编程语言
C#编程语言基础
C#面向对象与多线程
C#数据及文件操作
JavaScript基础
JavaScript的数据类型和变量
JavaScript的运算符和表达式
JavaScript的基本流程控制
JavaScript的函数
JavaScript对象编程
JavaScript内置对象和方法
JavaScript的浏览器对象和方法
JavaScript访问HTML DOM对象
JavaScript事件驱动编程
JavaScript与CSS样式表
Ajax与PHP
ECMAScript6的新特性
Vue.js前端开发
PHP的常量与变量
PHP的数据类型与转换
PHP的运算符和优先规则
PHP程序的流程控制语句
PHP的数组操作及函数
PHP的字符串处理与函数
PHP自定义函数
PHP的常用系统函数
PHP的图像处理函数
PHP类编程
PHP的DataTime类
PHP处理XML和JSON
PHP的正则表达式
PHP文件和目录处理
PHP表单处理
PHP处理Cookie和Session
PHP文件上传和下载
PHP加密技术
PHP的Socket编程
PHP国际化编码
MySQL数据库基础
MySQL数据库函数
MySQL数据库账户管理
MySQL数据库基本操作
MySQL数据查询
MySQL存储过程和存储函数
MySQL事务处理和触发器
PHP操作MySQL数据库
数据库抽象层PDO
Smarty模板
ThinkPHP框架
Python语言基础
Python语言结构与控制
Python的函数和模块
Python的复合数据类型
Python面向对象编程
Python的文件操作
Python的异常处理
Python的绘图模块
Python的NumPy模块
Python的SciPy模块
Python的SymPy模块
Python的数据处理
Python操作数据库
Python网络编程
Python图像处理
Python机器学习
TensorFlow深度学习
Tensorflow常用函数
TensorFlow用于卷积网络
生成对抗网络GAN
一、生成对抗网络基础:
生成对抗网络GAN是Generative Adversatial Network的缩写。GAN网络由两个主要网络构成,一个Generator Network,称为生成网络或生成器,另一个是Discriminator Network,称为判别网络或判别器。生成器与判别器相互对抗,互相博弈。
GAN常见的用途是生成非常真实的图像,可以为训练其他类型神经网络提供数据源,某些改良后的GAN可以生成超高清图像;GAN还可以用于声音领域,如将一个人的声音变成另外一个人的声音还可以用来去除噪声,让音源更加纯净。视频领域,GAN可以生成预测视频中下一帧的画面。
1. GAN基本原理:
下面是GAN的简易模型:
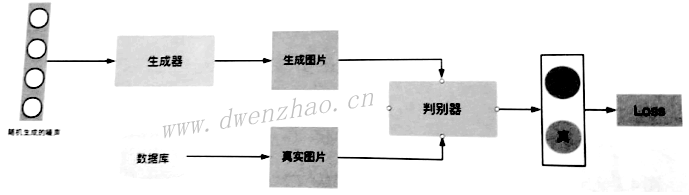
GAN的训练一开始是训练判别器的,目的就是让判别器获得一个标准,让判别器看一堆好图像,从而让其知道好图是什么样。训练完判别器后再来训练生成器,随便生成一组噪声给生成器,生成器会通过这种噪声生成一张图像。
生成图像后,判别器会判断这张图像是来自于数据库的真实图像,还是来自于生成器的生成图像,如果判断是真实图像就会给图像一个较高分数,如果判断是生成图像就赋予一个较低分数,同时产生一个损失。这个损失是生成图像与真实图像的差距,就是在高维空间中生成图像的概率分布与真实图像概率分布的不同之处,具体就是两个概率分布的JS散度。而优化损失就是最小化生成图像的概率分布与真实图像的概率分布的JS散度。
其实判别器也有损失,由两部分构成,一是判别器给真实图像赋予的分数与目标分数1的差距,二是判别器给生成图像赋予的分数与目标分数的差距。真实图像的概率分布一开始是未知的,通过判别器去学习,从而获得一个标准。
要训练出一个可用的GAN,一般都会反复训练多次,大致训练流程:
①初始化生成器和判别器,参数随机生成即可
②在每一轮训练中,执行如下步骤:
⑴固定生成器参数,训练判别器参数:因生成器参数没有收敛,生成的图像就不会太真实;从准备好的图像数据库中选择一组真实图像数据;通过这两组数据训练判别器,让其对真实图像赋予高分,而给生成图像赋予低分。
⑵固定判别器,训练生成器:随机生成一组噪声给生成器,使其生成一张图像;将生成的图像传入判别器,判别器会给该图像一个分数,生成器的目标就是使这个分数更高,生成出判别器可用赋予高分的图像。
随着GAN训练次数的增加,为了生成出让判别器赋予高分的数据,生成器生成数据的分布渐渐向真实数据的分布靠拢;当生成器学习到真实数据的分布情况时,判别器就无法区分生成数据和真实数据,都赋予相同的分数。
2. TensorFlow实现朴素GAN:
这里使用一个最简单的GAN,训练这个GAN,使它可以生成与真实图像一样的手写数字图像MNIST数据集。
import tensorflow as tf
import numpy as np
import pickle
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
# 读入MNIST数据
mnist=input_data.read_data_sets('./data/MNIST_data')
img=mnist.train.images[500]
# 以灰度图的形式读入
plt.imshow(img.reshape((28,28)),cmap='Greys_r')
plt.show()
print(type(img))
print(img.shape)
前面这部分先导入第三方库,读入MNIST中的第500个数据,显示出来。TensorFlow在1.9版本后,使用input_data.read_data_sets时不会自动下载,需要事先下载好。
def get_inputs(real_size,noise_size):
real_img=tf.placeholder(tf.float32,[None,real_size],name='real_img')
noise_img=tf.placeholder(tf.float32,[None,noise_size],name='noise_img')
return real_img,noise_img
接收输入,只是用占位符来获得输入数据。
def generator(noise_img,n_units,out_dim,reuse=False,alpha=0.01):
'''
生成器
:param-noise_img:生成器生成的噪声图像
:param-n_units:隐藏层单元数
:param-out_dim:输出的tensor的size,应为32×32=784
:param-reuse:是否重用空间
:param-alpha:leakeyReLU系数
'''
with tf.variable_scope("generator",reuse=reuse):
# 全连接
hidden1=tf.layers.dense(noise_img,n_units)
# 返回最大值
hidden1=tf.maximum(alpha*hidden1,hidden1)
hidden1=tf.layers.dropoute(hidden1,rate=0.2,training=True)
# dense: 全连接
logits=tf.layers.dense(hidden1,out_dim)
output=tf.tanh(logits)
return logits,outputs
上面的生成器网络结构很简单,输入层-隐藏层-输出层,只有一个隐藏层。其中,使用tf. variable_scope创建了名为generator的空间,在空间内变量可以被重复使用并方便区分不同卷积层之间的组件。这里使用Tanh激活函数输出,但其输出范围-1~1,表示其生成图像像素范围为-1~1,但MNIST数据集中像素范围0~1,训练时需要调整真实图像像素范围,让其与生成图像一致。
def discirminator(img,n_units,reuse=False,alpha=0.01):
'''
判别器
'''
with tf.variable_scope('discirminator',reuse=reuse):
# 全连接
hidden1=tf.layers.dense(noise_img,n_units)
# 返回最大值
hidden1=tf.maximum(alpha*hidden1,hidden1)
hidden1=tf.layers.dropoute(hidden1,rate=0.2,training=True)
# dense: 全连接
logits=tf.layers.dense(hidden1,1)
output=tf.sigmoid(logits)
return logits,outputs
判别器代码与生成器差别不大,不同的是输出层只有一个网络单元,且使用sigmoid作为输出层激活函数,输出范围0~1。
img_size=mnist.train.images[0].shape[0]
noise_size=100
g_units=128 #生成器隐藏层参数
d_units=128
alpha=0.01
learning_rate=0.001
smooth=0.1 # 标签平滑
# 重置default graph计算图以及nodes节点
tf.reset_default_graph()
上面是初始化
```python
# 生成器
g_logits,g_outputs=generator(noise_img,g_units,img_size)
# 判别器
d_logits_real,d_outputs_real=generator(real_img,d_units)
# 传入生成图像,为其打分
d_logits_fake,d_outputs_fake=generator(gl_outputs,d_units,reuse=True)
```
上面代码将噪声、生成器隐藏节点数、真实图像大小传入生成器;先传真实图像到判别器,为真实图打分,接着再用相同的参数训练生成图像,为生成图像打分。
d_loss_real=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits
d_loss_fake=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits
# 判别总损失
d_loss=tf.add(d_loss_rel,d_loss_fake)
g_loss=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake
计算损失时使用sigmoid_cross_entropy_with_logits方法,它对传入的logits参数先使用sigmoid函数计算,然后再计算它们的交叉熵损失cross entropy。
# generator中的tensor
g_vars=[var for var in train_vars if var.name.strartswith("generator")]
# discirminator中的tensor
d_vars=[var for var in train_vars if var.name.strartswith("discriminator")]
#AdamOptimizer优化损失
d_train_opt=tf.train.AdamOptimizer(learning_rate).minimize(d_loss,var_list=d_vars)
g_train_opt=tf.train.AdamOptimizer(learning_rate).minimize(g_loss,var_list=g_vars)
先获取生成器及判别器中的变量,最小化损失时需要修改这些对象;使用AdamOptimizer方法最小化损失。
batch_size=64 # 每一轮训练数
epoche=500 # 训练迭代轮数
n_sample=25 # 抽样数
samples=[] # 存储测试样例
losses=[] # 存储loss
# 保存生成器变量
saver=tf.train.Saver(var_list=g_vars)
上面是训练相关参数,下面是训练代码:
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for e in range(epochs):
for batch_i in range(mnist.train.num_examples//batch_size):
batch=mnist.train.next_batch(batch_size)
#28x28=784
batch_images=batch[0].reshape((batch_size,784))
#对图像像素进行scale,使real与fake对齐
batch_images=batch_images*2-1
#生成噪声图像
batch_noise=np.random.uniform(-1,1,size=(batch_size
#先训练判别器,再训练生成器
_=sess.run(d_train_opt,feed_dict={real_img:batch_images
_=sess.run(g_train_opt,feed_dict={noise_img:batch_noise}))
#每一轮训练完成后都计算loss
train_loss_d=sess.run(d_loss,feed_dict={real_img:batch_images
# 判别器训练时真实图像的损失
train_loss_d_real=sess.run(d_loss_real,feed_dict={real_img:batch_images
# 判别器训练时生成图像的损失
train_loss_d_fake=sess.run(d_loss_fake,feed_dict={real_img:batch_images
# 生成器损失
train_loss_g=sess.run(g_loss,feed_dict={noise_img:batch_noise})
print("训练轮数{}/{}...".format(e+1,epoche), "判别器总损失:{:.4f}
# 记录各类loss值
losses.append((train_loss_d,train_loss_d_real,train_loss_d_fake,train_loss_g))
# 抽取样本后期进行观察
sample_noise=np.random.uniform(-1,1,size=(n_sample,noise_size))
#生成样本,保存起来后期观察
gen_samples=sess.run(generator(noide_img,g_units,img_size,reuse=True)
samples.append(gen_samples)
# 存储checkpoints
saver.save(sess.'./data/generator.ckpt')
with open('./data/train_samples.pkl','wb') as f:
pickle.dump(samples,f)
一般是将真实图像分成多组,然后进行多轮训练,这辆4张为一组。
训练完成,可视化结果:
figfig,axax=plt.subplots(figsize(20,7))
losses=np.array(losses)
plt.plot(losses.T[0],label='Discriminator Total Loss')
plt.plot(losses.T[1],label='Discriminator Real Loss')
plt.plot(losses.T[2],label='Discriminator Fake Loss')
plt.plot(losses.T[3],label='Generator Loss')
plt.title("Training Losses")
plt.legend()
将生成器最后一轮训练时的数据可视化:
with open('./data/train_samples.pkl','rb') as f:
sanples=pickle.load(f)
def view_img(epoch,samples):
fig,axes=plt.subplots(figsize=(7,7),nrows=5,ncols=5,sharex=True,sharey=True)
for ax,img in zip(axes.flatten(),samples[epoch][1]):
ax.xaxis.set_visible(False)
ax.yaxis.set_visible(False)
im=ax.imshow(img.reshape((28,28)),cmap="Greys_r")
plt.show()
view_img(-1,samples)
如果从开始开始看生成图像,一开始只会生成噪声图像,随着训练次数的增加,生成器生成的图像越来越真实。
3. 生成对抗网络的数学原理:
GAN的一个重要应用就是生成逼真的图像。
1)最大似然估计:
最大似然估计MLE(Maximum Likelihood Estimation)是一种利用已知信息,反向推导出最有可能产生这些信息的模型参数的方法。
使用最大似然分布估计,要求其中的每个事件都是独立分布的。假设x1,x2,...,xn事件是独立分布的,有个未知参数θ的模型产生了这些事件,模型产生这些事件的概率可以表示为:
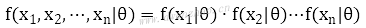
如果想求出模型参数θ,使用最大似然估计来求解,就是通过x1,x2,...,xn事件反推最有可能产生这些事件的模型参数。表达式:
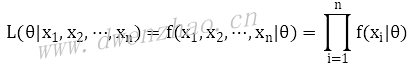
这表示,一个模型在一个参数θ下产生了事件x1,x2,...,xn,那么就可以通过这些已知的事件来求解未知模型参数θ。
为了简化运算,可对公式两边取对数,,变换后公式:
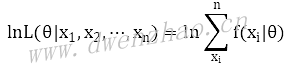
取对数后称为对数似然,做除法,可以得到平均对数似然:
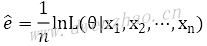
最大似然估计计算出来的模型参数并不一定是真实的模型,可能因为抽样样本比较少,导致算出来的结果与真实情况差距很大。这只是一种认为当前已有数据参数了,就认为模型最有可能产生这些数据。当抽样样本越来越多时,最大似然估计获得的结果才会越来越准确。
最大似然的严谨数学定义为,给定数据集X=x1,x2,...,xn,一个待拟合的分布族pθ(X),求θ^使得似然L(θ|X)=logpθ(X)最大。
在最大似然问题中,pθ(X)如果是指数分布族,则满足指数分布族的概率密度函数:
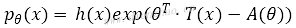
其中,x表示该分布函数的自变量,θ表示一个参数向量,T(x)表示充分统计量,A(θ)表示配分函数且为凸函数。将pθ(X)代入最大似然公式,得到:
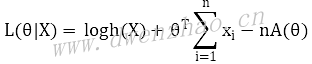
其中:
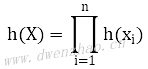
这是一个常数,A(θ)是一个凸函数,则-A(θ)是凹函数。求和之后获得的L(θ|X)也是凹函数,对凹函数求导为0,可以获得唯一的极大值。
一般而言,凸函数是向下凸的,形状像向下凹陷的碗;凹函数是向上凹,形状像个山丘。所以对凹函数求极值,获得最大值;对凸函数求极值,获得极小值。
在GAN中,要实现图像生成,简单原理就是想让生成器学会真实图像在高维空间的分布。假设真实图像在高维空间的分布为Pdata(x),但无法准确知道,可以定义一个模型PG(x;θ),通过训练方式计算出一个θ来最小化PG(x;θ)分布与真实图像分布Pdata(x)之间的差异。
为此,首先从Pdata(x)中抽取一些样本,x1,x2,...,xn,如果从PG(x;θ)中也抽取出了同样的样本,就说明PG(x;θ)与真实图像分布Pdata(x)是相同或相似的。那么要计算出PG(x;θ)中的θ,就是利用最大似然:
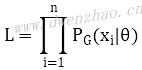
利用从真实分布Pdata(x)抽取出来的样本来计算PG(x;θ),希望找到一个θ,让PG(x;θ)最有可能生成同样的样本。表达式:

通过推导,这与KL散度形式一致:
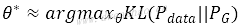
本质就是最小化真实分布Pdata与生成分布PG的相对熵。
2)GAN生成器拟合分布:
神经网络可以拟合任意分布,GAN的方法就是使用生成器这个复杂的神经网络把输入的数据拟合成需要的数据分布。对生成器而言,其目标函数:
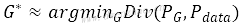
即最小化生成分布PG与真实分布Pdata之间的距离Div(PG,Pdata)。
因为无法准确知道生成分布PG与真实分布Pdata的情况,所以使用采样方式,即从数据集中抽取一个样本,将抽取的样本的分布看成是PG与Pdata的分布,使用的思想是大数定理。知道了这两个分布,就可以通过训练生成器来最小化两分布之间的距离。
生成器可以最小化生成分布PG与真实Pdata之间的距离,而判别器则用来定义这两个分布的距离。判别器的目标函数:
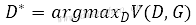
训练判别器就像训练一个二元分类器,其实质是可以识别出真实数据与生成数据。一开始生成器还不能生成与真实图像接近的图像,此时判别器做二分类就可以轻易识别出输入数据是真实数据还是生成数据,两种分布之间的距离较大;随着训练加多,生成数据与真实数据的分布会越来越接近,此时判别器无法将生成数据与真实数据完全区分,两分布之间的距离较小。
经过推导证明,生成器最小化GAN目标函数就是最小化真实分布与生成分布之间的JS散度,也即最小化两个分布的相对熵。GAN的工作就是通过判别器找到当前生成分布与真实分布的JS散度,然后再通过生成器生成数据构成新的生成分布,从而减小生成分布与真实分布之间的JS散度。GAN训练的过程:
· 固定生成器G,训练判别器D,获得maxDV(G,D)
· 固定判别器D,对maxDV(G,D)做微分,从而计算出生成器参数要更新的值:
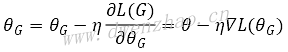
· 往返上面两步,直到GAN收敛。
3)其他定义两种分布差异的方式:
①f散度:
通常使用JS散度来定义生成分布与真实分布之间的差异,训练生成器的本质就是减小两分布的JS散度的过程。
对一个函数f,公式:
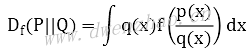
当函数f满足下面两个条件,就可以使用Df(P||Q)来简单地衡量两种概率分布之间的差异。
· f函数是一个凸函数
· f(1)=0
可以将f函数写成不同的形式。将f函数写成xlogx,那么Df(P||Q)就是KL散度:
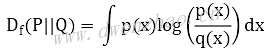
如果f函数写成-logx,那么Df(P||Q)就是逆KL散度:
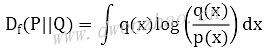
对于其他形式的f函数,对应的Df(P||Q)值也不同:
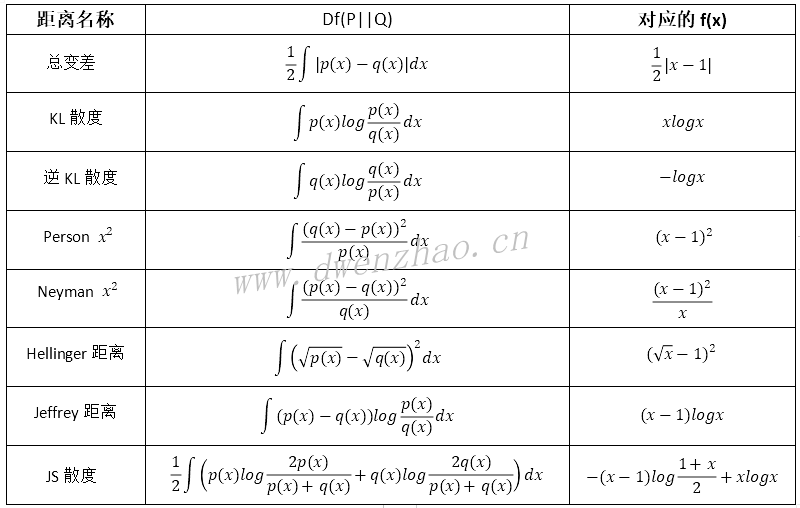
②凸共轭:
