和清空调用入口、监听手写笔画并将回调的Bitmap对象传入RunModel对象中调用模型及在界面中显示识别结果。
2. 使用TensorFlow Lite库:
TensorFlow Lite是TensorFlow官方推荐使用的库,对应的二进制模型文件更小,并有更好的性能。
1)模型转换:
TensorFlow Mobile库中使用的模型文件并不能在TensorFlow Lite库中使用,也需要进行模型转换。示例:
import tensorflow as tf
from nets.mobilenet import MobileNetV2
lite=tf.contrib.lite
def inference(input_tf,n_classes):
net=MobileNetV2(n_classes=n_classes,depth_rate=1.0,is_training=False)
output=net.build_graph(input_tf)
output=tf.nn.softmax(output)
output=tf.nn.top_k(output,k=5,sorted=True)
return output.indices,output.values
def main():
input_tf=tf.placeholder(shape=(1,64,64,3),dtype=tf.float32,name='input')
classes_tf,scores_tf=tf.inference(input_tf,3755)
classes=tf.identity(classes_tf,name='classes')
scores=tf.identity(scores_tf,name='scores')
restore_saver=tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
restore_saver.restore(sess,'datasets/model/model-80000')
#将图中的变量转为常量
converter=lite.TocoConverter.from_session(sess,[input_tf]
tflite_model=converter.convert()
open('model/hw_model.tflite','wb').write(tflite_model)
if __name__=='__main__':
main()
代码中先定义网络结构静态图,加载模型参数到当前网络静态图中,定义模型转换对象,指定模型的输入节点和输出节点,执行模型转换。代码执行后,目录model中会生成文件hw_ model.tflite。
2)模型调用:
使用TensorFlow Lite库之前,需要填写库依赖,并且指定模型不被压缩。要在文件app/build. gradle的android模块和dependencies模块中添加:
android{
.................................
aaptOptions{
noCompress "tflite"
}
}
dependencies{
...................................
compile 'org.tensorflow:tensorflow-lite:0.0.0-nightly'
}
使用TensorFlow Lite时需要使用Android Studio 3.0以上版本。
接下来可以直接使用与库相关的接口函数,主要用到TensorFlow Lite库中的org.tensorflow. Lite.Interpreter类对象,其中常用函数有:
//构造函数,参数modelFile对应模型文件的File对象
public Interpreter(@NonNull File modelFile){...}
//构造函数,参数modelFile对应模型文件的File对象
public Interpreter(@NonNull File modelFile,Options options){...}
//构造函数,参数byteBuffer为存放模型数据的ByteBuffer对象
public Interpreter(@NonNull ByteBuffer byteBuffer){...}
//构造函数,参数byteBuffer为存放模型数据的ByteBuffer对象
public Interpreter(@NonNull ByteBuffer byteBuffer,Options options){...}
//执行模型,只能是一个输入节点一个输出节点
//input是数组类型或ByteBuffer类型,数组类型可以为int、float、long、byte等
//output是数组类型或ByteBuffer类型,数组类型可以为int、float、long、byte等
public void run(@NonNull Object input,@NonNull Object output){...}
//执行模型,可以是多个输入节点多个输出节点
//inputs是数组类型或ByteBuffer类型,数组类型可以为int、float、long、byte等
//outputs为map类型,key为索引值,value为数组类型或ByteBuffer类型
public void runForMultipleInputsOutputs(@NonNull Object[] inputs
//对模型中第idx个输入做resize操作
public void resizeInput(int idx,@NonNull int[] dims){...}
//获取输入节点的数量
public int getInputTensorCount(){...}
//获取指定名称的输入节点在模型输入中的索引值
public int getInputIndex(String opName){...}
//返回指定索引的输入节点对象(Tensor对象)
public Tensor getInputTensor(int inputIndex){...}
//获取输出节点的数量
public int getOutputTensorCount(){...}
//获取指定名称的输出节点在模型输出中的索引值
public int getOutputIndex(String opName){...}
//获取指定索引的输出节点对象(Tensor对象)
public Tensor getOutputTensor(int outputIndex){...}
在使用Interpreter的run和runForMultipleInputsOutputs函数时,使用ByteBuffer类型的输入数据执行速度比数组类型更快。
下面调用TensorFlow Lite模型,使用Interpreter调用模型的基本步骤:
· 加载模型参数,通过Interpreter类构造函数实现。
· 执行网络模型,并传入输入数据和输出拷贝空间,通过函数run或runForMultipleInputs Outputs实现。
示例:
package com.xxxxxx.cnr;
//import ......