对于每一个凸函数,都能找到一个与之对应的共轭函数:
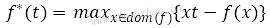
求一个凸函数对应的共轭函数,常用的方法是局部变分法。局部变分法,就是根据变量不同的x,从而绘制出不同的直线,这些直线共同构成一个图像。选择图像中不同区域内的最大值构成的函数,就是该凸函数对应的共轭函数。
通过直观的方式可以知道一个凸函数对应的凸函数图像的形状,但难以知道该共轭函数具体的函数形式,这可以通过简单推导获得。通过对凸函数求导,导数为0即为x的极值。
一些常见凸函数的共轭函数:
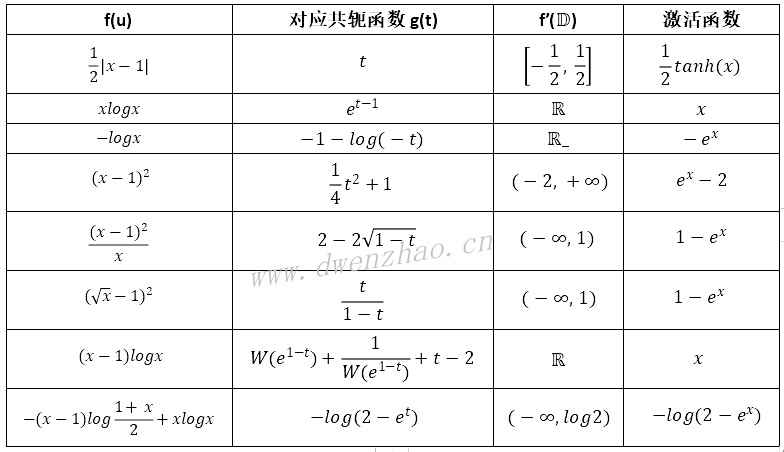
共轭函数还有一个互为共轭的性质,即凸函数的共轭函数的共轭函数就是凸函数本身。
③f散度与GAN的关系:
传统GAN中,训练生成器就是最小化两分布的JS散度,引入f散度,训练生成器最小化的是f散度,f散度包含了JS散度的情况。
这样,通过f散度将概率分布之间的差异定义统一到一个统一框架之中,通过凸共轭将f散度与GAN联系起来。只要找到一个符合f散度要求的函数,就能产生一个可以度量两分布之间差异的值,从而定义出不同的GAN,它们具有不同的目标函数。
4. GAN训练过程可视化:
GAN Lab是Google推出的一款简易的GAN可视化工具,它使用tensoflow.js直接运行在浏览器上,不需要安装与配置相应的环境,只需要浏览器打开即可。
GAN Lab可视化只会在二维平面上显示,因为复杂的高维空间可视化比较难以实现与理解。其中,MODEL OVERIVEW GRAPH用于展示GAN的模型结构以及训练过程中GAN模型的变化情况;LAYERED DISTRIBUTIONS用于展示GAN的数据分布,其中绿点表示真实数据的概率分布,而训练时产生的紫点表示生成数据的概率分布;METRICS用于表示GAN训练过程中各种指标的变化,例如生成器与判别器的损失、KL散度、JS散度的变化等。
显示界面中,生成器生成的数据点上有相应的线条,用于表示生成数据点的梯度,线条的大小表示梯度的大小,线条的方向表示梯度的方向。
为了细致理解GAN的训练过程,可以单击“开始”按钮旁的“时钟”,会将GAN训练的步骤细化。判别器的训练与生成器的训练都分为5步,判别器步骤:
· 获得生成器生成的样本
· 判别器对样本进行分类
· 计算判别器的损失
· 计算判别器的梯度
· 基于梯度更新判别器中的参数
生成器步骤与判别器类似。
GAN Lab还可以可视化GAN训练过程中生成器损失的变化情况以及KL散度、JS散度的变化情况。通过这些数据可以比较直观地了解当前GAN的训练状态。
单击“时钟”按钮旁的“下一步”按钮,可以控制GAN下一次训练时训练生成器还是判别器,或是两个都训练。
此外,GAN Lab还允许自定义模型的各种参数,如梯度下降使用什么算法,学习速率是多少,判别器与生成器隐藏层层数以及损失函数,都可以自定义。
经过一定次数的训练,最终实现了拟合真实数据分布的目的,此时JS散度是一个比较小的值。
二、卷积生成对抗网络:
可以将卷积生成对抗网络看成是由卷积神经网络与生成对抗网络组合而成,即将生成对抗网络的生成器、判别器网络结构都换成卷积神经网络。
卷积神经网络CNN(Convolutional Neural Network)特别擅长处理二维图像数据,当下与图像识别相关的网络结构都可以看到CNN。CNN的中心思想是分层加工信息,从而获得更高层的信息。
CNN采用局部连接的方式,带来的优势是网络参数大幅减少,从而降低训练的困难程度;而且还采用权值共享的方式使权值个数再降低。对于一个传统的CNN,其结构一般为输入层→卷积层→卷积层→池化层→卷积层→池化层→全连接,使用ReLU为激活函数。
1. DCGAN:
在DCGAN中,判别器与生成器都使用CNN,判别器使用正常的CNN,图像作为输入,判别出图像是真实图像还是生成图像,而生成器使用转置卷积神经网络,转置CNN可以生成图像,网络训练过程就像正常CNN的逆向过程。
此外,DCGAN的判别器与生成器都没有使用池化层,在判别器中使用带有步长的过滤器来完成卷积;生成器中最后一层使用Tanh作为激活函数,其余层都使用ReLU作为激活函数,判别器中所有层都使用Leaky ReLU作为激活函数。
2. TensorFlow实现DCGAN:
1)生成器:
TensorFlow把转置CNN封装成conv2d_transpose()方法。生成器代码:
def generator(self,z):
with tf.variable_scope("generator"):
s_h,s_w=self.output_height,self.output_width
s_h2,s_w2=conv_out_size_same(s_h,2),conv_out_size_same(s_w,2)
s_h4,s_w4=conv_out_size_same(s_h2,2),conv_out_size_same(s_w2,2)
s_h8,s_w8=conv_out_size_same(s_h4,2),conv_out_size_same(s_w4,2)
s_h16,s_w16=conv_out_size_same(s_h8,2),conv_out_size_same(s_w8,2)
#原始数据输入经过权重和偏置处理后获得的输入z_,h0_w第1层权重,h0_b第1层偏置
self.z_,self.h0_w,self.h0_b=linear(z,self.gf_dim*8*s_h16*s_w16,'g_h0_lin','with_w=True)
#输入改为3×3×512矩阵
self.h0=tf.reshape(self.z_,[-1,s_h16,s_w16,self.gf_dim*8])
#使用BN后,再使用ReLU激活函数
h0=tf.nn.relu(self.g_bn0(self.h0))
#转置卷积
self.h1,self.h1_w,self.h1_b=deconv2d(h0,[self.batch_size,s_h8,s_w8,self.gf_dim*4]
h1=tf.nn.relu(self.g_bn1(self.h1))
h2,self.h2_w,self.h2_b=deconv2d(h1,[self.batch_size,s_h4,s_w4,self.gf_dim*2]
h2=tf.nn.relu(self.g_bn2(h2))
h3,self.h3_w,self.h3_b=deconv2d(h2,[self.batch_size,s_h2,s_w2,self.gf_dim*1]
h2=tf.nn.relu(self.g_bn3(h3))
h4,self.h4_w,self.h4_b=deconv2d(h3,[self.batch_size,s_h,s_w,self.c_dim]
return tf.nn tanh(h4)
生成器代码中使用variable_scope()方法创建一个空间,便于参数重用。后面定义宽高,其中output的宽高为48,其他值通过conv_out_size_same()方法获取后除以2,函数定义:
def conv_out_size_same(size,stride):
#返回数字的上入整数
return int(math.ceil(float(size)/float(stride)))
生成器第1层使用linear()方法,就是生成权重矩阵与偏置,然后与输入值进行简单运算,实质是普通连接层。代码为:
def linear(input_,output_size,scope=None,stddev=0.02,bias_start=0.0,with_w=False):
shape=input_.get_shape().as_list()
with tf.variable_scope(scope or "Linear"):
try:
#random_normal_initializer
matrix=tf.get_variable('Matrix',[shape[1],output_size]
except ValueError as e:
msg="可能为图像尺寸问题"
e.args=e.args+(msg,)
raise
#constant_initializer
bias=tf.get_variable('bias',[output_size],initializer
if with_w:
return tf.matmul(input_,matrix)+bias,matrix,bias
else:
return tf.matmul(input,matrix)+bias
向linear()中传入随机生成的噪声z和第1层结构self.gf_dim*8*s_h16*s_w16(即64×8×3×3),接着通过reshape()方法重塑第1层self.z_矩阵,获得新的矩阵self.h0,结构为3×3×512。
第2层使用deconv2d()方法构建转置卷积层,代码:
def deconv2d(input_,output_shape,k_h=5,k_w=5,d_h=2,d_w=2,stddev=0.02,name='deconv2d',with_w=False):
with tf.variable_scope(name):
#random_norm_initializer生成服从正态分布的张量
w=tf.get_variable('w',[k_h,k_w,output_shape[-1],input_.get_shape()[-1],initializer
deconv=tf.nn.conv2d_transpose(input_,w,output_shape=output_shape,strides=[1,d_h,d_w,1])
#constant_initializer
biases=tf.get_variable('biases',[output_size[-1]],initializer=tf.constant_initializer(0.0)
deconv=tf.reshape(tf.nn.bias_add(deconv,biases),deconv.get_shape())
if with_w:
return deconv,w,biases
else:
return deconv
代码中依旧先通过使用variable_scope()方法创建一个张量空间,接着使用get_variable()方法获得一个矩阵,其中矩阵服从正态分布。接着使用conv2d_transpose()方法实现转置卷积操作,然后再次使用get_variable()方法获得一个具有常量值的张量作为偏置,接着将转置卷积操作后获得的deconv矩阵与biases相加,再使用reshape()重塑。其中,h1为转置卷积操作后的矩阵,h1_w是权重矩阵,也就是转置卷积操作时过滤器对应的矩阵,h1_b对应该层偏置。
构建转置卷积矩阵后,使用g_hn1()方法进行BN操作,再将BN操作后的值传递给ReLU激活函数。g_hn1()方法来自batch_norm类:
class batch_norm(object):
def __init__(self,essilon=1e-5,momentum=0.9,name="batch_norm"):
with tf.variable_scope(name):
self.epsilon=epsilon
self.momentum=momentum
self.name=name
def __call__(self,x,train=True):
return tf.contrib.layers.batch_norm(x,decay=self.momentum,updates_collections=None
Batch_norm类使用__init__方法初始化,__call__方法将类实例作为函数来调用。
2)判别器:
DCGAN判别器使用全卷积结构,使用步长来替代池化层,除最后一层都使用Leaky ReLU为激活函数。
def discriminator(self,images,reuse=False):
with tf.variable_scope("discriminator") as scope:
if reuse:
scope.reuse_variables()
h0=lrelu(conv2d(image,self.df_dim,name='d_h0_conv'))
h1=lrelu(self.d_bn1(conv2d(h0,self.df_dim*2,name='d_h1_conv')))
h2=lrelu(self.d_bn2(conv2d(h1,self.df_dim*4,name='d_h2_conv')))
h3=lrelu(self.d_bn3(conv2d(h2,self.df_dim*8,name='d_h3_conv')))
h4=linear(tf.reshape(h3,[self.batch_size,-1],1,'d_h4_lin'))
return tf.nn.sigmoid(h4),h4
代码中先通过reuse变量判断当下是否需要重用discriminator空间的变量,接着就是判别器全卷积网络的结构,使用conv2d()实现卷积层,使用lrelu()方法实现Leaky ReLU,代码:
def lrelu(x,leak=0.2,name='lrelu'):
return tf.maximum(x,leak*x)
def conv2d(input_,output_dim,h_h=5,k_w=5,d_h=2,d_w=2,stddev=0.02,name="conv2d"):
with tf.variable_scope(name):
w=tf.get_variable('w',[k_h,k_w,input_.get_shape()[-1],output_dim])
conv=tf.nn.conv2d(input_,w,strides=[1,d_h,d_w,1],padding='SAME')
biases=tf.get_variable('biases',[output_dim],initializer=tf.constant_initializer(0.0))
conv=tf.reshape(tf.nn.bias_add(conv,biases),conv.fet_shape())
return conv
3)获得测试样例:
在训练过程中,需要知道当前经过一定轮数训练后的生成器可以生成怎样的图像,方便直观了解当前DCGAN的状态。这需要再使用一次生成器,将生成图像保存到本地。为了避免对训练造成影响,需要固定当前生成器结构中的参数。
def sampler(self,z):
with tf.variable_scope("generator") as scope:
scope.reuse_variables()
s_h,s_w=self.output_height,self.output_width
s_h2,s_w2=conv_out_size_same(s_h,2),conv_out_size_same(s_w,2)
s_h4,s_w4=conv_out_size_same(s_h2,2),conv_out_size_same(s_w2,2)
s_h8,s_w8=conv_out_size_same(s_h4,2),conv_out_size_same(s_w4,2)
s_h16,s_w16=conv_out_size_same(s_h8,2),conv_out_size_same(s_w8,2)
h0=tf.reshape(linear(z,self.gf_dim*8*s_h16*s_w16,'g_h0_lin'),[-1,s_h16,s_w16,self.gf_dim*8])
#train=False
h0=tf.nn.relu(self.g_bn0(h0,train=False))
h1=deconv2d(h0,[self.batch_size,s_h8,s_w8,self.gf_dim*4],name='g_h1')
h1=tf.nn.relu(self.g_bn1(h1,train=False))
h2=deconv2d(h1,[self.batch_size,s_h4,s_w4,self.gf_dim*2],name='g_h2')
h2=tf.nn.relu(self.g_bn2(h2,train=False))
h3=deconv2d(h2,[self.batch_size,s_h2,s_w2,self.gf_dim*1],name='g_h3')
h2=tf.nn.relu(self.g_bn3(h3,train=False))
h4=deconv2d(h3,[self.batch_size,s_h,s_w,self.c_dim],name='g_h4')
return tf,nn tanh(h4)
结构还是生成器结构,只不过网络结构中的参数使用的是generator空间中的参数,并且使用BN操作时要表明当前不是训练状态。
4)构建DCGAN整体:
整体逻辑是先使用generator()方法和discriminator()方法获得生成器和判别器的实例,再定义并最小化相应损失,定义最小化损失的优化方法。
def build_model(self):
#图像大小
if self.crop:
image_dims=[self.output_height,self.output_width,self.c_dim]
else:
image_dims=[self.input_height,self.input_width,self.c_dim]
#真实图像输入
self.inputs=tf.placeholder(tf.float32,[self.batch_size]+image_dims,name='real_images')
inputs=self.inputs
self.z=tf.placeholder(tf.float32,[None,self.z_dim],name='z')
#直方图显示
self.z_sum=histogram_summary('z',self.z)
#生成器
self.G=self.generator(self.z)
#判别器
self.D,self.D_logits=self.discriminator(inputs,reuse=False)
#生成器样例
self.sampler=self.sampler(self.z)
#判别器,判别生成图像
self.D_,self.D_logits_=self..discriminator(inputs,reuse=True)
self.D_sum=histogram_summary("d",self.D)
self.d_sum=histogram_summary("d_",self.D_)
#图像显示
self.G_sum=image_summary("G",self.G)
# 判别器判别真实图像的损失
self.d_loss_real=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits
# 判别器判别生成图像的损失
self.d_loss_fake=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits
# 生成器希望判别器判别自己生成图像的损失
self.g_loss=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits
# 使用scalar_summary记录损失的变量,以便显示
self.d_loss_real_sum=scalar_summary("d_loss_real",self.d_loss_real)
self.d_loss_fake_sum=scalar_summary("d_loss_fake",self.d_loss_fake)
self.d_loss=self.d_loss_real+self.d_loss_fake
self.g_loss_sum=scalar_summary("g_loss",self.g_loss)
self.d_loss_sum=scalar_summary("d_loss",self.d_loss)
t_vars=tf.trainable_variables()
self.d_vars=[var for var in t_vars if 'd_' in var.name]
self.g_vars=[var for var in t_vars if 'g_' in var.name]
self.saver=tf.train.Saver()
代码中先定义要使用的张量,然后构建生成器、判别器,获得当前训练轮下生成器的测试样例,然后构建生成器与判别器的损失,为真实图像赋值1,给生成图像赋值0,而生成器则希望判别器给自己生成的图像赋值1,生成器与判别器相互对抗。
5)训练DCGAN:
构建完成DCGAN后就可以训练,训练时最小化损失使用Adam算法。
def train(self,config):
d_optim=tf.train.AdamOptimizer(config.learning_rate,beta1=config.beta1).minimize
g_optim=tf.train.AdamOptimizer(config.learning_rate,beta1=config.beta1).minimize
try:
tf.global_variables_initializer().run()
except:
tf.initializer_all_variables().run()
self.g_sum=merge_summary([self.z_sum,self.d_sum,self.G_sum,self.d_loss_fake_sum,self.g_loss_sum])
self.d_sum=merge_summary([self.z_sum,self.D_sum,self.d_loss_real_sum,self.d_loss_sum])
#输出到Russell指定路径
self.writer=SummaryWriter("./output/logs",self.sess.graph)
sample_z=np.random.uniform(-1,1,size=(self.sample_num,self.z_dim))
sample_files=self.data[0:self.sample_num]
#获得生成器生成的fake img
sample=[get_image(sample_file,input_height=self.input_height,input_width=self.input_width
if (self.grayscale):
sample_inputs=np.array(sample).astype(np.float32)[:,:,:,None]
else:
sample_inputs=np.array(sample).astype(np.float32)
counter=1
start_time=time.time()
#加载checkpoint文件
could_load,checkpoint_counter=self.load(self.checkpoint_dir)
if could_load:
counter=checkpoint_counter
print("[*]LOAD SUCCESS")
else:
print("[*]LOAD failed...")
for epoch in range(config.epoch):
self.data=glob(os,path.join(cinfig.data_dir,config.dataset,self.input_fname_pattern))
np.random.shuffle(self.data)
batch_idxs=min(len(self.data),config.train_size)
for idx in range(0,int(batch_idxs)):
batch_files=self.data[idx*config.batch_size:(idx+1)*config.batch_size]
batch=[get_image(batch_file,input_height=self.input_height,input_width
if (self.grayscale):
batch_images=np.array(batch).astype(np.float32)[:,:,:,None]
else:
batch_images=np.array(batch).astype(np.float32)
batch_z=np.random.uniform(-1,-1,[config.batch_size,self.z_dim]).astype(np.float32)
#更新判别器D,先训练判别器D
_,summary_str=self.sess.run([d_optim,self.d_sum,feed_dict={self.inputs:batch_images,self.z:batch_z})
self.writer.add_summary(summary_str,counter)
#更新生成器G,再训练生成器G
_,summary_str=self.sess.run([g_optim,self.g_sum,feed_dict={self.z:batch_z})
self.writer.add_summary(summary_str,counter)
#再次训练生成器G,确保d_loss不为0
_,summary_str=self.sess.run([g_optim,self.g_sum,feed_dict={self.z:batch_z})
self.writer.add_summary(summary_str,counter)
errD_fake=self.d_loss_fake.eval({self.z:batch_z})
errD_real=self.d_loss_real.eval({self.inputs:batch_images})
errG=self.g_loss.eval({self.z:batch_z})
counter+=1
print("Epoch: [%2d/%2d] [%4d/%4d] time: %4.4f, d_loss: %.8f, g_loss: %.8f" %(epoch,config.epoch,idx
if np.mod(counter,100)==1:
try:
#生成图像
samples,d_loss,g_loss=self.sess.run([self.sampler,self.d_loss
save_images(samples,image_manifold_size(samples.shape[0])
print("[Sample] d_loss: %.8f, g_loss: %.8f" %(d_loss,g_loss))
except:
print("one pic error!...")
if np.mod(counter,500)==2:
self.save(config.checkpoint_dir,counter)
因为DCGAN训练需要花比较长的时间,如果模型训练过程因意外中断,从头开始成本较高,所以每次训练前都加载此前训练保留下的checkpoint模型文件,根据模型文件接着中断处继续训练。
训练DCGAN的核心在两层for循环中,一开始通过get_image方法获得此轮要训练的一组图像,接着生成噪声batch_z,通过运行进行训练并将结果记录到log中。训练一次判别器就相应训练两次生成器。训练中,每训练100轮保存一次当前生成器生成的图像,方便训练完成后观察。
前面的所有代码都在DCGAN类下,训练DCGAN时,首先要实例化DCGAN类,再调用其中的train()方法进行训练,这些代码在main()函数中。
def main(_):
pp.pprint(flags.FLAGS._flags)
if FLAGS.input_width is None:
FLAGS.input_width=FLAGS.input_height
if FLAGS.output_width is None:
FLAGS.output_width=FLAGS.output_height
if not os.path.exisrs(FLAGS.checkpoint_dir):
os.makedirs(FLAGS.checkpoint_dir)
if not os.path.exisrs(FLAGS.sample_dir):
os.makedirs(FLAGS.sample_dir)
run_config=tf.ConfigProto()
run_config.gpu_options.allow_growth=True
with tf.Session(config=run_config) as sess:
dcgan=DCGAN(sess,input_width=FLAGS.input_width,input_height=FLAGS.input_height,output_width
show_all_variables()
if FLAGS.train:
dcgan.train(FLAGS)
else:
if not dcgan.load(FLAGS.checkpoint_dir)[0]:
raise Exception("[!] 没有checkpoint文件,请先train")
OPTION=1
# 可视化
visualize(sess,dcgan,FLAGS,OPTION)
if __name__='__main__':
tf.app.run()
代码中,构建Session对象,并在其中初始化DCGAN实例,然后调用train()方法训练,最后通过visualize()可视化。可视化代码:
def visualize(sess,dcgan,config,option):
image_frame_dim=int(math.cei(config.batch_size**.5))
if option==0:
z_sample=np.random.uniform(-0.5,0.5,size=(config.batch_size,dcgan.z_dim))
#生成图像
samples=tf.run(dcgan.sampler,feed_dict={dcgan.z:z_sample})
#保存图像
save_images(samples,[image_frame_dim,image_frame_dim],'./output/samples
elif option==1:
#values是和batch_size等长的向量,从0~1递增
values=np.arange()0,1,1./config.batch_size)
# 生成z_dim张图像
for idx in range(dcgan.z_dim):
print("[*] %d"%idx)
z_sample=np.random.uniform(-1,1,size=(config.batch_size,dcgan.z_dim))
#将Z_sample的idx列替换成values
for kdx,z in enumerate(z_sample):
z[idx]=values[kdx]
samples=sess.run(dcgan.sanpler,feed_dict={dcgan_z:}z_sample)
save_images(samples,[image_frame_dim,image_frame_dim],'./output
代码完成后,使用命令运行DCGAN代码:
python -u main.py --input_height 96 --output_height 48 --dataset faces --crop --train --epoch 300 --input_fname_pattern "*.jpg"
命令中使用faces数据集,该数据集包含33430张动漫人物头像,通过爬虫爬取相应网站的动漫人物,再通过openCV的人脸识别算法识别动漫人物的头像,将其剪切成96×96的头像图像。使用这些头像数据来训练DCGAN,系统训练后,DCGAN的生成器可以生成较真实的动漫人物头像。
DCGAN的结构比较复杂,单纯使用CPU进行训练可能要花费十几天才能训练完300轮。为了缩短训练时间,需要使用GPU来提升训练速度,因为训练神经网络涉及大量浮点数以及矩阵运算,CPU并不擅长处理这类运算,但GPU却很适合。
但因为GPU价格较贵,推荐租用GPU,有很多平台提供这种服务。
3. 对GAN的一些改进:
传统GAN存在梯度消失与模式崩溃问题,影响最终GAN的性能。
1)Wasserstein GAN:
原始GAN使用KL散度、JS散度来衡量生成数据分布与真实数据分布之间的距离,但其中存在问题。Wasserstein GAN使用Wasserstein距离来衡量两个分布之间的距离。
Wasserstein距离也称EM(Earth Mover’s Distance)距离,将两组数据想象成两堆土,用一台推土机将土堆P上的土推到土堆Q上,往返多次,直到将P完全推到Q上,此时推土机移动的总距离的平均值就是EM距离。使用EM距离,就算两个数据分布之间没有任何重叠或重叠部分可以被忽略,依旧可以正常衡量两个数据分布的距离,避免了梯度消失等问题。
相对于传统的GAN,使用EM距离的WGAN只做了如下改动:
· 判别器最后一层去掉sigmoid
· 生成器与判别器的损失不再取log
· 训练判别器时,每次参数更新后的值限制在一个范围(-c, c)
· 不使用基于动量的梯度优化算法,推荐使用RMSProp或SGD算法
前面两点就是不再使用JS散度,第3点实践中保证判别器目标函数平滑,最后一点是实践中发现,使用Adam这类涉及动量的梯度下降算法时判别器损失可能会出现大幅度抖动。
示例是读取fashion数据集:
from tensorflow.example.tutorials.mnist import input_data
fashionmnist=input_data.read_data_sets(r'Users/gan/fashion-mnist/data/fashion',one_hot=True)
train_img=fashionmnist.train.images
self.data_x=train_img.reshape(len(train_img),28,28,1)
self.data_y=fashionmnist.train.labels
# get number of batches for a single epoch
self.num_batches=len(self.data_x)
判别器代码:
def discriminator(self,x,is_training=True,reuse=False):
with tf.variable_scope("D",reuse=reuse):
# conv+lrelu
net=lrelu(conv2d(x,64,4,4,2,2,name='d_conv1'))
# conv+bn+lrele
net=lrelu(bn(conv2d(net,128,4,4,2,2,name='d_conv2'),is_training=is_training,scope='d_bn2'))
# reshape
net=tf.reshape(net,[self.batch_size,-1])
net=lrelu((bn(linear(net,1024,scope='d_fc3'),is_training=is_training,scope='d_bn3')))
out_logit=linear(net,1,scope='d_fc4')
out=tf.nn.sigmoid(out_logit)
return out,out_logit,net
判别器使用两个卷积层和两个全连接层,返回的out_logit没有经过sigmoid。
生成器代码:
def generator(self,z,is_training=True,reuse=False):
with tf.variable_scope("G",reuse=reuse):
net=tf.nn.relu(bn(linear(z,1024,scope='g_fc1'),is_training=is_training,scope='g_bn1'))
# conv+bn+lrele
net=tf.nn.relu(bn(linear(net,128*7*7,scope='g_fc2'),is_training=is_training,scope='g_bn2'))
# 转置卷积
net=tf.reshape(net,[self.batch_size,7,7,128])
net=tf.nn.relu(bn(deconv2d(net,[self.batch_size,14,14,64],4,4,2,2,name='g_dc3')
out=tf.nn.sigmoid(deconv2d(net,[self.batch_size,28,28,1],4,4,2,2,name='g_dc4')
return out
生成器开始是两个全连接层,然后通过两个转置卷积层来生成图像。
然后使用生成器和判别器构建网络:
# 真实图像-->判别器
D_real,D_real_logits,_=self.discriminator(self.inputs,is_training=True,resue=False)
#生成器
G=self.generator(self.z,is_training=True,resue=False)
# 生成图像-->判别器
D_fake,D_fake_logits,_=self.discriminator(G,is_training=True,resue=True)
# 损失
d_loss_real=-tf.reduce_mean(D_real_logits)
d_loss_real=tf.reduce_mean(D_fake_logits)
self.d_loss=d_loss_real+d_loss_fake
self.g_loss=-d_loss_fake
真实图像损失取D_real_logits平均值的负值,生成图像损失取D_fake_logits平均值的正值,这二者构成判别器的损失。
下面使用Adam优化算法来更新模型中的参数:
t_vars=tf.trainable_variables()
d_vars=[var for var in t_vars if 'd_' in var.name]
g_vars=[var for var in t_vars if 'g_' in var.name]
with tf.control_dependencies(tf.get_collection(tf.GraphKeys.UPDATE_OPS)):
self.d_optim=tf.train.AdamOptimizer(self.learning_rate,beta1=self.beta1)
self.g_optim=tf.train.AdamOptimizer(self.learning_rate*5,beta1=self.beta1)
以上代码与传统GAN中流程是一样的。WGAN主要就是让判别器参数服从1-Lipschitz约束,是使用Weight Clipping的方式来实现的,实现方法:
# weight Clipping
self.clip_D=[p.assign(tf.clip_by_value(p,-0.01,0.01)) for p in d_vars]
代码中用列表生成的方法对判别器的所有参数d_vars都进行了裁剪,裁剪范围(-0.01,0.01)。tf.clip_by_value(A,min,max)方法用于将张量A中的每一个元素压缩到min与max之间,如果元素的值小于min则让其值等于min,如果元素的值大于man则让其值等于max。tf.assign (A, new_number)方法则是将张量A的值变为新值new_number。
训练部分的主要代码:
for epoch in range(start_rpoch,self.epoch):
# get batch size
for idx in range(start_batch_id,self.num_batches):
#一组数据
batch_images=self.data_x[idx*self.batch_size:(idx+1)*self.batch_size]
batch_z=np.random.uniform(-1,1,[self.batch_size,self.z_dim]).astype(np.float32)
# update D network
_,_,summary_str,d_loss=self.sess.run([self.d_optim,self.clip_D,self.d_sum,self.d_loss]
self.writer.add_summary(summary_str,counter)
# update G network
if (counter-1) % self.disc_iters==0:
_,summary_str,g_loss=self.sess.run([self.g_optim,self.g_sum,self.g_loss]
self.writer.add_summary(summary_str,counter)
counter+=1
这里的WGAN示例比较简单,可以使用CPU训练,训练25轮就可以达到需要。
2)WGAN-GP:
WGAN会遇到训练艰难、收敛缓慢的问题,造成的原因就是Weight Clipping。Weight Clipping有个定义范围,如果设置过小会造成梯度消失,而设置较大又会出现梯度爆炸,需要大量测试才能找到一个合适的区间。为此,又提出一种改进方法--梯度惩罚,惩罚项的数据采样于惩罚空间。
示例同样使用fashion-mnist数据集,生成器与判别器结构与WGAN的示例一致,定义损失:
D_real,D_real_logits,_=self.discriminator(self.inputs,is_training=True,resue=False)
G=self.generator(self.z,is_training=True,resue=False)
D_fake,D_fake_logits,_=self.discriminator(G,is_training=True,resue=True)
# 判别器损失
d_loss_real=-tf.reduce_mean(D_real_logits)
d_loss_real=tf.reduce_mean(D_fake_logits)
self.d_loss=d_loss_real+d_loss_real
#生成器损失
self.g_loss=-d_loss_fake
代码中损失定义与WGAN是一样的,不同的是WGAN-GP使用Gradient Penalty替代WGAN中的Weight Clipping:
self.d_loss+=self.lambd*gradient_penalty
其中的self.lambd通常是固定的值,梯度惩罚的核心是计算出gradient_penalty,即从生成数据与真实数据之间的空间分布中抽取样本计算:
alpha=tf.random_uniform(shape=self.inputs.get_shape(),minval=0,maxval=1.)
differences=G-self.inputs
interpolates=self.inputs+(alpha*differences)
其中differences就是生成数据与真实数据之间的差值,乘以一个随机变量alpha后再加上真实数据的值,就获得了生成数据与真实数据之间空间分布中的一个样本,这样样本传入判别器:
_,D_inter,_=self.discriminator(interpolates,is_training=True,reuse=True)
gradients=tf.gradients(D_inter,[interpolates])[0]
slopes=tf.sqrt(tf.reduce_sum(tf.square(gradients),reduction_indices=[1]))
gradient_penalty=tf.reduce_mean((slopes-1.)**2)
self.d_loss+=self.lambd*gradient_penalty
将判别器输出D_inter应用TensorFlow提供的梯度计算方法来计算梯度,然后计算梯度矩阵对应的1-范数,其中tf.reduce_sum()方法计算梯度张量某一维度的和。这样就可以计算出惩罚梯度。以下的逻辑与WGAN是一样的。
训练代码:
for epoch in range(start_rpoch,self.epoch):
# get batch size
for idx in range(start_batch_id,self.num_batches):
#一组数据
batch_images=self.data_x[idx*self.batch_size:(idx+1)*self.batch_size]
batch_z=np.random.uniform(-1,1,[self.batch_size,self.z_dim]).astype(np.float32)
# update D network
_,summary_str,d_loss=self.sess.run([self.d_optim,self.d_sum,self.d_loss]
self.writer.add_summary(summary_str,counter)
# update G network
if (counter-1) % self.disc_iters==0:
batch_z=np.random.uniform(-1,1,[self.batch_size,self.z_dim]).astype(np.float32)
_,summary_str,g_loss=self.sess.run([self.g_optim,self.g_sum,self.g_loss]
self.writer.add_summary(summary_str,counter)
counter+=1
训练与模型比较简单,可以在CPU上运行,训练22轮就能达到效果。
3)SN-GAN:
为了使GAN训练更加稳定,增加了正则化项Spectral Normalization,该正则项会作用于整个判别器参数上,从而实现判别器在训练过程中可以提供稳定梯度的效果。
SN-GAN中使用Spectral Normalization就是判别器的所有权重都除以谱范数,而谱范数就是矩阵最大特征值的开方。但直接计算谱范数比较耗时,幂迭代(power iteration)方法可以比较快速计算出近似值。
Spectral Normalization代码:
def spectral_norm(w,interation=1):
w_shape=w.shape.as_list()
w=tf.reshape(w,[-1,w_shape[-1]]);
u=tf.get_variable('u',[1,w_shape[-1]],initializer=tf.truncated_normal_initializer()
u_hat=u
v_hat=None
for i in range(interation):
'''
power interation
Usually interation=1 will be enough
'''
# tf.transpose Transposes 'a'. Permutes the dimensions according to 'perm'
v_=tf.matmul(u_hat,tf.transpose(w))
v_hat=l2_norm(v_)
u_=tf.matmul(v_hat,w)
u_hat=l2_norm(u_)
sigma=tf.matmul(tf.matmul(v_hat,w),tf.transpose(u_hat))
w_norm=w/sigma
with tf.control_dependencies([u.assign(u_hat]):
w_norm=tf.reshape(w_norm,w_shape)
return w_norm
首先重塑权重矩阵,然后通过tf.get_variable()方法获取张量u初始的随机值;接着是power iteration逻辑,通过多次迭代后获得张量U_hat和张量v_hat;然后通过这两个张量计算出||W||的近似值sigma。这里只迭代一次,因为简单的GAN结构与训练数据迭代一次就足够,最后进行简单除法,得到通过谱归一化处理的权重。代码中使用的l2_norm方法:
def l2_norm(v,eps=1e-12):
return v/(tf.reduce_sun(v**2)**0.5+eps)
GAN的主要结构是卷积层、转置卷积层及全连接层,将谱归一化用于结构上。
def sn_conv2d(input_,output_dim,k_h=5,k_w=5,d_h=2,d_w=2,stddev=0.02,name='conv2s_sn',use_bias=False):
with tf.variable_scope(name):
w=tf.get_variable('w',[k_h,k_w,input_.get_shape()[-1]
bias=tf.get_variable('bias',[output_dim],initializer=tf.constant_initializer(0.0))
conv=tf.nn.conv2d(input_,spectral_norm(w),strides=[1,d_h,d_w,1],padding='SAME')
if use_bias:
conv=tf.nn.bias_add(conv,bias)
return conv
def sn_linear(input_,output_size,scope=None,stddev=0.02,bias_start=0.0,with_w=False):
shape=input_.get_shape().as_list()
with tf.variable_scope(scope or 'Linear'):
matrix=tf.get_variable('Matrix',[shape[1],output_size]
bias=tf.get_variable('bias',[output_size],initializer=tf.constant_initializer(bias_start))
if with_w:
return tf.matmul(input_,spectral_norm(matrix))+bias,matrix,bias
else:
return tf.matmul(input_,spectral_norm(matrix))+bias
转置卷积层不需要谱归一化,因为通常转置卷积层用于构建生成器,对应生成器的权重参数并不需要进行谱归一化。
然后定义判别器与生成器:
def discriminator(self,x,is_training=True,reuse=False):
with tf.variable_scope("D",reuse=reuse):
# conv+lrelu
net=lrelu(sn_conv2d(x,64,4,4,2,2,name='d_conv1'))
# conv+bn+lrele
net=lrelu(bn(sn_conv2d(net,128,4,4,2,2,name='d_conv2'),is_training
# reshape
net=tf.reshape(net,[self.batch_size,-1])
net=lrelu((bn(sn_linear(net,1024,scope='d_fc3'),is_training
out_logit=sn_linear(net,1,scope='d_fc4')
out=tf.nn.sigmoid(out_logit)
return out,out_logit,net
def generator(self,z,is_training=True,reuse=False):
with tf.variable_scope("G",reuse=reuse):
net=tf.nn.relu(bn(linear(z,1024,scope='g_fc1'),is_training
# conv+bn+lrele
net=tf.nn.relu(bn(linear(net,128*7*7,scope='g_fc2'),is_training