public class RunLiteModel{
private String inputName;
private String[] outputNames;
private int inputHW
private int[] inputIntData;
private float[] inputFloatData;
//定义Interpreter的配置选项Options对象
private final Interpreter.Options tfliteOptions=new Interpreter.Options();
//加载TensorFlow Lite模型
private MappedByteBuffer tfliteModel;
//定义Interpreter对象,用于执行TensorFlow Lite模型
protected Interpreter tflite;
//定义ByteBuffer对象,用于存放图片数据,并传入TensorFlow Lite模型输入节点
protected ByteBuffer imgData=null;
//定义数组对象,用于存放TensorFlow Lite输出结果
private int[][] classes=null;
private float[][] scores=null;
public RunLiteModel(String modelName,String inputName,String[] outputNames
this.inputName=inputName;
this.outputNames=outputNames;
this.inputWH=inputWH;
this.inputIntData=new int[inputWH*inputWH];
this.inputIFloatData=new float[inputWH*inputWH*3];
//从assets目录加载模型
tfliteModel=loadModelFile(assetMngr,modelName)
tflite=new Interpreter(tfliteModel,tfliteOptions);
//height*width*sizeof(float)*channel
imgData=ByteBuffer.allocateDirect*inputWH*inputWH*4*3);
imgData.order(ByteOrder,nativeOrder());
classes=new int[1][5];
scores=new float[1][5];
}
public Map
convertBitmapToByteBuffer(bitmap);
//如果只有一个输入一个输出,使用下面函数
//tflite.run(imgData,classes);
//示例有两个输出要使用runForMultipleInputsOutputs
Map
outputs.put(0,classes);
outputs.put(1,scores);
tflite.runForMultipleInputsOutputs(new Object[]{imgData}
Map
results.put("classes",classes[0]);
results.put("scores",scores[0]);
return results;
}
//将图片数据写入ByteBuffer对象中
private void convertBitmapToByteBuffer(Bitmap bitmap){
Bitmap bm=getResizedBitmap(bitmap,inputWH,inputWH);
if(imgData==null){
return;
}
imgData.rewind();
bm.getPixels(inputIntData,0,bm.getWidth(),0,0,bm.getWidth()
//将图片数据转为浮点型
int pixel=0;
for(int i=0;i<inputWH;++i){
for(int j=0;j<inputWH;++j){
final int val=inputIntData[pixel++];
imgData.putFloat((val>>16) & 0xFF);
imgData.putFloat((val>>8) & 0xFF);
imgData.putFloat(val & 0xFF);
}
}
}
//从assets目录读取TensorFlow Lite模型
private MappedByteBuffer loadModelFile(AssetManager assetMngr,String modelName){
try{
AssetFileDescriptor fileDescriptor=assetMngr.openFd(modelName);
FileInputStream inputStream=new FileInputStream
FileChannel fileChannel=inputStream.getChannel();
long startOffset=fileDescriptor.getStartOffset();
long declaredLength=fileDescriptor.getDeclaredLength();
return fileChannel.map(FileChannel.MapMode
}catch(Exception e){
e.printStackTrace();
}
return null;
}
//对图像Resize
public Bitmap getResizedBitmap(Bitmap bm,int newWidth,int newHeight){
int width=bm.getWidth();
int height=bm.getHeight();
float scaleWidth=((float)newWidth)/width;
float scaleHeight=((float)newHeight)/Height;
Matrix matrix=new Matrix();
matrix.postScale(scaleWidth,scaleHeight);
Bitmap resizedBitmap=Bitmap,createBitmap(bm,0,0,width
bm.recycle();
return resizedBitmap
}
}
代码中,构造函数用于指定模型的输入和输出名称、加载模型参数数据并初始化Interpreter对象及分配输入和输出数据存储空间。后面将模型调用接口封装,将传入的Birmap转为ByteBuffer对象,并执行runFor
3)模型测试:
将汉字字符与索引值映射关系文件char_list.txt存放assets目录中,在MainActivity类中实现加载char_list.txt文件、撤销和清空按钮调用入口、监听手写笔画并将回调的Birmap对象传入RunLiteModel对象中调用模型及在界面中显示识别结果。