# 转置卷积
net=tf.reshape(net,[self.batch_size,7,7,128])
net=tf.nn.relu(bn(deconv2d(net,[self.batch_size,14,14,64],4,4,2,2
out=tf.nn.sigmoid(deconv2d(net,[self.batch_size,28,28,1],4,4,2,2,name='g_dc4')
return out
可见,判别器中的卷积层与全连接层都使用了谱归一化,而生成器与WGAN一样。下面构建GAN并定义损失,直接使用交叉熵损失:
def discriminator_loss(real,fake):
real_loss=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits
fake_loss=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits
loss=real_loss+fake_loss
return loss
def generator_loss(fake):
loss=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels
return loss
调用上面定义的判别器及生成器损失:
# 真实图像-->判别器
D_real,D_real_logits,_=self.discriminator(self.inputs,is_training=True,resue=False)
#生成器
G=self.generator(self.z,is_training=True,resue=False)
# 生成图像-->判别器
D_fake,D_fake_logits,_=self.discriminator(G,is_training=True,resue=True)
# 损失
self.d_loss,d_loss_real,d_loss_fake=discriminator_loss(real=D_real_logits,fake=D_fake_logits)
self.g_loss=generator_loss(fake=D_fake_logits)
下面流程与过去一致,先分别获得判别器与生成器中的参数,再使用Adam优化算法更新这些参数:
t_vars=tf.trainable_variables()
d_vars=[var for var in t_vars if 'd_' in var.name]
g_vars=[var for var in t_vars if 'g_' in var.name]
with tf.control_dependencies(tf.get_collection(tf.GraphKeys.UPDATE_OPS)):
self.d_optim=tf.train.AdamOptimizer(self.learning_rate,beta1=self.beta1)
self.g_optim=tf.train.AdamOptimizer(self.learning_rate*5,beta1=self.beta1)
后面是常见的训练流程,通过sess.run()方法传入数据训练,先训练判别器,再训练生成器:
for epoch in range(start_rpoch,self.epoch):
# get batch size
for idx in range(start_batch_id,self.num_batches):
#一组数据
batch_images=self.data_x[idx*self.batch_size:(idx+1)*self.batch_size]
batch_z=np.random.uniform(-1,1,[self.batch_size,self.z_dim]).astype(np.float32)
# update D network
_,summary_str,d_loss=self.sess.run([self.d_optim,self.d_sum
self.writer.add_summary(summary_str,counter)
# update G network
if (counter-1) % self.disc_iters==0:
_,summary_str,g_loss=self.sess.run([self.g_optim
self.writer.add_summary(summary_str,counter)
counter+=1
示例的SN-GAN结构简单,训练数据也简单,在本机CPU上就可以运行,20轮就可以得到效果。
三、条件生成对抗网络:
为了实现图像间风格转换,且转换出的图像不会模糊,就需要使用条件生成对抗网络。条件生成对抗网络CGAN
对生成器而言,首先要获得一组随机生成的噪声,其次是获得相应的约束条件,例如一张灰度图像作为约束条件,该图像不能直接输入,而是需要进行一些预处理,获得相应的矩阵再输入生成器;对判别器也是同样的流程,输入的约束条件需要经过预处理得到CGAN对应的模型。
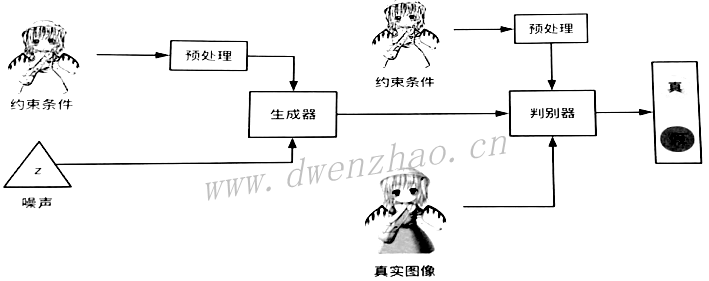
CGAN训练步骤:
· 从数据库中获取正面数据,就是真实图像与其匹配的条件
· 生成噪声数据,与条件约束构成负面数据
· 将正面数据与负面数据都输入判别器,训练判别器最大化目标函数;固定判别器,将负面数据输入生成器,训练生成器最小化目标函数
1. ColorGAN的实现:
ColorGAN通过CGAN来实现,判别器和生成器使用DCGAN,训练数据使用25000张彩色动漫图像。读取彩色真实图像,作为判别器判别真实图像的标准,通过彩色图像生成线条图作为约束条件,要求生成器根据线条图案来生成对应的彩色图像。
使用DCGAN结构,即生成器使用转置卷积构建网络结构来生成图像,判别器使用卷积结构来判别图像,因为卷积结构非常适合处理图像数据。
1)构建生成器与判别器:
生成器不仅要接收噪声数据,还要接收线条图像作为约束条件,需要对线条图像进行预处理,而单纯由转置卷积构成的生成器并不能很好地对线条图像进行预处理,因此还需要卷积结构,两种结构构成类U型网络。条件约束对应的图像输入生成器,生成器通过卷积层抽取约束图像的特征向量,再通过转置卷积层利用获取的特征向量来生成图像。
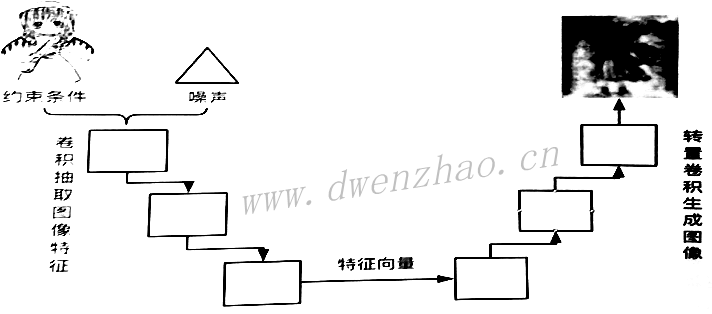
def conv2d(input_,output_dim,k_h=5,k_w=5,d_h=2,d_w=2,stddev=0.02,name='conv2d'):
with tf.variable_scope(name):
w=tf.get_variable('w',[k_h,k_w,input_.get_shape()[-1],output_dim]
conv=tf.nn.conv2d(input_,w,strides=[1,d_h,d_w,1],padding='SAME')
#constant_initializer
biases=tf.get_variable('biases',[output_dim],initializer=tf.constant_initializer(0.0)
conv=tf.reshape(tf.nn.bias_add(conv,biases),conv.get_shape())
return conv
def deconv2d(input_,output_shape,k_h=5,k_w=5,d_h=2,d_w=2,stddev=0.02,name='deconv2d',with_w=False):
with tf.variable_scope(name):
w=tf.get_variable('w',[k_h,k_w,output_shape[-1],input_.get_shape()[-1]
deconv=tf.nn.conv2d_transpose(input_,w,output_shape=output_shape,strides=[1,d_h,d_w,1])
#constant_initializer
biases=tf.get_variable('biases',[output_shape[-1]],initializer=tf.constant
deconv=tf.reshape(tf.nn.bias_add(deconv,biases),deconv.get_shape())
if with_w:
return deconv,w,biases
else:
return deconv
上面为构建卷积层与转置卷积层的代码,与DCGAN的代码相同。生成器代码:
def generator(self,img_in):
with tf.variable_scope("generator") as scope:
s=self.output_size
s2,s4,s8,s16,s32,s64,s128=int(s/2),int(s/4),int(s/8),int(s/16),int(s/32)
#卷积结构抽取数据特征
e1=conv2d(img_in,self.gf_dim,name='g_e1_conv')
e2=bn(conv2d(lrelu(e1),self.gf_dim*2,name='g_e2_conv'))
e3=bn(conv2d(lrelu(e2),self.gf_dim*4,name='g_e3_conv'))
e4=bn(conv2d(lrelu(e3),self.gf_dim*8,name='g_e4_conv'))
e5=bn(conv2d(lrelu(e4),self.gf_dim*8,name='g_e52_conv'))
#转置卷积结构生成图像数据
self.d4,self.d4_w,self.d4_b=deconv2d(tf.nn.relu(e5),[self.batch_size,s16,s16
d4=bn(self.d4)
d4=tf.concat(axis=3,values=[d4,e4])
self.d5,self.d5_w,self.d5_b=deconv2d(tf.nn.relu(d4),[self.batch_size,s8,s8
d5=bn(self.d5)
d5=tf.concat(axis=3,values=[d5,e3])
self.d6,self.d6_w,self.d6_b=deconv2d(tf.nn.relu(d5),[self.batch_size,s4,s4
d6=bn(self.d6)
d6=tf.concat(axis=3,values=[d6,e2])
self.d7,self.d7_w,self.d7_b=deconv2d(tf.nn.relu(d6),[self.batch_size,s2,s2
d7=bn(self.d7)
d7=tf.concat(axis=3,values=[d7,e1])
self.d8,self.d8_w,self.d8_b=deconv2d(tf.nn.relu(d7),[self.batch_size,s,s
return tf.nn tanh(d8)
生成器分为两部分,一是由卷积层构成的卷积网络,用于抽取输入数据中的特性;二是由转置卷积层构成的转置卷积网络,用于生成图像数据。其中还使用了bn和lrelu方法,前面已经介绍。
判别器单纯由卷积层组成:
def discriminator(self,image,y=None,reuse=False):
# image[256,256,input_c_dim+output_c_dim]
with tf.variable_scope("discriminator") as scope:
if reuse:
scope.reuse_variables()
else:
assert scope.reuse==False
h0=lrelu(conv2d(image,self.df_dim,name='d_h0_conv'))
h1=lrelu(self.d_bn1(conv2d(h0,self.df_dim*2,name='d_h1_conv')))
h2=lrelu(self.d_bn2(conv2d(h1,self.df_dim*4,name='d_h2_conv')))
h3=lrelu(self.d_bn3(conv2d(h2,self.df_dim*8,d_h=1,d_w=1,name='d_h3_conv')))
h4=linear(tf.reshape(h3,[self.batch_size,-1],1,'d_h4_lin'))
return tf.nn.sigmoid(h4),h4
判别器是4层卷积层,使用步长来替代池化层,结构比较简单,最后使用sigmoid函数将判别器输出的结果映射到0~1之间。
2)图像数据预处理:
因为数据集中只有彩色真实图像数据,而没有与之对应的线条图,所以需要使用代码来生成,其中使用OpenCV3来实现。使用前需要安装:
pip install opencv-python
然后就可以对图像进行处理,实现真实图像转换为线条图。
import cv2
import matplotlib.pyplot as plt
filename='imgs/model.jpg'
img=cv2.imread(filename)
#转换为灰度图
img_gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
base_edge=cv2.adaptiveThreshold(img_gray,255,cv2.ADAPTIVE_THRESH_MEAN_C
print(base_edge.shape)
plt.imshow(base_edge)
plt.axis('off')
plt.show()
代码很简单,核心方法是cv2.adaptiveThreshold()。这个方法用于自适应二值化,是通过对比输入图像的像素I与某个比较值K,根据比较结果对输入图像的像素I进行处理。输入图像中不同像素对应的比较值K不同,比较值K等于以像素I为中心的一块区域内计算出的值减去差值C得来。比较值K的具体计算方法由使用者传入的值决定。
· ADAPTIVE_THRESH_MEAN_C:表示计算以像素I为中心的区域的平均值,再使用这个平均值减去差值C,获得最终的比较值K
· ADAPTIVE_THRESH_GAUSS_C:表示通过高斯分布加权获得一个值,再通过该值减去差值C获得最终的比较值K
像素I与比较值K进行对比后获得结果,根据传入的类型参数进行判断。如果处理,则类型参数通常为:
· THRESH_BINARY:表示两者比较后,如果像素I大于比较值K,就将像素I对应值设为最大值,反之设为0
· THRESH_BINARY-INV:表示两者比较后,如果像素I小于比较值K就将像素I对应的值设为最大值,反之则设为0
为了提升生成器生成效率,使用具有颜色暗示的模糊图像当作噪声输入生成器。具体做法是先随机除去真实图像中的部分像素,然后再将除去元素后的图像进行最均值滤波操作,获得一张模糊的图像。代码:
from random import randint
filename='imgs/model.jpg'
cimg=cv2.imread(filename,1)
cimg=np.fliplr(cimg.reshape(-1,3)).reshape(cimg.shape)
#随机切割并模糊化
for i in range(30):
randx=randint(0,250)
randy=randint(0,250)
cimg[randx:randx+50,randy:randy+50]=255
blur=cv2.blur(cimg,(100,100))
plt.feature(figsize=(40,20))
plt.axis('off')
plt.subplot(131)
plt.imshow(cimg)
plt.subplot(132)
plt.imshow(blur)
CV2的读入图像imread()方法,第2个参数可以有多种设置:
· IMREAD_UNCHANGED=-1:不做任何处理
· IMREAD_COLOR=1:转换为BGR样式的彩色图像
· IMREAD_GRAYSCALE=0:转为单通道灰度图像
需要注意,OpenCV的接口使用BGR模式,读入图像如果要使用matplotlib显示需要矩阵反转,这里通过np.fliplr()实现,该方法只是让行折叠翻转而不移动列。
3)ColorGAN训练:
需要先定义图像读取函数:
def get_image(image_path):
return transform(imread(image_path))
def transform(image,npx=512,is_crop=True):
cropped_image=cv2.resize(image,(256,256))
return np.array(cropped_image)
def imread(path):
readimage=cv2.imread(path,1)
return readimage
然后构建ColorGAN的整体结构:
def build_model(self):
#线条图像
self.line_images=tf.placeholder(tf.float32,[self.batch_size,self.image_size,self.image_size
#模糊图像
self.color_images=tf.placeholder(tf.float32,[self.batch_size,self.image_size,self.image_size
#真实图像
self.real_images=tf.placeholder(tf.float32,[self.batch_size,self.image_size,self.image_size
#连接
combined_preimage=tf.concat(axus=3,values=[self.line_images,self.color_images])
#生成图像
self.generated_images=self.generator(combined_preimage)
self.real_AB=tf.concat(axus=3,values=[combined_preimage,self.real_images])
self.fake_AB=tf.concat(axus=3,values=[combined_preimage,self.generated_images])
#训练判别器判别器真实图像与条件约束,判别为真
self.disc_true,self.disc_true_logits_=self..discriminator(self.real_AB,reuse=False)
#训练判别器判别器生成图像与条件约束,判别为假
self.disc_fake,self.disc_fake_logits_=self..discriminator(self.fake_AB,reuse=True)
# 判别器给真实图像打高分,给生成图像打低分
self.d_loss_real=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.disc_true_logits
self.d_loss_fake=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.disc_fake_logits
self.d_loss=self.d_loss_real+self.d_loss_fake
# 生成器希望判别器判别自己生成图像的损失
self.g_loss=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.disc_fake_logits
#图像显示在TensorBoard中
self.G_sum=tf.summary.images("generated_images",self.generated_images)
self.D_sum=tf.summary.histogram("g_loss",self.g_loss)
self.g_loss_sum=tf.summary.scalar("g_loss",self.g_loss)
self.d_loss_sum=tf.summary.scalar("d_loss",self.d_loss)
#获得生成器与判别器的变量,使用Adam算法训练
t_vars=tf.trainable_variables()
self.d_vars=[var for var in t_vars if 'd_' in var.name]
self.g_vars=[var for var in t_vars if 'g_' in var.name]
self.d_optim=tf.train.AdamOptimizer(0.0002,beta1=0.5).minimize(self.d_loss,var_list=self.d_vars)
self.g_optim=tf.train.AdamOptimizer(0.0002,beta1=0.51).minimize(self.g_loss,var_list=self.g_vars)
代码中首先定义了3种图像的placeholder,把线条图像与模糊图像连接,然后送人生成器;接着将生成的新图像分别与真实图像和生成图像连接,交给判别器训练。下面就是传统的训练了。
def train(self,config):
if not os.path.exists('./output/results'):
os.mkdirs('./output/results')
self.loadmodel()
data=glob(r'/input/ColorImg/*.jpg')
print(data[0])
base=np.array([get_image(sample_file) for sample_file in data[0:self.batch_size]])
base_normalized=base/255.0
#图像转线图,再用来训练
base_edge=np.array([cv2.adaptiveThreshold(cv2.cvtColor(ba,cv2.COLOR_BGR2GRAY),255
base_edge=np.expand_dims(base_edge,3)
base_color=np.array([self.imgeblur(ba) for ba in base])/255.0
ims("./output/results/base.png",merge_color(base_normalized,[self.batch_size_sqrt,self.batch_size_sqrt])
ims("./output/results/base_line.jpg",merge(base_edged,[self.batch_size_sqrt,self.batch_size_sqrt])
ims("./output/results/base_colors.jpg",merge_color(base_colors,[self.batch_size_sqrt,self.batch_size_sqrt])
self.g_sum=tf.summary.merge([self.G_sum,self.g_loss_sum])
self.d_sum=tf.summary.merge([self.D_sum,self.d_loss_sum])
self.writer=tf.summary,FileWriter("./output/",self.sess.graph)
datalen=len(data)
for e in range(2000):
for i in range(datalen//self.batch_size):
batch_files=self.data[i*self.batch_size:(i+1)*self.batch_size]
#获取真实图像并重塑256x56
batch=np.array([get_image(batch_file) for batch_file in batch_files]
batch_normalized=batch/255.0
#自适应阈值分割,要求输入图像四维
batch_edge=np.array(cv2.adaptiveThreshold(cv2.cvtColor(ba,cv2.COLOR_BGR2GRAY),255
batch_edge=np.expand_dims(batch_edge,3)
batch_colors=np.array([self.imgeblur(ba) for ba in batch])/255.0
summary,d_loss,__=self.sess.run([self.d_sum,self.d_loss,self.d_optim],feed_dict=
self.writer.add_summary(summary,self.counter)
summary,g_loss,__=self.sess.run([self.g_sum,self.g_loss,self.g_optim],feed_dict=
self.writer.add_summary(summary,self.counter)
print("%d: [%d / %d] d_loss %f, g_loss %f,"% (e,i,(datalen//self.batch_size)
if i%100==0:
recreation=self.sess.run(self.generated_images,feed_dict=
ims("./output/results/"+str(e*100000+i)+".jpg",merge_color(recreation
if i%500==0:
self.save("./output/checkpoint",e*100000+i)
4)ColorGAN训练结果:
因为ColorGAN结构比较复杂,非GPU需要花费大量时间,因此需要GPU进行训练。因为其中要用到动漫数据,因此需要提前上传。
使用上面例子,可以将线条图像转成彩色图像,也就是实现了两种风格图像之间的转换。ColorGAN中的结构具有一般性,只需要修改图像预处理部分的代码,就能完成其他图像风格转换任务,比如去除马赛克。实现准备一张没有打马赛克的图像,然后通过软件将图像某个区域打码,即模糊化,原图就是真实图像,打码图像作为约束条件。将全模糊图像与打码图像拼接交由生成器的U形网络处理生成图像,再通过判别器判别生成图像是否真实图像以及是否与打码图像匹配,这就构成了相应的GAN网络。训练这个网络获得的模型就可以对图像去除马赛克了。
2. 实现文字转图像:
通过一个标签或通过一句话作为GAN的约束条件,让CGAN生成与该标签或该语句相关的图像。
1)独热向量:
文字向量化的方式很多,分别用于单个词向量化、单个句子向量化、单个段落向量化,难度逐渐升高。
独热向量是一种将词向量化的最简单方法,假如数据集中共有10个词x1,x2,...,x10,那么独热向量就是创建长度为10的行向量去表示数据集中的词。具体方法,x1在数据集中是第一个词,那么向量的第一个位置置1,其余置0;x2在数据集中是第二个词,那么向量的第二个位置置1,其余置0:
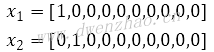
对应向量中只有一个位置会被激活,这就是独热向量表示法。
2)Fashion-mnist数据集:
这里需要使用训练集Fashion-mnist,也称潮流数据集,涵盖10个种类的共7万个不同商品的正面图像,有T恤、长裙、裤子、鞋子等各种物品,该数据集中的图像都是28×28的灰度图像,分别对应着10个类别标签。数据集被分成6万个训练集与1万个测试数据。
3)FashionCGAN判别器和生成器:
首先要将图像读入,将图像标签转为相应的独热向量:
from tensorflow.examples.tutorials.mnist import input_data
fashionmnist=input_data_sets(r''data/fashion-mnist/data/fashion',one_hot=True)
img=fashionmnist.train.images[:10]
train_imf.reshape=img.reshape(len(img),28,28,1)
labels=fashionmnist.train.labels
因为fashion-mnist格式与MNIST完全相同,可以直接使用TensorFlow提供的input_data接口,使用input_data方法传入fashion-mnist数据集所在路径,并将one_hot设置为True,就完成了图像读入与标签向量化。
生成器代码:
def generator(self,z,y,is_training=True,reuse=False):
with tf.variable_scope("generator",reuse=reuse):
z=tf.concat([z,y],1) #合并噪声和标签
net=tf.nn.relu(bn(linear(z,1024,scope='g_fc1'),is_training=is_training,scope='g_bn1'))
net=tf.nn.relu(bn(linear(net,128*7*7,scope='g_fc2'),is_training=is_training,scope='g_bn2'))
net=tf.reshape(net,[self.batch_size,7,7,128])
net=tf.nn.relu(bn(deconv2d(net,[self.batch_size,14,14,64],4,4,2,2,name='g_dc3')
out=tf.nn.sigmoid(deconv2d(net,[self.batch_size,28,28,1],4,4,2,2,name='g_dc4'))
return out
生成器结构简单,一开始通过concat()方法连接噪声矩阵与标签矩阵,让生成器获得约束条件,接着是两个全连接层,全连接层输出数据通过BN处理后传递给ReLU激活函数,然后连着两层转置卷积层。
判别器代码:
def discriminator(self,x,y,is_training=True,reuse=False):
with tf.variable_scope("discriminator",reuse=reuse):
y=tf.reshape(y,[self.batch_size,1,1,self.y_dim])
x=conv_cond_concat(x,y)
net=lrelu(conv2d(x,64,4,4,2,2,name='d_conv1'))
net=lrelu(bn(conv2d(net,128,4,4,2,2,name='d_conv2'),is_training=is_training
net=tf.reshape(net,[self.batch_size,-1])
h2=lrelu(bn(linear(net,1024,scope='d_fc3'),is_training=is_training,scope='d_bn3'))
out_logit=linear(net,1,scope='d_fc4')
out=tf.nn.sigmoid(out_logit)
return out,out_logit,net
判别器代码也简单,开始是连接真实图像数据与条件约束,因为二者维度不同,因此需要对约束条件扩维再连接,使用conv_cond_concat()方法:
def conv_cond_concat(x,y):
x_shapes=x.get_shape()
y_shapes=y.get_shape()
return tf.concat([x,y*tf.ones([x_shapes[0],x_shapes[1],x_shapes[2],y_shapes[3]])],3)
图像数据矩阵与约束条件矩阵连接完成后,就是判别器结构,开头是两个卷积层,随后连接两个全连接层,最后通过sigmoid激活函数输出0~1的分数。
CGAN的网络结构:
def build_model(self):
#图像形状
image_dims=[self.input_height,self.input_width,self.c_dim]
bs=self.batch_size
#图像
self.inputs=tf.placeholder(tf.float32,[bs]+image_dims,name='real_images')
#图像标签
self.y=tf.placeholder(tf.float32,[bs,self.y_dim],name='y')
#噪声
self.z=tf.placeholder(tf.float32,[bs,self.z_dim],name='z')
#生成器
G=self.generator(self.z,self.y,is_training=True,reuse=False)
#判别器
D_real,D_real_logits,_=self.discriminator(self.inputs,self.y,,is_training=True,reuse=False)
D_fake,D_fake_logits,_=self.discriminator(G,self.y,,is_training=True,reuse=False)
d_loss_real=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_real_logits
d_loss_fake=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_fake_logits
#判别器损失
self.d_loss=d_loss_real+d_loss_fake
# 生成器损失
self.g_loss=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_fake_logits
t_vars=tf.trainable_variables()
d_vars=[var for var in t_vars if 'd_' in var.name]
g_vars=[var for var in t_vars if 'g_' in var.name]
with tf.control_dependencier(tf.get_collection(tf.GraphKeys.UPDATE_OPS)):
self.d_optim=tf.train.AdamOptimizer(self.learning_rate,beta1=self.beta1)
self.g_optim=tf.train.AdamOptimizer(self.learning_rate*5,beta1=self.beta1)
#生成样例图像
self.fake_images=self.generator(self.z,self.y,is_training=False,reuse=True)
# 记录到TensorBoard
d_loss_real_sum=tf.summary.scalar("d_loss_real",d_loss_real)
d_loss_fake_sum=tf.summary.scalar("d_loss_fake",d_loss_fake)
d_loss_sum=tf.summary.scalar("d_loss",self.d_loss)
g_loss_sum=tf.summary.scalar("g_loss",self.g_loss)
self.g_sum=tf.summary.merge([d_loss_fake_sum,g_loss_sum])
self.d_sum=tf.summary.merge([d_loss_real_sum,g_loss_sum])
代码中先定义数据,接着通过数据构建生成器和判别器,然后定义二者的损失,定义优化方法,最后通过TensorBoard将必要数据记录下来。
4)训练FashionCGAN:
代码省略。使用CPU就可以训练。
3. 实现句子转图像:
1)word2vec技术:
使用独热向量会形成词汇鸿沟和维度灾难问题。word2vec会训练整个数据集中的数据,训练出每个词的粘稠向量,可以通过欧式距离来计算词汇之间的相似度,这种方法可以获得词汇之间的深层关系。word2vec有两种模型,分别为CBOW(Continuous Bag-of-Words Model)和Skip-Gram(Continuous Skip-Gram Model)模型。CBOW模型通过周围的词来预测中间的词,而Skip-Gram模型是通过中间的词来预测周围的词。这两个模型都可以看作简单的单层神经网络模型。
CBOW模型训练大致步骤:
· 输入周围的词,通过独热向量表示
· 进行映射,即输入词代表的独热向量与权重矩阵W相乘,会从权重矩阵切割一部分
· 连接这些维度,进行简单SUM操作
· 连接后的向量与该层权重矩阵相乘,再经过一个激活函数,传递给softmax转化为概率
· 计算输出的概率向量与真实的中心词对应的独热向量之间的损失
· 通过优化算法最小化这个损失,然后重复
CBOW模型训练中,需要不断调整模型中参数,当模型收敛后,权重矩阵W中的参数就是需要的词向量。这就获取了这个数据集对应的词向量,即模型的权重矩阵。
通过词向量模型,可以预测不同词的近似程度,训练后获得了粘稠的词向量,将这些词向量映射到空间中,就可以看出词与词之间的关系。
Skip-Gram模型是通过中心词来预测周围的词。训练步骤:
· 输入中心词的独热向量表示
· 进行映射,即中心词与权重矩阵W相乘
· 经过一定隐藏层后,计算得出一个向量,通过softmax将数值向量转换为概率向量
· 计算概率向量与真实概率之间的损失,再通过优化算法最小化该损失
这两种模型训练都比较耗时,为了提升训练速度,提出了层次softmax和负例采样。层次softmax利用Huffman编码树算法来编写输出层的向量,当计算某个词时,只需要计算路径上所有的非叶子节点词向量的权重即可,将计算量降低到树的深度;负例采样只需保证出现频次高的词越容易被采样到,然后都数据进行采样即可,大大减少了数据的计算量。
可以通过gensim库来使用word2vec,gensim提供了很多与语言处理相关的算法与工具,包括word2vec。首先需要预处理自己的文本数据集,将文本中的特殊符号和各种噪声去除,然后可以通过下面的代码读入数据集,并利用word2vec进行训练。
from gensim.models import word2vec
sentences=word2vec.LineSentence(u'./zh.wiki')
model=word2vec.Word2Vec(sentences,size=400,window=5,min_count=5,workers=4)
model.save('./WikiModel')
将数据集传入,设置400维权重矩阵,也就是最终训练出的词向量模型的维度;窗口设为5,即一次性向模型输入连续5个词,抽取中间的词作为中心词;使用min_count设置了词汇最少出现次数,如果词汇出现次数少于5次,就认为词可能是错别字或极少使用的词,不进行训练。这里使用的数据是中文维基百科的数据。
Word2vec训练出来的粘稠度词向量之所以可以表示出词与词之间深层关系,是因为人类语言是符合统计分布规律的,某些词经常与另一些词搭配使用,可以通过周围的词描述这个词。通过周围的词来描述中心词也是word2vec思想的精髓。
2)RNN、LSTM与GRU:
虽然句子是由词组合而成的,但如果单纯通过粘稠词向量拼接成句子向量,就无法让模型理解句子与句子之间的差异。不能单纯通过词向量堆叠,还要考虑到构建句子中词的序列。
RNN是一种擅长处理序列数据的网络结构,其还要两个变体LSTM与GRU。
循环神经网络RNN(Recurrent Neural Network)比普通神经网络多了时间维度,它可以利用不同时间节点上的信息来帮助当前节点做判断。RNN的输出值与前面不同时间点的多次输入和多次记忆有关,这种结构赋予RNN的记忆能力。为了获取未来时间点的信息,有了双向RNN。RNN除了在时间维度上的扩展,也可以在空间维度上扩展,堆叠多个隐藏层加深网络结构。
传统的RNN结构上有缺陷,容易出现梯度弥散与梯度爆炸,因此无法记忆较长时间以前的信息。因此提出长短期记忆神经网络LSTM(Long Short-Tern Memory),用闸门机制控制记忆流,选择性忘记某些信息和加深某些信息的记忆,可以避免梯度弥散。因为进行求导时,其梯度是累加的,不会有连乘时遇到的问题。
但LSTM参数太多,训练比较麻烦,为了加快训练速度出现GRU。
3)Skip-Thought Vector:
Skip-Thought是一种通用句子编码器,它通过无监督学习方式训练出一个encoder-decoder,借鉴了word2vec中Skip-Gram模型的思想。这样就可以实现预测这一句话的上一句和下一句话,实现将语义以及语法属性一致或相似的句子映射到相似的向量上,即Skip-Thought方式学习到的句子向量包含了深层的含义。
通常通过模型中的encoder部分作为句子特征提取器,对任意句子进行特征提取并编码,从而获得该句子对应的向量,生成的向量称为Skip-Thought Vector。
Skip-Thought使用GRU来构建模型中的encoder和decoder。当Skip-Thought开始预测句子时,encoder部分会编码输入的句子,并将最后一个词的hidden state作为decoder的输入来生成预测句子中的词,通过利用GRU的结构获取句子的时序特征。
但要编码任意一句话,如果其中某些词在训练Skip-Thought模型时没有出现,就要用到词汇转移训练。可以认为不同语言在各种的语言空间分布是相似的,所以只要训练出一个词汇转移矩阵W,使得输入词汇通过变化后获得一个接近词汇的向量,就实现了不同语言之间的翻译。
利用这种思想,可以通过一个特别大的词汇数据训练出一个词汇模型,然后再与Skip-Thought模型做词汇转移训练,获得一个映射关系。当Skip-Thought遇到训练中未登录的词时,就可以通过打的词汇模型找到该词对应的向量,再通过词汇转移模型映射到Skip-Thought中,这样就可以对未登录的词进行训练了,这种技术为词汇扩展。
4)实现Skip-Thought:
这里通过TensorFlow来实现一个Skip-Thought,先定义encoder与两个decoder,一个decoder用于预测上一句话,一个则用于预测下一句话,都使用GRU实现。训练时定义decoder预测出的语句与真实语句之间的损失,然后通过优化算法最小化这个损失。
TensorFlow中实现GRU很简单:
cell=tf.nn.rnn_cell.GRUCell(num_units=self.num_units)
GRUCell类的构建方法:
@tf_export("nn.rnn.cell.GRUCell")
class GRUCell(LayerRNNCell):
def __init__(self,
num_units,
activative=None,
reuse=None,
kernel_initializer=None,
bias_initializer=None,
name=None,
dtype=None
)
其中参数:
· num_units:隐藏层神经元个数
· activative:激活函数,默认使用Tanh
· reuse:是否重用该空间中的变量
· kernel_initializer:权重矩阵与投影矩阵的初始值
· bias_initializer:偏差的初始值
· name:该层的名称
· dtype:该层的类型
通常只关心GRUCell中的num_units,接着初始化GRU的state并定义GRU的网络运行方式:
inital_state=cell.zero_state(batch_size,tf.float32)
_,final_state=tf.nn.dynamic_rnn(cell,encode_emb,initial_state=inital_state,sequence_length=length)
上面代码中,通过cell.zero_state()方法来获得零填充的张量,然后调用tf.nn.dynamic_rnn方法计算构建好的网络中的各种参数,将cell传入该方法,还传入GRU网络要接收的数据,sequence_length为动态训练的长度。这样,TensorFlow就构建好一个单层的GRU网络,如果要构建多层网络,可以使用tf.nn.rnn_cell.MultiRNNCell()方法。这里只使用单层GRU构建encoder和decoder:
def gru_encoder(self,encode_emb,length,train=True):
batch_size=self.batch_size if train else 1
with tf.variable_scope("encoder"):
cell=tf.nn.rnn_cell.GRUCell(num_units=self.num_units)
#获得零填充张量
initial_state=cell.zero_state(batch_size,tf.float32)
#动态RNN
_,final_state=tf.nn.dynamic_rnn(cell,encode_emb,initial_state
return initial_state,final_state
def gru_decoder(self,decode_emb,length,state,scope,reuse=False):
with tf.variable_scope(scope):
cell=tf.nn.rnn_cell.GRUCell(num_units=self.num_units)
#sequence_length有效长度,避免计算填充的内容
outputs,final_state=tf.nn.dynamic_rnn(cell,decode_emb,initial_state
x=tf.reshape(outputs,[-1,self.num_units])
w,b=self.softmax_variable(self.num_units,len(self.vocab),reuse=reuse)
logits=tf.matmul(x,w)+b
prediction=tf.nn.softmax(logits,name='redictions')
return logits,prediction,final_state
代码中,encoder与decoder结构类似。Encoder中,先通过GRUCell构建GRU网络,再创建零填充张量,用于初始化GRU状态,接着通过dynamic_rnn的方式来计算GRU网络中的参数,返回最后一个节点的状态final_state。Decoder类似,通过GRUCell构建网络,因为decoder的初始值是encoder中最后一个节点的hidden state,即encoder中的final_state,会通过decoder的state参数传入;然后依旧使用dynamic_rnn的方式来计算该GRU网络中的参数,将获得的结果outputs重塑成张量x,再与权重w进行矩阵乘法运算。因为outputs原本是三维张量,而权重w是二维张量,因此需要重塑。最后将计算结果传递给softmax方法,获得最终预测结果,即一个概率向量。
接着可以定义二者的损失了:
def _loss(self.logits,targets,scope='loss'):
with tf.variable_scope(scope):
y_one_hot=tf.one_hot(targets,len(self.vocab))
y_reshaped=tf.reshape(y_one_hot,[-1,len(self.vocab)])
#交叉熵损失
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits
return loss
代码中将目标转为独热向量后,直接将预测的概率向量与独热向量做交叉熵损失的计算,取平均值就得到损失。下面通过优化算法来优化该损失:
def _optimizer(self,loss,scope='optimizer'):
with tf.variable_scope(scope):
grad_clip=5
#获得模型所有参数
tvars=tf.trainable_variables()
#对梯度进行剪枝操作,避免梯度爆炸
grads,_=tf.clip_by_global_norm(tf.gradients(loss,tvars)
op=tf.train.AdamOptimizer(self.learning_rate)
optimizer=op.apply_gradients(zip(grads,tvars))
return optimizer
代码中,使用clip_by_global_norm()方法对梯度剪枝,避免梯度爆炸。该方法背后是Gradient Clipping,具体的效果就是让模型参数更新的幅度限制在一个合适的范围,避免损失发生震荡。具体步骤:
· 设置一个边界值clip_gradient,大于该边界值就需要对梯度进行剪枝处理
· 在反向传播算法计算节点的梯度后,不再直接通过梯度更新节点的参数,而是对所有节点的梯度求平方和global_norm,比较global_norm与clip_norm的大小
· 如果global_norm>clip_norm,则计算缩放因子scale_factor=clip_gradient/sumsq_grandient
· 将所有节点的梯度乘以该缩放因子,得到最终要更新的梯度值,通过该值更新节点参数
clip_by_global_norm()方法原型:
tf.clip_by_global_norm(t_list,clip_norm,use_norm=None,name=None)
其中,t_list是梯度,这里通过tf.gradients()方法对损失与所有节点参数求导,也就是计算出所有节点对应的梯度值;clip_norm是剪枝比率,内部计算逻辑是t_list[i]*clip_norm/max (global_norm,clip_norm),其中global
然后定义优化器,使用Adam算法将梯度更新到节点参数上。因为已经计算出各节点的参数了,直接使用apply
接着通过定义好的结构构建Skip-Thought模型:
def build_model(self):
#输入
self._inputs()
#embedding 映射
self._embedding()
#编码器
self.initial_state,self.final_state=self.gru_encoder(self.encode_emb,self.encode_length)
#解码器,预测前一句
self.pre_logits,self.pre_prediction,self.pre_state=self.gru_decoder(self.decode_pre_emb
#解码器,预测后一句
self.post_logits,self.post_prediction,self.post_state=self.gru_decoder(self.decode_post_emb
#前一句损失
self.pre_loss=self._loss(self.pre_logits,self.decode_pre_y,scope='decoder_pre_loss')
self.pre_loss_sum=scalar_summary("pre_loss",self.pre_loss)
#后一句损失
self.posr_loss=self._loss(self.post_logits,self.decode_post_y,scope='decoder_post_loss')
self.post_loss_sum=scalar_summary("post_loss",self.post_loss)
#对前一句预测与损失进行优化
self.pre_optimizer=self._optimizer(self.pre_loss,scope='decoder_pre_op')
#对后一句预测与损失进行优化
self.post_optimizer=self._optimizer(self.post_loss,scope='decoder_post_op')
首先定义输入,用于获取各种需要的值,接着将输入获得的值进行嵌入运算,然后就可以使用计算获得的值来构建encoder和decoder。Decoder要构建两个,一个用于预测输入语句的前一句,一个用于预测后一句。这两个预测都对应一个损失,所以要定义出两个损失,并记录下来方便训练时观察损失变化。将损失交给优化器进行最小化。
句子数据的读取,可以使用一本书:
· 读入整个文件为一个list,使用固定符合,如“\\”替换常用于句尾的标点符号,然后通过给固定符号来分割整个文件,获得句子数据
· 观察每个句子的出现次数,将出现过于频繁的句子剔除,通常是一些语气用语
· 将剔除后的句子拼接成一个新的list,再分割出每个字,然后将每个字与它在list中的下标构成一个字典,这样一句话就可以替换成一个向量了,句子中的每个字都替换成该字字典中的下标值
· 遍历句子list,获得每个句子的上句与下句,构建映射关系
· 通过embedding获得句子向量对应的映射值,这就是要输入给模型训练的值
其中embedding相关代码:
def _embedding(self):
with tf.variable_scope('embedfing'):
self.embedding=tf.get_variable(name='embedding',shape=[len(self.vocab)
#word2vec中的切割映射
self.encode_emb=tf.nn.embedding_lookup(self.embedding,self.encode
self.decode_pre_emb=tf.nn.embedding_lookup(self.embedding
self.decode_post_emb=tf.nn.embedding_lookup(self.embedding
代码中,self.embedding是要映射的一个矩阵,self.encode是词向量,这个词向量就是通过上面的方法获得的,其形式为[[252,3058,...],[322,426,...]]这样的二维数组,数组中的每个数组都是一句话的向量表示。有了这个向量表示和要映射的矩阵,就可以通过tf.nn.embedding _lookup方法实现映射操作,其实就是获取self.embedding指定的某一行,这样就获得一句话embedding后的向量表示,将这个向量表示输入encoder与decoder就可以进行训练了。
训练代码:
def train(self):
model_path='./output/skipThought.model'
self.builder_model()
#需要在LSTM模型建立后再定义saver
self.saver=tf.train.Saver()
with tf.Session() as sess:
self.writer=SummaryWriter("./output/logs",sess.graph)
self._sum=merge_summary([self.pre_loss_sum,post_loss_sum])
step=0
sess.run(tf.global_variables_initializer())
new_state=sess.run(self.initial_state)
for epoch in range(self.epoch):
#训练数据生成器
batches=self.story.batch()
for encode_x,decode_pre_x,decode_pre_y,decode_post_x,decode_post_y
if len(encode_x)!=self.batch_size:continue
feed={self.initial_state:new_state,self.encode:encode_x
#训练
_,pre_loss,_,_,post_loss,new_state,summary_str=sess.run
print('epoch: ',epoch,' step: ',step,' pre_loss: ',pre_loss
step+=1
self.saver.save(sess,mode_path,global_step=step)
代码中,通过self.story.batch()方法获取了训练文件中各语句的向量表示,encode_x表示当前语句的向量表示,decode_pre_x和decode_pre_y表示前一句的向量表示,decode_post_x和decode_post_y表示后一句的向量表示,,这些都是原始句子的向量表示。其中encode_x、decode_pre_x、decode_post_y会传递给embedding方法做映射,获得句子映射后的向量,这些向量会传递给encoder和decoder,获得预测值,再与没有经过映射操作的向量decode_pre_y、decode_post_y做比较,计算二者的损失值,并最小化该损失。
使用这个模型,编写一个训练模型的方法,用来生成下一句:
def gen(self):
#输入
self._inputs()
#embedding
self._embedding()
#编码器
self.initail_state,self.final_state=self.gru_encoder(self.encode_emb,self.encode_length,train=False)
#后一句decoder
self.post_logits,self.post_prediction,self.post_state=self.gru_decoder(self.decode_post_emb
saver=tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
new_state=sess.run(self.initial_state)
#加载最后一个模型器
#saver.restore(sess,tf.train.latest_checkpoint('.'))
saver.restore(sess,tf.train.latest_checkpoint('./output/'))
#saver.restore(sess,tf.train.latest_checkpoint('/input/skipthoughtmodel/'))
encode_x=[[self.story.word_to_int[c] for c in 'xxxxxxxx']]
samples=[[] for _ in range(self.sample_size)]
samples[0]=encode_x[0]
for i in range(self.sample_size):
decode_x=[[self.story.word_to_int['
while decode_x[0][-1]!=self.story.word_to_int['
feed={self.encode:encode_x
predict,state=sess.run([self.post_prediction,self.post_state]
int_word=np.argmax(predict,1)[-1]
decode_x[0]+=[int_word]
samples[i]+=decode_x[0][1:-1]
encode_x=[samples[i]]
new_state=state
print(''.join([self.story.int_to_word[sample] for sample in samples[i]]))
逻辑不复杂,先创建输入与embedding,接着构建encoder和decoder,encoder的train要设为False,然后是通过saver的restore方法加载此前训练好的模型。定义好encoder要编码的话,然后使用decoder解码,将获得的状态结果存入list中,最后构建出一句话显示出来。
5)实现句子转图像:
使用Skip-Thought模型的encoder就可以将一句话编码成具有意义的句子向量,通过这个句子向量就可以实现句子转图像。
为此,需要准备一个数据集,其中需要有配对的句子与相应的图像,然后可以通过Skip -Thought将所有的句子都编码成向量,将所有的句子向量集合成一个矩阵,然后再持久化保存起来,比如用numpy的saver方法保存为npy文件。将图像数据读入。其本身就是一个矩阵,将多个矩阵集合成高维矩阵,同样持久化保存起来。注意,保存的句子矩阵与图像矩阵之间的对应关系不能改变,这样才能正确训练。
然后可以使用CGAN网络进行训练,生成器使用U形结构还是普通多层转置卷积结构主要看输入的数据,如果使用模型图像作为噪声输入就可以使用U形结构,不然普通的多层转置卷积即可。
可以改进一下判别器,一般是对生成图像与条件约束打低分,还可以加入给真实图像与不匹配的条件约束打低分:
#生成图像
fake_image=self.generator(t_z,t_real_caption)
#真实图像与条件约束
disc_real_image,disc_real_image_logits=self.discriminator(t_real_image,t_real_caption)
#条件约束与不匹配的真实图像
disc_wrong_image,disc_wrong_image_logits=self.discriminator(t_wrong_image
#生成图像与条件约束
disc_fake_image,disc_fake_image_logits=self.discriminator(fake_image
#判别器损失
d_loss1=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits
d_loss2=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits
d_loss3=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits
增加了真实的错误图像wrong_image,获取也简单,随便从图像矩阵中取一个与当前图像不匹配的图像即可。判别器增加一条与条件约束不匹配的情况,可以减少生成器生成错误的相似图像的情况。Github上有一些相关内容。
四、循环一致性:
在GAN网络结构比较复杂时,训练出来的生成器模型生成的图像内容与输入给生成器的图像内容无关,生成器将输入图像完全当噪声处理了。
为了让生成图像与输入图像相关联,可以利用一个预训练好的图像编码器,如通过CNN构建的编码器,此编码器会生成输入图像的特征编码以及生成器生成图像的特征编码,优化这两个特征编码,让二者的损失尽可能小,就实现了输入图像与生成图像的关联。
1. CycleGAN:
可以通过CycleGAN解决生成图像与输入图像无关的问题,其核心思想是循环一致性。
1)CycleGAN的架构与目标函数:
为了让生成图像与输入图像关联,可以使用另外一个生成器,将上一个生成器生成的图像转换回去,最小化输入图像与这个图像之间的损失。多加这样一个结构就可以构成CycleGAN,CycleGAN中有两个生成器和一个判别器。

为了让模型训练更加稳定,CycleGAN做了以下改变:
· 用IN(Instance normalization)替代BN(Batch normalization)
· 目标损失函数使用LSGAN平方差损失替代传统的GAN损失
· 生成器使用残差网络,以更好地保存图像语义
· 使用缓存历史图像来训练生成器,减小训练时的震荡,让模型更稳定
IN只对单张图像中的像素求均值与标准差,更适合生成式任务;BN则是计算一批中所有图像的均值和标准差,在图像、视频的分类任务上更适合。
对于GAN的判别器而言,其实就是在做一个二分类的任务,将输入图像进行打分并分类,传统GAN中判别器的最后一层是sigmoid函数。Sigmoid函数的交叉熵损失很容易达到饱和,即梯度为0,导致该函数容易忽略数据点到决策边界的距离,也就是sigmoid函数不会惩罚离决策边界远的数据点。导致传统GAN中,生成器不再优化那么被判别器判为真实图像的图像,即使这些图像离真实图像还要比较远的距离,这就导致生成器生成的图像质量不高。
使用最小二乘法的方式可以获取图像离决策边界的距离,同时让较远的数据获得与距离成正比的惩罚项。此外,最小二乘的损失函数不容易到达饱和状态。
残差网络其实就是输入数据交由特征提取层获得特征数据后传递给输出层,并且将部分输入数据直接传递给输出层。使用这种结构是为了加强输入数据与输出数据之间的关系。
CycleGAN训练时,不直接使用当前生成器生成的图像,而是使用缓存的历史图像。所谓缓存的历史图像,其实就是此前生成器生成的图像,这可以减小训练时的震荡,让模型更加稳定。因为训练是针对单张图像,所以使用list来存储图像,每次训练判别器时从该list中随机取出一张。
2)TensorFlow实现CycleGAN生成器与判别器:
生成器和判别器中使用IN操作、卷积与转置卷积,先对这些部件进行定义:
def instance_norm(x):
with tf.variable_scope("instance_norm"):
epsilon=1e-5
mean,var=tf.nn.moments(x,[1,2],keep_dims=True)
scale=tf.get_variable('scale',[x.get_shape()[-1]],initializer
offset=tf.get_variable('offset',[x.get_shape()[-1]],initializer
out=scale*tf.div(x-mean,tf.sqrt(var+epsilon))+offset
return out
IN操作是针对单张图像计算均值和方差,然后归一化。卷积层与转置卷积层代码:
def conv(inputconv,o_d=64,f_h=7,f_w=7,s_h=1,s_w=1,stddev=0.02,padding='VALID',name='conv2d'
with tf.variable_scope(name):
conv=tf.contrib.layers.conv2d(inputconv,o_d,f_w,s_w,padding
if do_norm:
conv=instance_norm(conv)
if do_relu:
if(relufactor==0):
conv=tf.nn.relu(conv,'relu')
else:
conv=lrelu(conv,relufactor,'lrelu')
return conv
def deconv(inputconv,outshape,o_d=64,f_h=7,f_w=7,s_h=1,s_w=1,stddev=0.02,padding='VALID'
with tf.variable_scope(name):
conv=tf.contrib.layers.conv2d_transpose(inputconv
if do_norm:
conv=instance_norm(conv)
if do_relu:
if(relufactor==0):
conv=tf.nn.relu(conv,'relu')
else:
conv=lrelu(conv,relufactor,'lrelu')
return conv
在卷积层与转置卷积层代码中,每一层多了两个if控制,一个控制是否进行IN操作,一个控制是否使用激活函数。下面是判别器代码:
def discriminator(inputdisc,name='discriminator'):
with tf.variable_scope(name):
f=4
x=conv(inputdisc,ndf,f,f,2,2,0.02,"SAME","conv_1",do_norm=False
x=conv(x,ndf*2,f,f,2,2,0.02,"SAME","conv_2",relufactor=0.2)
x=conv(x,ndf*4,f,f,2,2,0.02,"SAME","conv_3",relufactor=0.2)
x=conv(x,ndf*8,f,f,1,1,0.02,"SAME","conv_4",relufactor=0.2)
#不使用激活函数,直接返回线性函数LSGAN
x=conv(x,1,f,f,1,1,0.02,"SAME","conv_5",do_norm=False,do_relu=False)
return x
判别器有5个卷积层,结构比较简单,最后一层没有使用激活函数及IN操作,直接返回线性操作后的结果。
生成器结构要复杂一些,因为使用了残差结构。创建残差网络的方法:
def resnet_block(input,dim,name='resnet'):
with tf.variable_scope(name):
out_res=tf.pad(input,[[0,0],[1,1],[1,1],[0,0]],"REFLECT")
out_res=conv(out_res,dim,3,3,1,1,0.02,'VALID','c1')
out_res=tf.pad(out_res,[[0,0],[1,1],[1,1],[0,0]],"REFLECT")
out_res=conv(out_res,dim,3,3,1,1,0.02,'VALID','c2',do_relu=False)
#输入直接传递到输出层
return tf.nn.relu(out_res+input)
代码中使用tf.pad对数据填充,填充形式为REFLECT,然后再用卷积层对填充后的数据进行卷积操作,接着重复一次相同的操作。最后输入数据input与卷积层获取的特征一起传递给输出层。
使用残差网络、卷积层与转置卷积层构建生成器:
def generator(inputgen,dim,name='generator'):
with tf.variable_scope(name):
f=7
ks=3
pad_input=tf.pad(inputgen,[[0,0],[ks,ks],[ks,ks],[0,0]],"REFLECT")
x=conv(pad_input,ngf,f,f,1,1,0.02,name='conv_1')
x=conv(x,ngf*2,ks,ks,2,2,0.02,'SAME',name='conv_2')
x=conv(x,ngf*4,ks,ks,2,2,0.02,'SAME',name='conv_3')
for i in range(1,10):
x=resnet_block(x,ngf*4,'resnet_'+str(i))
x=deconv(x,[batch_size,128,128,ngf*2],ngf*2,ks,ks,2,2,0.02,'SAME','conv_4')
x=deconv(x,[batch_size,256,256,ngf],ngf,ks,ks,2,2,0.02,'SAME','conv_5')
x=conv(x,img_layer,f,f,1,1,0.02,"SAME","conv_6",do_relu=False)
#添加Tanh函数
out_gen=tf.nn.tanh(x,"tanh_1")
return out_gen
代码中先使用3个卷积层对图像信息提取,接着使用9个残差网络,再进一步提取图像信息同时保留输入的数据特征,然后使用2个转置卷积层,最后再连接一个卷积层,获得的图像矩阵经过Tanh函数激活,获得最终的图像输出。生成器的结构类似于U形结构,只是部分层被残差网络替代。
3)TensorFlow搭建并训练CycleGAN:
通过生成器和判别器构建CycleGAN网络:
def build_model(self):
#输入
self.input_A=tf.placeholder(tf,float32,[batch_size,img_width,img_height,img_layer]
self.input_B=tf.placeholder(tf,float32,[batch_size,img_width,img_height,img_layer]
self.fake_pool_A=tf.placeholder(tf,float32,[None,img_width,img_height,img_layer]
self.fake_pool_B=tf.placeholder(tf,float32,[None,img_width,img_height,img_layer]
self.global_step=tf.Variable(0,name="global_step" trainable=False)
self.numl_fake_inputs=0
self.lr=tf.placeholder(tf,float32,shape=[],name="lr")
with tf.variable_scope('Model') as scope:
#A-->B'
self.fake_B=generator(self.input_A,name="g_AB")
#B-->A'
self.fake_A=generator(self.input_B,name="g_BA")
self.rec_A=discriminator(self.input_A,name="d_A")
self.rec_B=discriminator(self.input_B,name="d_B")
scope.reuse_variables() #重用空间变量
self.fake_rec_A=discriminator(self.fake_A,name="d_A")
self.fake_rec_B=discriminator(self.fake_B,name="d_B")
#B'-->A_cyc
self.cyc_A=generator(self.fake_B,name="g_BA")
#A'-->B_cyc
self.cyc_B=generator(self.fake_A,name="g_AB")
scope.reuse_variables() #重用空间变量
#生成图缓存中获取的损失图片
self.fake_pool_rec_A=discriminator(self.fake_pool_A,name="d_A")
self.fake_pool_rec_B=discriminator(self.fake_pool_B,name="d_B")
#循环一致性损失
cyc_loss=tf.reduce_mean(tf.abs(self.input_A-self.cyc_A))+tf.reduce_mean
#生成图像与真实图像之间的损失,使用最小二乘法
self.disc_loss_A=tf.reduce_mean(tf.squared_difference(self.fake_rec_A,1))
self.disc_loss_B=tf.reduce_mean(tf.squared_difference(self.fake_rec_B,1))
#生成器总损失
self.g_loss_A=cyc_loss*10+self.disc_loss_B
self.g_loss_B=cyc_loss*10+self.disc_loss_A
#判别器损失
self.d_loss_A=(tf.reduce_mean(tf.square(self.fake_pool_rec_A,1)))
self.d_loss_B=(tf.reduce_mean(tf.square(self.fake_pool_rec_B,1)))
#优化损失
optimizer=tf.train.AdamOptimizer(self.lr,beta1=0.5)
self.model_vars=tf.trainable_variables()
#所有的变量
d_A_vars=[var for var in self.model_vars if 'd_A' in var.name]
g_A_vars=[var for var in self.model_vars if 'g_A' in var.name]
d_B_vars=[var for var in self.model_vars if 'd_B' in var.name]
g_B_vars=[var for var in self.model_vars if 'g_B' in var.name]
#优化器
self.d_A_trainer=optimizer.minimize(self.d_loss_A,var_list=d_A_vars)
self.d_B_trainer=optimizer.minimize(self.d_loss_B,var_list=d_B_vars)
self.g_A_trainer=optimizer.minimize(self.g_loss_A,var_list=g_A_vars)
self.g_B_trainer=optimizer.minimize(self.g_loss_B,var_list=g_B_vars)
一开始通过placeholder来构建数据输入,Input_A和input_B主要用于获得Domain A与Domain B中图像的输入,而fake_pool_A和fake_pool_B主要用于获取缓存在历史图像库中的不同Domain的历史图像,用它来训练判别器。
接着使用编写好的generator()与discriminator()方法来实例化相应的生成器与判别器。代码中实例化了fake_A、fake_B、cyc_A、cyc_B这4个生成器,fake_A会以Domian B中的图像作为输入获得Domain A风格的生成图像,fake_B则相反;cyc_B会以Domian A中的生成图像作为输入生成Domain B的风格图像,fake_A则相反。即fake_A与cyc_B构成一个循环,fake_B与cyc_A构成一个循环,通过这两个循环,就可以获得相应的循环一致性损失。
对判别器,实例化了rec_A、rec_B、fake_rec_A、fake_rec_B、fake_pool_rec_A、fake_pool_rec_B这6个判别器,rec_A、rec_B用于判别图像是否真实图像,fake
然后要构建相应损失,首先是生成器的损失,由两部分构成,分别是循环一致性损失和生成图像与真实图像之间的损失。分别计算Domain A中真实图像与循环生成图像cyc_A之间的差值,Domain b中真实图像与循环生成图像cyc_B之间的差值,两个损失之和求平均就获得循环一致性损失cyc_loss。生成图像与真实图像之间的损失计算使用最小二乘法,用tf.squared_difference()方法获得fake_rec_A与1之间的平方差及fake_rec_B与1之间的平方差,fake_rec_A和fake_rec_B是接收生成图像fake_A和fake_B的判别器。将这两个损失结合在一起就获得生成器总损失,权重系数表示cyc_loss更重要一些。
判别器的损失也由两部分组成,分别是它对生成图像判别的损失以及它对真实图像判别的损失,但判别器判别的生成图像不一定是当前轮生成器生成的,而是历史缓存中随机获取的。
后面就是优化算法,使用Adam。训练代码流程与前面示例相同,有两层循环,第一层表示要训练多少epoch,第二层表示当前epoch下训练整个数据集需要多少轮。
_,fake_B_temp,summary_str,g_loss_A=sess.run([self.g_A_trainer,self.fake_B
通常而言,都是先固定生成器来训练判别器,但因为判别器需要使用历史缓存图像训练,开始还没有图像,所以先固定判别器来训练生成器,使历史缓存中获得图像。
先训练生成器依旧可以让GAN模型收敛,只是浪费了第一次训练,因为先训练生成器时,判别器没有好的标准,只能随机打分。获得生成的图像后,并不直接交给判别器去训练,而是存入缓存图像库。缓存图像库的相关方法:
def fake_image_pool(self.num_fakes,fake,fake_pool):
if(num_fakes<pool_size):
fake_pool[num_fakes]=fake
return fake
else:
p=random.random()
if p>0.5:
random_id=random.randint(0,pool_size-1)
temp=fake_pool[random_id]
fake_pool[random_id]=fake
return temp
else:
return fake
代码中使用list存储生成器生成的图像,如果list已经存满,就随机计算一个概率,如果概率大于50%,就从缓存中取历史生成图像返回;反之,则直接返回当前生成的图像。在每次训练完生成器获得生成图像后,都调用该方法,将生成图像传入,获得其返回的图像。
fake_B_temp1=self.fake_image_pool(self.num_fake_inputs,fake_B_temp,self.fake_images_B)
然后就可以训练判别器了:
_,summary_str,d_loss_B=sess.run([self.d_B_trainer,self.d_B_loss_sum,self.d_loss_B]
接着以同样方法训练另外的生成器与判别器:,br/>
_,fake_A_temp,summary_str,g_loss_B=sess.run([self.g_B_trainer,self.fake_A,self.g_A_loss_sum
fake_A_temp1=self.fake_image_pool(self.num_fake_inputs,fake_A_temp,self.fake_images_A)
_,summary_str,d_loss_A=sess.run([self.d_A_trainer,self.d_A_loss_sum,self.d_loss_A],feed_dict=
调用训练方法的主程序:
def mian():
model=CycleGAN()
if to_train:
model.train()
elif to_test:
model.test()
if __name__=='__main__':
main()
示例斑马与马相互转换的效果,训练200epoch,每一个epoch循环1000轮。训练前要先把horse2zebra数据集上传,然后加载数据集代码运行。在有GPU平台训练十几个小时就可以达到马转斑马的效果,但斑马转马的效果就不理想,仍然可以看到生成的马有明显条纹。
并可以发现。CycleGAN的生成器可能会故意隐藏信息,即为了从判别器获得高分,将一些图像信息隐藏,让视觉上看不出,但图像中可能依旧存在这样的信息。CycleGAN的生成器模型通过对大量数据训练,在输入图像中没有相关数据情况下,很难生成非常精准的对应图像。
2. StarGAN:
如果需要图像的多域转换,使用CycleGAN实现需要很多生成器,比如实现4个域内图像风格转换就需要12个生成器,不但很麻烦,而且未必有效。
StarGAN就是为了解决多数据集在多域间图像转换的问题。StarGAN可以接收多个不同域的训练数据,并且只需要训练一个生成器,就可以拟合所有可用域中的数据。
1)StarGAN的结构与目标函数:
为了让生成器实现多域图像互相转换,生成器必须接收输入图像以及要转换的目标域两种信息,此时目标域信息就相当于生成器的约束条件。为了避免生成器生成图像与输入图像无关,使用循环一致性损失。StarGAN就是约束条件加循环一致性。
StarGAN中通过类似独热向量的方法来表示不同域或者多个域。因为有标签向量,对于判别器除了要判断图像是否真实,还需要判断该图像是否符合标签向量对应的域中代表的样式。
2)TensorFlow构建StarGAN模型:
为了方便数据读取,单独定义了Image类来管理与训练图像相关的一些方法,使用CelebA作为训练集,这是著名的名人人脸数据库,其他包含10177个名人身份的202599张人脸图像,而且都做好了标记,包括头发颜色、性别等。使用preprocess方法读入数据:
self.lines=open(os.path.join(data_path,'list_attr_celeba.txt'),'r').readlines()
def prepocess(self):
all_attr_names=self.lines[1],split()
for i,attr_name in enumetate(all_attr_names):
self.attr2idx[attr_name]=i
self.idx2attr[i]=attr_name
lines=self.lines[2:]
random.seed(1234)
random.shuffle(lines)
for i,line in enumetate(liness):
split=line.split()
filename=os.path.join(self.data_path,split[0])
values=split[1:]
label=[]
for attr_name in self.selected_attrs:
idx=self.attr2idx[attr_name]
if values[idx]=='1':
label.append(1.0)
else:
label.append(0.0)
#前2000张作为测试数据
if i<2000:
self.test_dataset.append(filename)
self.test_dataset_label.append(label)
else:
self.train_dataset.append(filename)
self.train_dataset_label.append(label)
self.test_dataset_fix_label=create_labels(self.test_dataset_label,self.selected_attrs)
self.train_dataset_fix_label=create_labels(self.train_dataset_label,self.selected_attrs)
print('\n CelebA loading over......')
代码中通过读入的图像标签数据构建了两个字典,接着设置一个种子,通过这个种子将标签数据list打乱。对list做变换,获得图像的具体路径,以及该图像所对应的标签向量。
然后将数据读入,并随机选择图像作为每一次训练的数据:
#训练数据
train_dataset=tf.data.Dataset.from_tensor_slices((Image_data_class.train_dataset
#最终测试数据
test_dataset=tf.data.Dataset.from_tensor_slices((Image_data_class.test_dataset
#最终训练集
train_dataset=train_dataset.apply(shuffle_and_repeat(train_dataset_num)).apply
#最终测试集
test_dataset=test_dataset.apply(shuffle_and_repeat(test_dataset_num)).apply
为了方便从数据源读取数据,使用make_one_hot_interator()方法将数据源转成一个可迭代的数,就可以通过迭代存在来获取数据源中的数据集,例如使用get_next()方法获取数据源中的下一个数据。
train_dataset_iterator=train.dataset.make_one_hot_interator()
test_dataset_iterator=test.dataset.make_one_hot_interator()
self.x_real,label_org,label_fix_list=train_dataset_iterator.get_next()
label_trg=tf.random_shuffle(label_org)
接着编写生成器和判别器。StarGAN的生成器结构与CycleGAN结构类似,由卷积层提取图像特征,接着连接残差网络,然后通过转置卷积来生成相应的矩阵,最后通过一个卷积层将其转成图像。
def generator(self,x_init,c,reuse=False,scope='generator'):
channel=self.ch
c=tf.cast(tf.reshape(c,shape=[-1,1,1,c.shape[-1]]),tf.float32)
c=tf.tile(c,[1,x_init.shape[1],x_init.shape[2],1])
x=tf.concat([x_init,c],axis=-1)
with tf.variable_scope(scope,reuse=reuse):
x=conv(x,channel,kernel=7,stride=1,pad=3,use_bias=False,scope='conv')
x=instance_norm(x,scope='ins_norm')
x=relu(x)
#下采样,图像特征提取
for i in range(2):
x=conv(x,channel*2,kernel=47,stride=2,pad=1,use_bias=False
x=instance_norm(x,scope='down_ins_norm_'+str(i))
x=relu(x)
channel=channel*2
#残差网络
for i in range(self.n_res):
x=resnet_block(x,channel,use_bias=False,scope='resblock_'+str(i))
#上采样,转置卷积
for i in range(2):
x=deconv(x,channel//2,kernel=4,stride=2,use_bias=False
x=instance_norm(x,scope='up_ins_norm_'+str(i))
x=relu(x)
channel=channel//2
x=conv(x,channels=3,kernel=7,stride=1,pad=3,use_bias=False,scope="G_logit")
x=tf.nn.tanh(x)
return x
生成器要生成传入标签向量对应的图像,标签向量就如同一个约束标签。通过tf.concat()方法将标签向量与图像矩阵连接在一起,再交由生成器去生成图像。判别器代码:
def discriminator(self,x_init,reuse=False,scope='discriminator'):
with tf.variable_scope(scope,reuse=reuse):
channel=self.h
x=conv(x_init,channel,kernel=4,stride=2,pad=1,use_bias=True,scope="conv_0")
x=lrelu(x,0.01)
for i in range(1,self.n_dis):
x=conv(x,channel*2,kernel=4,stride=2,pad=1,use_bias=True
x=lrelu(x,0.01)
channel=channel*2
c_kernel=int(self.img_size/np.power(2,self.n_dis))
logit=conv(x,channels=1,kernel=3,stride=1,pad=1,use_bias=False,scope="D_logit")
c=conv(x,channels=self.c_dim,kernel=c_kernel,stride=1,use_bias=False
c=tf.reshape(c,shape[-1,self.c_dim])
return logit,c
判别器的主体结构就是卷积层,除了要判别图像是否真实,还要判别该图像是否符合标签向量的要求。判别器获取图像对应标签的形式很直接,就是通过卷积操作获得标签向量。判别器的输出没有经过激活函数。
然后实例化。
#真实照片+目标域-->生成目标域图像
x_fake=self.generator(self.x_real,label_trg)
#循环生成,生成照片+原始域-->转回原域图像
x_recon=self.generator(x_fake,label_org,reuse=True)
#判别器 输入真实照片-->图像分数以及对应标签
real_logits,real_cls=self.discriminator(self.x_real)
#判别器 输入生成照片-->图像分数以及对应标签
fake_logits,fake_cls=self.discriminator(x_fake,reuse=True)
3)构建StarGAN损失:
使用WGAN-GP方式构建对抗损失。生成器的损失:
g_adv_loss=generator_loss(loss_func=self.gan_type,fake=fake_logit)
g_cls_loss=classification_loss(logit=fake_cls,label=label_trg)
封装了损失计算方法,包括图像与标签。标签损失计算:
def classification_loss(logitls,label):
loss=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(label=label,logits=logit)
return loss
其中,logit是预测的标签向量,label为目标标签向量,计算二者的交叉熵损失并求平均。
循环一致性损失:
g_rec_loss=cyc_loss(self.x_real,x_recon)
def cyc_loss(x,y):
loss=tf.reduce_mean(tf.abs(x-y))
return loss
循环一致性损失,即计算二者的绝对值只差再求平均。最后将三种损失加权相加,得到生成器总损失:
self.g_loss=self.adv_weight*g_adv_loss+self.cls_weight*g_cls_loss+self.rec_weight*g_rec_loss
接着构建判别器损失:
d_adv_loss=discriminator_loss(loss_func=self.gan_type,real=real_logit,fake=fake_logit)+GP
d_cls_loss=classification_loss(logit=real_cls,label=label_org)
self.d_loss=self.adv_weight*d_adv_loss+self.cls_weight*d_cls_loss
构建优化器:
t_vars=tf.trainable_variables()
d_vars=[var for var in t_vars if 'discriminator' in var.name]
g_vars=[var for var in t_vars if 'generator' in var.name]
self.g_optim=tf.train.AdamOptimizer(self.lr,beta1=0.5,beta2=0.999).minimize(self.g_loss,var_list=self.g_vars)
self.d_optim=tf.train.AdamOptimizer(self.lr,beta1=0.5,beta2=0.999).minimize(self.d_loss,var_list=self.d_vars)
接着循环训练StarGAN模型,使用学习速率线性衰变,在模型刚开始训练时学习率比较大,当模型训练较长时间后将学习率减小。
lr=self.init_lr in epoch < self.decay_epoch else self,init_lr*(self.epoch-epoch)/(self.epoch-self.decay_epoch)
接着在循环中训练判别器与生成器,先训练判别器再训练生成器:
#训练判别器
_,d_loss,summary_str=self.sess.run([self.d_optimizer,self.d_loss,self.d_summary_loss]
self.writer.add_summary(summary_str,counter)
#训练生成器
g_loss=None
if (counter-1)%self.n_critic==0:
real_images,fake_images,_,g_loss,summary_str=self.sess.ru([self.x_real
self.writer.add_summary(summary_str,counter)
past_g_loss=g_loss
其中还有很多代码省略了。定义好StarGAN后就可以上传有GPU的平台训练。训练结束后,就可以使用StarGAN对新图像进行多域转换。首先需要加载模型:
def load(self,checkpoint):
import re
print("[*] Reading checkpoints ......")
checkpoint_dir=os.path.join(checkpoint_dir,self.model_dir)
ckpt=tf.train.get_checkpoint_state(checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
ckpt_name=os.path.basename(ckpt.model_checkpoint_path)
self.saver.restore(self.sess,os.path.join((checkpoint_dir,ckpt_name))
counter=int(next(re.finditer("(\d+)(?!.*\d)",ckpt_name)).group(0))
print("[*] Success to read {}".format(ckpt_name))
return True,counter
else:
print("[*] Failed tofind a checkpoint")
return False,0
下面是调用方法,与训练时类似:
self.custom_image=tf.placeholder(tf.float32,[1,self.img_size,self.img_size,self.img_ch]
self.custom_label_fix_list=tf.transpose(create_labels(self.custom_label,self.selected_attr)
self.custom_fake_image=tf.map_fn(lambda x:self.generator(self.custom_image,x,reuse=True)
#加载模型
self.saver=tf.train.Saver()
self.checkpoint_dir=r'/Users/gan/8/model/checkpoint',
could_load,checkpoint_counter=self.load(self.checkpoint_dir)
self.result_dir=os.path.join(self.result_dir,self.model_dir)
check_folder(self.result_dir)
#生成测试图像
for sample_file in test_files:
print("Processing image: "+sample_file)
sample_image=np.asarray(load_test_data(sample_file,size=self.img_size))
image_path=os.path.join(image_folder,'{}'.format(os.path.basename(sample_file)))
fake_image=self.sess.run(self.custom_fake_image,feed_dict
fake_image=np.transpose(fake_image,axes=[1,0,2,3,4])[0]
save_iamges(fake_image,[1,self.c_dim],image_path)
可以看到输出结果。
3. 语义样式不变的图像跨域转换:
前面介绍的CycleGAN与StarGAN的跨域转换在像素级别,无法抽取图像中的高级特征进行跨域,对于差异很大的图像就无法取得理想效果,比如真实人脸与漫画人脸。为此,更关注图像语义样式上的一致性,即输入的真实图像与生成的图像在高维的图像特征上具有相似性。
1)跨域转换网络DTN:
跨域转换网络DTN(Domain Transfer Network)是较早利用GAN的循环一致性思想实现图像跨域转换的模型,思路是降低输入图像语义特征与生成图像语义特征之间的损失。
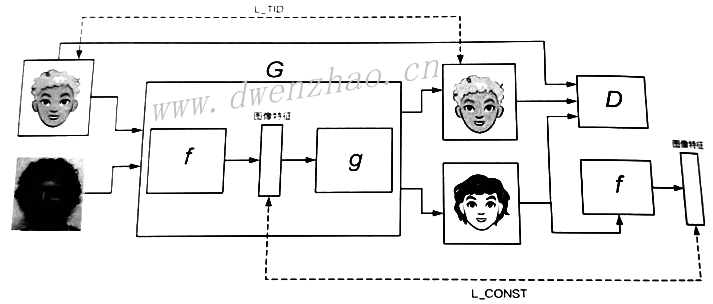
DTN由一个生成器与一个判别器构成。生成器由特征提取器f与图像生成器g构成,当一张图像输入生成器时,特征提取器f会提取输入图像的图像特征,这其实就是图像的语义样式;获得这些特征后,再使用图像生成器g去生成图像,该生成器结构很像U形生成器。
对生成器而言,有两种图像输入,一种是源域图像,即真人人脸,然后生成具有相似语义信息的目标域图像,即漫画人脸。为了确保生成的漫画人脸与真人人脸具有语义相似性,会将生成器生成的漫画人脸再一次交给特征提取器f,让特征提取器提取出来的特征与此前特征提取器的真人人脸特征进行比较,最小化二者损失,这是为了让真实人脸与漫画人脸图像的特征相互匹配。生成器的另一种输入是漫画人脸,然后依旧生成漫画人脸,最小化生成的漫画人脸与输入漫画人脸之间的损失,这是为了让生成器学会漫画人脸的图像特征。
判别器接收3种不同的输入,分别是真实漫画人脸、输入漫画人脸生成的漫画人脸、输入真人人脸生成的漫画人脸,判别器会判断输入的图像是否逼真,逼真则打高分,反之则打低分。
除此之外,为了消除图像复原过程中可能产生的伪影,需要添加全变分,作用是再图像复原和去噪中保持图像的光滑。
2)DTN代码结构:
使用SVHN数据集与MNIST数据集作为DTN训练数据集。SVHN数据集是一个收集于真实世界的门牌号数据集,具有10个类别,其中0表示图像中的门牌号为10,1表示门牌号是1,2表示门牌号是2,依此类推。SVHN数据集中的数据有两种形式,第1种是原始图像,但会有边框将对应标签的门牌号框选出来;第2中类似于MNIST数据集中数据的标签,都是32×32大小放入图像,以相应的门牌号为中心,一些图像中会含有干扰物,这里使用第2种图像。
希望通过DTN实现将SVHN数据集中的图像转成对应的MNIST图像。首先编写生成器与判别器代码,生成器由特征提取器与图像生成器两部分组成,使用转置卷积层构建特征提取器,使用卷积层构建图像生成器,两者合并在一起就是生成器。
def f(self,x,bn=False,activation=tf.nn.relu):
with tf.variable_scope('f',reuse=tf.AUTO_REUSE):
#(batch_size,32,32,3)
x=tf.image.grayscale_to_rgb(x) if x.get_shape()[3]==1 else x
#(batch_size,16,16,64)
x=self.conv_bn(x,64,[3,3],2,'SAME',activation,bn,"conv1")
#(batch_size,8,8,128)
x=self.conv_bn(x,128,[3,3],2,'SAME',activation,bn,"conv2")
#(batch_size,4,4,256)
x=self.conv_bn(x,256,[3,3],2,'SAME',activation,bn,"conv3")
#(batch_size,1,1,128)
x=self.conv_bn(x,128,[4,4],2,'VALID',tf.nn.tanh,bn,"conv4")
return x
def g(self,x,bn=False,activation=tf.nn.relu):
with tf.variable_scope('g',reuse=tf.AUTO_REUSE):
#(batch_size,4,4,512)
x=self.conv_t_bn(x,512,[4,4],2,'VALID',activation,bn,"conv_t1")
#(batch_size,8,8,256)
x=self.conv_t_bn(x,256,[3,3],2,'SAME',activation,bn,"conv_t2")
#(batch_size,16,16,128)
x=self.conv_t_bn(x,128,[3,3],2,'SAME',activation,bn,"conv_t3")
#(batch_size,32,32,1)
x=self.conv_t_bn(x,1,[3,3],2,'VALID',tf.nn.tanh,False,"conv_t4")
return x
def G(self,x):
return self.g(self.f(x))
判别器结构也简单:
def D(self,x,bn=False,activation=tf.nn.relu):v
with tf.variable_scope('D',reuse=tf.AUTO_REUSE):
#(batch_size,16,16,128)
x=self.conv_bn(x,128,[3,3],2,'SAME',activation,bn,"conv1")
#(batch_size,8,8,256)
x=self.conv_bn(x,256,[3,3],2,'SAME',activation,bn,"conv2")
#(batch_size,4,4,512)
x=self.conv_bn(x,512,[3,3],2,'SAME',activation,bn,"conv3")
#(batch_size,1,1,1)
x=self.conv_bn(x,1,[4,4],2,'VALID',tf.identity,False,"conv4")
#将一个张量展平
x=tf.layers.flatten(x)
return x
接着要构建DTN的各种损失,先实例化需要的各种张量:
#源域
f_xs = self.f(self.xs) #源域图像特征
self.g_f_xs = self.g(f_xs) #生成器根据源域图像特征生成的图像
D_g_f_xs = self.D(self.g_f_xs) #判别器给生成图像的判别分数
f_g_f_xs = self.f(self.g_f_xs) #图像特征提取器对生成图像提取的图像特征
#目标域
f_xt = self.f(self.xt)
g_f_xt = self.g(f_xt)
D_g_f_xt = self.D(g_f_xt)
D_xt = self.D(self.xt)
f_g_f_xt = self.f(g_f_xt)
判别器损失:
loss_D_g_f_xs=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits
loss_D_g_f_xt=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits
loss_D_xt=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits
self.loss_D_xs=loss_D_g_f_xs
self.loss_D_xt=loss_D_g_f_xt+loss_D_xt
其中,loss_D_g_f_xs表示判别器给生成器根源源域生成的图像打的分数;loss_D_g_f_xt表示判别器给生成器根据目标域生成的图像打的分数;loss_D_xt表示判别器给输入的真实图像打的分数。最后将源域与目标域的判别器损失分开为两个张量。
生成器的损失比较繁杂,其中的对抗损失:
loss_GANG_D_g_f_xs=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits
loss_GANG_D_g_f_xt=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits
无论根据源域还是目标域,生成器都希望自己生成的图像可以让判别器打高分。
特征循环一致性损失定义:
def d(self.x,y):
return tf.reduce_mean(tf.square(x-y))
loss_CONST_xs=self.d(f_xs,f_g_f_xs)
loss_CONST_xt=self.d(f_xt,f_g_f_xt)
特征的循环一致性损失比较直观,计算输入图像的图像特征与相应的生成图像的图像特征之间的损失,最小化这种损失就可以让源域语义样式与目标域语义样式越来越接近。
定义图像重构损失:
def d2(self,x,y):
return tf.reduce_mean(tf.square(x-y))
loss_TID=self.d2(self.xt,g_f_xt)
图像重构损失也很直观,计算目标域的图像输入以及生成器生成的相应图像之间的损失。最小化该损失可以让生成器更好地学到目标域中的图像特征。
全变分对应的损失:
def tv(self,x):
return tf.reduce_mean(tf.image.total_variation(x))
loss_TV_xs=self.tv(self.g_f_xs)
loss_TV_xt=self.tv(self.g_f_xt)
将上面各种损失相加,就构成生成器损失:
#源域生成器损失
self.loss_G_xs=loss_GANG_d_g_f_xs+a*loss_CONST_xs+c*loss_TV_xs
#目标域生成器损失
self.loss_G_xt=loss_GANG_d_g_f_xt+a*loss_CONST_xt+b*loss_TID+c*loss_TV_xt
其中的a、b、c为权重参数,表示不同损失对生成器的重要程度。然后使用优化算法:
t_vars=tf.trainable_variables()
d_vars=[var for var in t_vars if 'D' in var.name]
g_vars=[var for var in t_vars if 'G' in var.name]
if self.f_adaptation_flag:
g_vars.extend([var for var in t_vars if 'f' in var.name])
with tf.variable_scope('xs',reuse=False):
optimizer_d_xs=tf.train.AdamOptimizer(self.lr)
optimizer_g_xs=tf.train.AdamOptimizer(self.lr)
update_ops=tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
self.train_op_d_xs=optimizer_d_xs.minimize(self.loss_D_xs
self.train_op_g_xs=optimizer_g_xs.minimize(self.loss_G_xs
with tf.variable_scope('xt',reuse=False):
optimizer_d_xt=tf.train.AdamOptimizer(self.lr)
optimizer_g_xt=tf.train.AdamOptimizer(self.lr)
update_ops=tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
self.train_op_d_xt=optimizer_d_xt.minimize(self.loss_D_xt
self.train_op_g_xt=optimizer_g_xt.minimize(self.loss_G_xt
模型训练代码,通过Session对象的run方法来计算此前定义好的生成器损失及判别器损失。
if (batch+1) % self.params["eval_every_num_update"]==0:
op=[self.summary_op_xs,self.loss_D_xs,self.loss_G_xs]
summary_op_xs,loss_D_xs,loss_G_xs=self.sess.run(op,feed_dict)
self.summary.writer.add_summary(summary_op_xs,batch)
self.logger.info("[Source] [%d/%d] d_loss: %.6f, g_loss: %,6f" %
if (batch+1) % self.params["eval_every_num_update"]==1:
op=[self.summary_op_xt,self.loss_D_xt,self.loss_G_xt]
summary_op_xt,loss_D_xt,loss_G_xt=self.sess.run(op,feed_dict)
self.summary.writer.add_summary(summary_op_xt,batch)
self.logger.info("[Target] [%d/%d] d_loss: %.6f, g_loss: %,6f" %
调用前面的优化方法:
if self.flip_gradient_flag:
self.sess.run(self.train_op_all,feed_dict)
else:
for _ in range(self.params["d_update_freq_source"]):
self.sess.run(self.train_op_d_xs,feed_dict)
for _ in range(self.params["g_update_freq_source"]):
self.sess.run(self.train_op_g_xs,feed_dict)
if self.flip_gradient_flag:
self.sess.run(self.train_op_all,feed_dict)
else:
for _ in range(self.params["d_update_freq_target"]):
self.sess.run(self.train_op_d_xt,feed_dict)
for _ in range(self.params["g_update_freq_target"]):
self.sess.run(self.train_op_g_xt,feed_dict)
代码将SVHN数据集中的图像转成对应的MNIST图像。
4. XGAN介绍:
XGAN是2018年Google团队提出的一种语义样式不变的图像跨域转换GAN,其模型结构像一个X。
XGAN是D1域与D2域上的两个自编码器,每个域内分别有一个编码器及一个解码器。

图中e1表示D1域编码器,d1表示D1域解码器,两者构成该域的自编码器,获得D1域中图像的语义特征,对于D2域也类似。模型中,编码器e1与编码器e2最后几层的模型参数是相关联的,这样可以让编码器编码不同的域空间图像时产生有关联的语义特征,而解码器d1和d2最开始几层的模型参数也是相关联的,作用依旧是让两个域可以产生具有关联性的语义特征。
为了加强两个域中图像语义特征的关联,XGAN定义了域对抗性损失Ldann,最小化域对抗损失会将两个域中图像的特征嵌入同一个子空间中,弥合两个域之间语义特征的差异,这样就强化了两个域中图像的语义特征的关联性。
不同域中的图像,依旧通过编码器获得图像的语义特征,然后通过解码器解码图像的语义特征,复原出图像,不同域中的编码器会获得自身域中图像的语义特征,训练出一个类似判别器的二分类模型Cdann,该二分类模型会尽力去判别此时语义空间中的语义特征是由D1域中的e1编码器编码获得的,还是由D2域中的e2编码器编码获得的。即Cdann的目的是分辨出不同语义特征来自哪个域,而e1编码器与e2编码器的目的是降低Cdann分类的准确率。让其分辨不出此时语义特征来自哪个域,这样就实现了编码器e1和e2可以编码出类似语义特征。
为了让两个域的语义特征的内在含义具有关联,需要使用循环一致性思想。D1域的图像先通过编码器e1编码获得语义特征,然后由D2域的解码器d2解码语义特征复原图像,此时再将复原的图像交由编码器e2编码获得语义,最小化复原图像与原始图像的语义特征,就让两个域的语义特征在内在含义上具有关联性。
此外,还有常见的对抗损失,及额外的可选的教师损失。实践证明XGAN有更好地效果。
五、渐进增强式对抗网络:
传统结构的GAN可以简单完成生成图像任务,但这些图像都是64×64或128×128的,如果是更大一些的图像就难以获得理想的效果,因为生成大图像需要学习很多信息,让GAN学习大量信息比较困难,会产生扭曲或虚化等不自然现象。
1. 堆叠式生成对抗网络StackGAN:
StackGAN可以根据一段文本描述生成256×256大小的图像,细分为v1和v2两个版本。
StackGAN由两层构成,第1层主要负责生成64×64的小尺寸的模糊图像,注意力在图像边缘以及整体结构上,然后将第1层生成的具有图像整体结构的模糊图像传递给下一层的生成器,该生成器以上一层的模糊图像为基础进行图像生成,注意力集中在图像细节上,从而实现生成大尺寸图像的目的。StackGAN也是一个Conditional GAN,可以使用一句话作为约束条件,生成器根据语句中的内容生成相应的图像。
StackGAN也不再使用转置卷积,而是使用多个上采样加上卷积核大小为3×3的卷积层构成,这样可以避免棋盘效应。棋盘效应是因为使用转置卷积时卷积核大小与输出窗口的大小不能被步长整除,就会产生重叠部分。避免出现这种问题,就要计算好转置卷积操作时卷积核、输出窗口大小与步长的关系,确保每一层都可以被整除。还有一种方法是使用缩放卷积,就是先通过最近邻差值法或双线性插值法填充图像,然后再通过卷积操作对填充后的图像采样。
StackGAN v2是v1的一种改进,也称为StackGAN++,在三方面进行了优化:
· StackGAN v2不再分层,其中一个生成器采用树状结构,由多个可以生成不同尺寸图像的生成器共同构成,这些生成器对应着一个判别器,实现图像的连贯生成。
· 同时使用条件损失与非条件损失。非条件损失即直接使用噪声与文本编码合并的向量去生成图像,让判别器获得该生成图像的损失,不加条件约束的限制。
· 引入色彩一致性正则项,该正则项可以使生成器在接收到相同输入时生成图像的颜色更加一致。
2. PGGAN:
为了生成高分辨率的大图像,需要使用PGGAN(Progressive Growing of GAN)。PGGAN先训练生成小图像,然后逐渐增加网络结构,从而实现生成高分辨率大图像。PGGAN中,生成器与判别器相当于彼此的镜像结构,两者是同时增长。当有新的层加入原本的生成器与判别器时,除了训练新加入的层,此前旧的层依旧是可以训练的。PGGAN的其他改进:
· 使用平滑过渡的方式训练新加入的层,避免训练时产生模型震荡
· 使用小批量标准差MSD方法来减缓GAN模式崩溃现象
· 采用卷积操作加上采样的方式代替转置卷积,避免棋盘效应
· 采用He Initialization方法来初始化模型中的权重
· 提出Pixel Normalization方法来减缓由生成器与判别器不健康竞争造成的损失信号越界问题
六、GAN进行特征学习:
1. InfoGAN:
互信息就是Y事件带来的信息能消除X事件发生的多大的不确定性。InfoGAN中使用互信息来量化地描述输入的随机量与输出数据之间的关系,目标之一是最大化生成器生成数据与隐含编码之间的互信息,这样就可以通过修改随机变量z中隐含编码的部分来控制生成器生成的数据了。
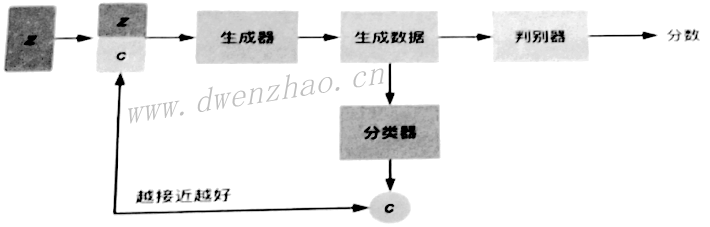
InfoGAN主要由生成器G、分类器Q、判别器D这3个网络结构组成,输入的随机变量z会被分成两部分,一部分依旧是随机变量,另一部分是隐含编码。将这两部分数据传入生成器,生成器获得数据后会生成对应的数据,并交给分类器与判别器。分类器会对生成的数据进行分类,将该数据分类到对应的隐含变量上,而判别器则对生成的数据打分。
为了加快InfoGAN的训练,训练分类器时可以与判别器除最后一层外共享参数,分类器最后一层通过softmax函数实现分类,其他层直接使用判别器中的参数,从而让InfoGAN的计算量与传统GAN相差不多,但却实现了通过隐含编码控制生成数据的效果。
2. VAE-GAN:
VAE-GAN是结合了VAE与GAN的一种结构,VAE是变分自编码器(Variational Auto-Encoder)。自编码器AE主要由两部分构成,分别是编码器和解码器,编码器的作用是将传入的数据压缩,而解码器的作用则是将压缩的数据解码还原成原始图像,通过逐像素比较真实图像与还原图像,可以获得相应的损失,进而通过训练来最小化该损失。自编码器相当于创造了一种新的压缩算法,将原始高维数据中的特征压缩到低维,或者也可以称为新的特征提取算法。通过这种算法,获得原始数据中的关键特征,通过这些特征就可以还原回与真实输入图像类似的图像。
变分自编码器仅在压缩后存储的向量不同,通常的自编码器是一个向量,而变分自编码器是两个向量,一个表示分布的均值。另一个表示分布的标准差,通过这两个向量就可以定义出一个样本空间,而解码器的输入就是从该样本空间中采样得到。
其实单独使用VAE就可以生成图像,但相对来说比较模糊。如果将VAE与GAN结合起来,就形成VAE-GAN。这样为VAE增加一个判别器,判别器就会强迫VAE的解码器生成清晰图像。而给GAN 加上VAE的编码器,为生成器增加一个损失,训练更加稳定。
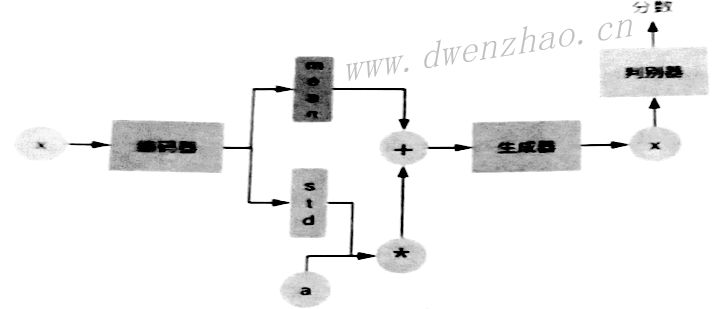
VAE-GAN主要由3部分组成,编码器、生成器(解码器)、判别器。
七、GAN自然语言处理:
自然语言处理也是人工智能研究的一个重要方面,使用GAN可用于生成文本。但文本数据的离散化导致神经网络难以训练,因此需要加以解决。相应方法:
· 判别器直接获取生成器输出
· 使用Gumbel-softmax代替softmax
· 通过强化学习来绕过采样带来的问题
为了避免采样过程导致的模型整体无法训练,最简单的方法就是不采样,将生成器生成的数据直接作为判别器的输入。但这样,生成器生成的数据所在的分布与真实分布之间没有重叠部分,造成输出语句不通顺,意义不明确。
Gumbel-softmax是一个具有采样效果的特殊softmax函数:
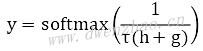
Gumbel分布是一种极值性分布,即取分布中最大的值作为该分布的代表。Gumbel-softmax是在softmax基础上利用Gumbel实现对分布采样的效果。当τ→0,Gumbel-softmax返回的分布等同于one_hot(argmax(softmax(x)));当τ→∞,Gumbel-softmax返回结果等同于均匀分布。
在生成文字的模型中,使用Gumbel-softmax,通常在模型训练时τ赋予较大的值,逐渐将其减小,使其接近于0,达到采样效果。
人在外部环境中,做出适当的事就会获得奖励,而做出不好的事就会受到惩罚。强化学习算法有多种,有基于概率的强化学习算法,也有基于价值的强化学习算法。可以将GAN中判别器作为强化学习的环境,会给与反馈,生成器的目的就是增加判别器反馈的奖励,让奖励最大化。
1. SeqGAN:
SeqGAN是Sequence Generative Adversarial Nets的缩写,是利用GAN+RL方法来实现序列数据的生成。所谓序列数据,就是一组数据中的数据元素其前后顺序是有意义的,文本数据只是序列数据的一种。RL(Reinforcement Learning)表示强化学习。
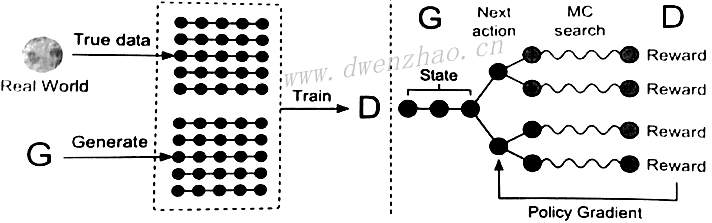
训练判别器时,会使用真实序列数据以及生成器生成的序列数据,此时判别器会分辨获得的序列数据是来自真实世界还是生成器。对于生成器,会尝试生成离散的序列数据,每次训练时都会尝试生成一个词对应的概率分布向量,这个词的概率分布向量会与前面已经生成的词的概率分布向量连接成一个句子。
SeqGAN中采用蒙特卡洛搜索方式,从已有状态推导采样出未来的状态,从而让生成器可以向判别器输出一个完整的句子序列,这种采样策略称为rollout policy。而判别器获得一个完整的序列数据后,会计算出奖励Reword,实现对生成器的指导。
SeqGAN要实现生成逼真序列数据的目的,首先需要从真实世界中获得真实的文本数据,但原始数据需要进行转换,转换成概率分布的形式。通过可以使用RNN、LSTM、GRU等神经网络来将序列数据转换为概率分布形式,具体而言就是一个概率矩阵,其中每一行代表这个句子中的一个词,整个矩阵表示一个完整的句子。
具体实现过程,为了提高SeqGAN中对抗训练的效率,一开始会先对生成器与判别器进行预训练。将真实数据作为输入训练生成器,让生成器生成的数据与真实数据做比较,计算交叉熵损失,相当于在训练一开始就给生成器指明了大致的方向;而判别器的预训练过程就是将此时生成器生成的数据输入判别器,从而让判别器在开始就明白什么数据是生成数据。
SeqGAN中使用卷积神经网络作为判别器D的主体,CNN的应用一般要求处理的对象有局部相关性,而一些序列数据也是具有局部相关性的特征,如文本数据。对于文本分类任务,CNN中的一个卷积核则表示一个关键词或关键短语,卷积核扫描文本数据的过程,其实就是匹配这些关键词或关键短语的过程,CNN相当于在低维向量空间中实现了N元词袋模型N-Gram。
SeqGAN中,判别器使用了CNN机构,并在此基础上增加了Highway Network结构。当深度学习运用一些复杂任务时,需要比较深的网络结构,此时深层网络可能出现梯度消失问题。Highway Network结构的作用类似残差网络,但在实现上受LSTM启发,增加了阀门参数,通过阀门参数来控制多少数据需要经过当前层非线性变化,以及多少数据可以进入Highway直接传递给深层网络结构。
def highway(input_,size,num_layers=1,bias=-2.0,f=tf.nn.relu,scope='Highway'):
with tf.variable_scope(scope):
for idx in range(num_layers):
g=f(linear(input_,size,scope='highway_lin_%d' % idx))
t=tf.sigmoid(linear(input_,size,scope='highway_gate_%d' % idx))
output=t*g+(1.-t)*input_
input_=output
return output
对于浅层浅层神经网络,Highway Network结构对模型整体的收敛没有什么益处,但当神经网络结构变深后,使用Highway Network结构的神经网络就更容易收敛。
2. MaskGAN:
SeqGAN在生成真实文本时效果并不理想,因为容易遇到模型崩溃与难训练的难题。因为每个序列重复出现的概率比较低,GAN难以从中学到足够的信息,导致生成样本多样性不足,出现Mode Collapse模式崩溃。训练时,生成器与判别器能力难以平衡,导致训练不稳定,降低生成文本数据的效果。
MaskGAN不是让生成器直接生成完整的序列数据,而是生成真实序列数据中缺失的部分,已有 的部分不再生成。如,对真实世界中的一个句子,将其中的部分词汇去除,然后交给生成器训练,生成器的目标是将句子中缺失的词汇补充完整,将补充完整的句子再交由判别器判别。这种方法增加了生成器可以获得的信息量,同时降低了其生成任务的难度。这种方式也决定了生成器要使用Seq2Seq网络结构,生成器先接收缺失的序列数据,然后生成补充完整后的序列数据。

MaskGAN使用Actor-Critic,综合基于策略的和基于价值的两种强化学习算法,其中演员Actor会基于概率做出某个动作,而评论家Critic会基于Actor做出的动作给出价值打分。Actor-Critic训练一开始,Actor会随机做出不同的动作,Critic同样也随机评分,而由于奖励的存在,Critic给出的评分越来越准确,从而导致Actor执行的动作越来越好。Actor-Critic引入了基于价值的机制,可以单步更新,不需要等智能体与环境完成一轮交互后再更新网络结构,而是智能体每做一个动作获得反馈后,就可以单步更新网络结构。